Lisää GPU-ohjelmoinnista, Osa 1
Ytimet, säikeet ja säieryhmät
OpenCL/CUDA-sovellus
- OpenCL-sovellus jakautuu
- ytimiin (kernels), jotka suoritetaan OpenCL/CUDA-laitteilla ja
- isäntäohjelmaan (host program), joka suoritetaan isäntälaitteella

- Ydin voi edelleen kutsua erillisiä aliohjelmia OpenCL/CUDA-laitteen puolella
- Isäntäohjelma voi kutsua pelkästään ytimiksi merkattuja oliohjelmia

Globaali indeksiavaruus
- Isäntäohjelman tulee määrittää erityinen indeksiavaruus ennen jokaista ytimen käynnistystä
- Ytimen käynnistyttyä tämä indeksiavaruus määrittelee globaalit indeksinumerot joukolle säikeitä (work-items/threads)

Säieryhmät
- Säikeet jaetaan isäntäohjelman määrittämällä tavalla säieryhmiin (work group/thread block):

- Kukin säieryhmä saa oman säieryhmäindeksinumeronsa
- Tämän lisäksi kukin säie saa oman lokaalin indeksinumeron säieryhmän sisällä
- Indeksointi voi olla yksi-, kaksi- tai kolmiulotteinen
Esimerkki säikeiden indeksoimisesta
- Alla esimerkki tilanteessa, jossa 16 säiettä on jaettu neljään säieryhmään, joissa kussakin on neljä säiettä:
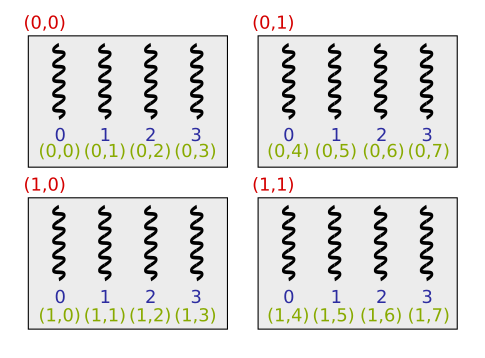
- Oikeasti säikeitä tulisi olla ryhmässä 32 tai 64 moninkerta
Esimerkki OpenCL-ytimestä
- Yksinkertainen OpenCL-ydin kertauksena:
__kernel void add_one(__global int *buffer, int n) {
const int global_id = get_global_id(0);
if(global_id < n)
buffer[global_id]++;
}__kernel-avainsana tekee aliohjelmasta ytimen; muuten kyseessä on normaali OpenCL-laitteen puoleinen aliohjelma, jota voidaan kutsua ytimestä tai toisesta OpenCL-laitteen puoleisesta aliohjelmastaint get_global_id(int)-aliohjelma palauttaa säikeen globaalin indeksinumeron
Esimerkki CUDA-ytimestä
- Yksinkertainen CUDA-ydin kertauksena:
__global__ void add_one(int *buffer, int n) {
const int global_id = blockIdx.x * blockDim.x + threadIdx.x;
if(global_id < n)
buffer[global_id]++;
}__global__-avainsana tekee aliohjelmasta ytimen__device__-avainsana tekisi aliohjelmasta puhtaan CUDA-aliohjelman, jota voidaan kutsua pelkästään ytimestä tai toisesta CUDA-aliohjelmasta- Indeksointi:
- blockIdx.x = Säieryhmän indeksinumero dimensiossa x
- blockDim.x = Säieryhmän koko dimensiossa x
- threadIdx.x = Säikeen lokaali indeksinumero dimensiossa x
Säikeiden suorituspolut
- Ytimen
add_onesuorittamat säikeet voidat seurata kahta eri suorituspolkua:

- Ohjelmakoodissa oletetaan, että globaali indeksiavaruus on suurempi kuin taulukko
buff - Tällöin ydin ei sisällä silmukaa ja
if(global_id < n)-ehtolause takaa sen, että ylimääräiset ytimet eivät aiheuta puskurin ylivuotoa:

Indeksien hallinta (OpenCL)
| Aliohjelma | Selitys |
|---|---|
| uint get_work_dim () | Globaalin avaruuden dimensio |
| size_t get_global_size (uint D) | Globaalin avaruuden koko / säikeiden kokonaismäärä |
| size_t get_global_id (uint D) | Säikeen globaali indeksinumero |
| size_t get_local_size (uint D) | Lokaalin avaruuden koko / Säieryhmän koko |
| size_t get_local_id (uint D) | Säikeen lokaali indeksinumero |
| size_t get_num_groups (uint D) | Säieryhmien määrä |
| size_t get_group_id (uint D) | Säieryhmän indeksinumero |

- Esimerkki:
const int local_id = get_local_id(0);
const int local_size = get_local_size(0);
const int idx = get_group_id(0);
const int jdx = get_group_id(1);
for(int i = local_id; i < N; i += local_size)
...
// Säikeet laskevat yhdessä muuttujaan value jotain...
// Vain säieryhmän ensimmäinen säie tallentaa lopullisen tuloksen
if(local_id == 0)
A[idx*N+jdx] = value;Indeksien hallinta (CUDA)
| Muuttuja | Selitys |
|---|---|
| dim3 gridDim | Säieryhmien määrä |
| dim3 blockDim | Säieryhmän koko |
| uint3 blockIdx | Säieryhmän indeksinumero |
| uint3 threadIdx | Säikeen lokaali indeksinumero |

- Esimerkki:
const int local_id = threadIdx.x;
const int local_size = blockDim.x;
const int idx = blockIdx.x;
const int jdx = blockIdx.y;
for(int i = local_id; i < N; i += local_size)
...
// Säikeet laskevat yhdessä muuttujaan value jotain...
// Vain säieryhmän ensimmäinen säie tallentaa lopullisen tuloksen
if(local_id == 0)
A[idx*N+jdx] = value;Säieryhmät ja osatehtävät
- Säikeiden jakaminen säieryhmiin ohjaa ohjelmoijan pilkkomaan tehtävän osatehtäviin, joka voidaan ratkaista toisistaan riippumattomasti rinnakkain:

Säikeiden ja säieryhmien suoritusjärjestys
- Säieryhmien ja säikeiden suoritusjärjestystä ei ole määritelty
- Ohjelmoijalla ei ole mahdollisuutta vaikuttaa säieryhmien käytökseen
- Ohjelmoija voi kuitenkin käyttää esteitä ytimen suorituksen synkroimiseen säieryhmätasolla:

Säikeiden välinen kommunikointi
- Säieryhmät eivät voi kommunikoida keskenään ytimen suorituksen aikana
- Samaan säieryhmään kuuluvat säikeet voivat kommunikoida keskenään esimerkiksi lokaalin/jaetun muistin kautta
- Ytimet, jotka vaativat globaalia kommunikointia täytyy jakaa useampaan ytimeen. Ytimen käynnistys toimii siis globaalina synkronointipisteenä.
Säieryhmät ja laskentayksiköt
- GPU sisältää yhden tai useamman laskentayksikön (computing unit/streaming multiprocessor) ja yksittäinen laskentayksikkö sisältää yhden tai useamman prosessointielementin (processing element/CUDA core)
- Tyypillisesti yksi laskentayksikkö on vastuussa säeryhmän suorittamisesta ja yksi laskentayksikkö voi suorittaa useampaa säieryhmää

- Vain ajonaikaisen järjestelmän tulee tietää GPU:n todellinen rakenne:

Muistimalli
- Yksittäisellä säikeellä on käytettävissään neljä erilaista muistialuetta:

Globaali muisti (__global / __device__)
- Globaali muisti (global memory/device memory) on muistialue, johon jokaisella säikeellä on luku- ja kirjoitusoikeus riippumatta siitä mihin säieryhmään ne kuuluvat:

- Suurin osa videomuistista on käytettävissä globaalin muistin muodossa
- Globaali muisti on useimmassa tapauksissa toteutettu näytönohjainpiirin ulkopuolella, joten muistikaista on rajoitettu ja muistin käyttämiseen liittyvät latenssiajat ovat satojen kellojaksojen luokkaa
- Modernien näytönohjaimien tapauksessa globaalia muistia käytetään välimuistin kautta
Globaali muisti OpenCL:ssä
- Globaalia ja vakiomuistia hallitaan OpenCL:ssä
cl::Buffer-luokan avulla:
cl::Buffer::Buffer(
const Context& context,
cl_mem_flags flags,
::size_t size,
void * host_ptr = NULL,
cl_int * err = NULL) - Lippu (
flags)CL_MEM_READ_WRITEvaraa read-write muistialueen - Mikäli
host_ptr != 0ja lippuCL_MEM_COPY_HOST_PTRon asetettu,host_ptr-osoittimen osoittava data siirretään GPU:n muistiin automaattisesti - Muita mielenkiintoisia lippuja:
CL_MEM_USE_HOST_PTR,CL_MEM_ALLOC_HOST_PTR,CL_MEM_HOST_WRITE_ONLY,CL_MEM_HOST_READ_ONLYjaCL_MEM_HOST_NO_ACCESS
Globaali muisti CUDA:ssa
- Globaali muistipurkuri voidaan varata CUDA:ssa
cudaMalloc-aliohjelmalla:
cudaError_t cudaMalloc(
void ** devPtr,
size_t size);- Kaksiulotteinen N \(\times\) M -taulukko voidaan varata tehokkaasti
cudaMallocPitch-aliohjelmalla:
cudaError_t cudaMallocPitch(
void **devPtr,
size_t *pitch,
size_t M,
size_t N);- Tällöin taulukon
Aelementit saadaan käyttöön seuraavalla tavalla:
int elem1 = *((int*)((char*)A + 3 * pitch) + 5); // "=" A[3][5]
int *line = (int*)((char*)A + 7 * pitch); // 7. rivi
int elem2 = line[14]; // "=" A[7][14]- Kolmiulotteinen taulukko voidaan puolestaan varata tehokkaasti
cudaMalloc3D-aliohjelmalla - Varattu muisti vapautetaan
cudaFree-aliohjelmalla
cudaError_t cudaFree(void *devPtr); - CUDA-kirjasto tarjoaa myöskin
cudaMallocHostjacudaFreeHostaliohjelmat ns. page-locked / pinned muistin varaamiseen isäntälaitteen puolella. Tämä tekee muistisiirroista nopeampia, mutta suurien taulukoiden vaaraaminen saattaa epäonnistua tai vaikuttaa negatiivisella tavalla laitteiston yleiseen suorituskykyyn.
Globaalin muuttujat
- CUDA tukee myöskin globaaleja muuttujia:
__device__ double devData; // CUDA-laitteelle näkyvä globaali muuttuja
__device__ double* devPointer; // CUDA-laitteelle näkyvä globaali osoitin- Globaalien muuttujien arvot asetetaan isäntäohjelman puolella:
double hostData = 6.0;
cudaMemcpyToSymbol(devData, &hostData, sizeof(double));
double* hostPointer;
cudaMalloc(&hostPointer, 256*sizeof(double));
cudaMemcpyToSymbol(devPointer, &hostPointer, sizeof(hostPointer));
Lokaali muisti (__local / __shared__ )
- Lokaali muisti (local memory) on muistialue, joka näkyy pelkästään saman säieryhmän säikeille:

- Lokaalia muistia käytetään tyypillisesti tilanteissa, joissa samaan säieryhmään kuuluvat säikeet haluavat jakaa dataa keskenään
- Moderneissa näytönohjaimissa lokaali muisti on totetettu osana näytönohjainpiiriä (tyypillisesti jokaisella laskentayksiköllä on oma lokaali muisti), joten lokaali muisti on noin kertaluokkaa nopeampi kuin globaali muisti
- CUDA-terminologiassa lokaalia muistia nimitetään jaetuksi muistiksi (shared memory)
Lokaali muisti OpenCL:ssä
- Lokaali muistipuskuri voidaan varata staattisesti ytimen sisällä:
__kernel void ydin(...) {
__local float buff[256];
const int local_id = get_local_id(0);
buff[local_id] = local_id;
...
}- Muistialue voidaan varata myöskin dynaamisesti ytimen käynnistyksen yhteydessä:
ydin.setArg(0, cl::Local(256*sizeof(float));
queue.enqueueNDRangeKernel(ydin, ...);- Tai vaihtoehtoisesti funktoreita käyttäen:
typedef cl::make_kernel<cl::LocalSpaceArg, ...> createKernel;
typedef std::function<createKernel::type_> KernelType;
KernelType ydin = makeKernel(...);
ydin(EnqueueArgs(...), cl::Local(256*sizeof(float), ...);- Dynaamisesti varattu lokaali muistipuskuri välitetään siis argumenttina:
__kernel void ydin(__local float *buff, ...) {
const int local_id = get_local_id(0);
buff[local_id] = local_id;
...
}Lokaali muisti CUDA:ssa
- Lokaali muistipuskuri voidaan varata staattisesti ytimen sisällä:
__global__ void ydin(...) {
__shared__ float buff[256];
const int local_id = threadIdx.x;
buff[local_id] = local_id;
...
}- Muistialue voidaan varata myöskin dynaamisesti ytimen käynnistyksen yhteydessä:
ydin<<<WG_COUNT, LOCAL_SIZE, 256*sizeof(float)>>>(...);- Dynaamisesti varattu lokaali muistipuskuri välitetään ytimelle ulkoisena (
extern) muuttujana:
__global__ void ydin(...) {
extern __shared__ float buff[];
const int local_id = threadIdx.x;
buff[local_id] = local_id;
...
}Muistipankkien leveyden asettaminen
- Jotkin Nvidian GPU:t (esim. CC 3.x) toimivat tehokkaammin silloin kun lokaalin muistin ns. pankkien leveys on säädetty kohdalleen
cudaDeviceSetSharedMemConfig-aliohjelmalla:
cudaError_t cudaDeviceSetSharedMemConfig(cudaSharedMemConfig config);- Argumentti
cudaSharedMemBankSizeFourByteasettaa pankkien leveydeksi 4 tavua (float) - Argumentti
cudaSharedMemBankSizeEightByteasettaa pankkien leveydeksi 8 tavua (double) - Aliohjelmaa kutsutaan ennen ytimen asettamista komentojonoon
Vakiomuisti (__constant / __constant__)
- Vakiomuisti (constant memory) on kaikille säikeille näkyvä muistialue, jonka sisältö pysyy samana ytimen suorituksen ajan
- Vakiomuistia on käytössä vain rajoitettu määrä, mutta se on nopeampaa kuin globaali muisti

Vakiomuisti OpenCL:ssä
- Isäntäohjelma voi varata vakiomuistia antamalla
cl::Buffer-luokan muodostinfunktiolleCL_MEM_READ_ONLY-lipun - Varattu puskuri-objekti välitetään ytimelle normaalisti, mutta määritellään
__constant-avainsanalla argumentin yhteydessä:
__kernel void ydin(__constant float *buff, ...) {
const int local_id = get_local_id(0);
float a = buff[local_id]; // OK
buff[local_id] = 7.0; // Virhe
}Vakiomuisti CUDA:ssa
- CUDA:ssa vakiomuistialue määritellään globaalisti ytimen lähdekoodin ulkopuolella:
__constant__ float buff[256];
__global__ void ydin(...) {
const int local_id = threadIdx.x;
float a = buff[local_id]; // OK
buff[local_id] = 7.0; // Virhe
}- Isäntäohjelma näkee
buff-taulukon symbolina, johon voidaan siirtää dataacudaMemcpyToSymbol-aliohjelmalla:
cudaError_t cudaMemcpyToSymbol(
const char *symbol,
const void *src,
size_t count,
size_t offset = 0,
enum cudaMemcpyKind kind = cudaMemcpyHostToDevice); - Esimerkki:
__constant__ float buff[256];
float data[256];
// Täytetään data-taulukko tässä välissä
cudaMemcpyToSymbol (buff, data, 256*sizeof(float));- Vaihtoehtoisesti voidaan myös käyttää
cudaMemcpyToSymbolAsync-aliohjelmaa
Yksityinen muisti (__private)
- Yksityinen muisti (private memory) on muistialue, joka näkyy pelkästään yksittäiselle säikeelle:

- Kääntäjä saattaa tallentaa dataa yksityiseen muistiin tilanteissa, joissa laskentayksikön resurssit ovat vähissä
- Toteutettu tyypillisesti osana videomuistia, joten yksityisen muistin eksplisiittinen käyttäminen ei ole suositeltavaa
Relaksoitu konsistenssi (relaxed consistency)
- OpenCL:n muistimalli on konsistentti yksittäisen säikeen näkökulmasta
- Tässä yhteydessä konsistentti tarkoittaa mm. sitä, että muistioperaatiot tapahtuvat ennalta määrätyssä järjestyksessä
- OpenCL:n muistimalli ei ole konsistentti eri säikeiden välillä
- Tämä tarkoittaa mm. sitä, että eri säikeiden tekemien muistioperaatioiden suoritusjärjestystä ei ole määritelty
- Muistin saattaminen konsistenttiin tilaan onnistuu joissakin tilanteissa, mutta vaatii erityisen synkronointikomennon
Komentojono
- Muistisiirrot, ytimien käynnistykset ja muut vastaavat operaatiot asetetaan komentojonoon
- Jokaisella GPU:lla on oma oletuskomentojono tai komentojono täytyy luoda erikseen
- Yhdellä GPU:lla voi myöskin olla monta komentojonoa
- Ajonaikainen järjestelmä suorittaa komentojonoon asetetut komennot itsenäisesti
- Isäntäohjelma palaa komentojonoon liittyvistä aliohjelmasta välittömästi eli kyseessä on ns. non-blocking -operaatio
- Jotkin toiminnot voidaan myös suorittaa ns. blocking-versiona eli isäntäohjelma odottaa komennon suorituksen loppuun
- Isäntäohjelma ja GPU voivat synkronoida suorituksensa esimerkiksi esteen avulla

Komentojonon luominen OpenCL:ssä
- Komentojono on kapseloitu
cl::CommandQueue-luokan sisälle, jonka muodostinfunktio ottaa argumenttinaan OpenCL-kontekstin ja OpenCL-laitteen, joihin komentojono on tarkoitus liittää:
cl::CommandQueue::CommandQueue(
const Context& context,
const Device& device,
cl_command_queue_properties properties = 0,
cl_int * err = NULL) Datasiirrot OpenCL:ssä
- Komentojonon
enqueueWriteBuffer-jäsenfunktio asetaa komentojonoon käskyn kirjoittaa dataa isäntälaiteen muistista Puskuri-objektiin blocking_write-lipun asettaminen arvoonCL_TRUEtekee kutsusta blockaavan eli aliohjelmasta palataan vasta kun siirto on suoritettu loppuun
cl_int cl::CommandQueue::enqueueWriteBuffer(
const Buffer& buffer,
cl_bool blocking_write,
::size_t offset,
::size_t size,
const void * ptr,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL) - Komentojonon
enqueueReadBuffer-jäsenfunktio asetaa komentojonoon käskyn lukea dataa Puskuri-objektista isäntälaiteen muistiin blocking_read-lipun asettaminen arvoonCL_TRUEtekee kutsusta blockaavan eli aliohjelmasta palataan vasta kun siirto on suoritettu loppuun
cl_int cl::CommandQueue::enqueueReadBuffer(
const Buffer& buffer,
cl_bool blocking_read,
::size_t offset,
::size_t size,
const void * ptr,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL) Ytimen asettaminen jonoon OpenCL:ssä
- C++ -kääreessä ydin-objekti on kapseloitu
cl::Kernel-luokan sisälle, jonka muodostinfunktio ottaa argumenttinaan Ohjelma-objektin ja ytimen nimen:
cl::Kernel::Kernel(const Program& program,
const char * name,
cl_int * err = NULL) - Ytimen argumentit asetataan yksitellen
setArg-jäsenfunktiolla:
template <typename T>
cl_int cl::Kernel::setArg(cl_uint index, T value)- Ytimen käynnistyskäsky asetetaan komentojonoon
enqueueNDRangeKernel-jäsenfunktiolla:
cl_int cl::CommandQueue::enqueueNDRangeKernel(
const Kernel& kernel,
const NDRange& offset,
const NDRange& global,
const NDRange& local,
const VECTOR_CLASS<Event> * events = NULL,
Event * event = NULL)- Globaalin indeksiavaruuden koko asetetaan
global-argumentilla ja säieryhmän koko vastaavastilocal-argumentilla
Funktorit
- C++11:stasen funktorit tarjoavat huomattavasti mukavamman tavan hallita ytimiä
- Yleisimmässä tapauksessa määrittelemme ensin uuden aliohjelman:
typedef cl::make_kernel<...> createKernel;- Ytimen argumenttien tyypit (cl::Buffer&, double, int) tulevat
<>-sulkujen sisälle - Vapaasti nimettävän
createKernel-aliohjelman (itseasiassa kyseessä on olion) avulla voidaan luoda ydin-objekteja, joiden argumenttilista vastaa<>-sulkujen sisään annettua listaa
- Uuden tyyppinen ydin-objekti määritellään seuraavasti:
typedef std::function<createKernel::type_> KernelType;- Vapaasti nimettävä
KernelType-tyyppi voi viitata ydin-objektiin, jonka argumenttilista vastaacreateKernel-aliohjelman määrittelyn yhteydessä annettua argumenttilistaa - Ydin voidaan nyt luoda
createKernel-aliohjelmalla:
KernelType ydin = createKernel(program, "ytimen_nimi");- Ydintä voidaan nyt kutsua melkein kuin normaalia aliohjelmaa:
kernel(
cl::EnqueueArgs(
queue,
cl::NDRange(GLOBAL_SIZE_0, GLOBAL_SIZE_1, GLOBAL_SIZE_2),
cl::NDRange(LOCAL_SIZE_0, LOCAL_SIZE_1, LOCAL_SIZE_2)),
...);- Ytimen argumentit tulevat
cl::EnqueueArgs-olion jälkeen
- Esimerkki:
typedef cl::make_kernel<cl::Buffer&, int> createAddOneKernel;
typedef std::function<createAddOneKernel::type_> AddOneKernelType;
AddOneKernelType kernel = createAddOneKernel(program, "add_one");
kernel(
cl::EnqueueArgs(
queue, cl::NDRange((N/256+1)*256), cl::NDRange(256)),
deviceBuffer, N);Komentojonon luominen CUDA:ssa
- CUDA:ssa jokaisella CUDA-laitteella on oma oletuskomentojono, jota käytetään silloin kun komentojonoa ei ole määritelty
- CUDA-laitteen vaihtaminen
cudaSetDevicevaihtaa käytössä olevan oletuskomentojonon - Komentojono voidaan myöskin luoda erikseen
cudaStreamCreate-aliohjelmalla:
cudaStream_t queue;
err = cudaStreamCreate(&queue);- Komentojono tuhotaan vastaavasti
cudaStreamDestroy-aliohjelmalla:
err = cudaStreamDestroy(queue);Datasiirrot CUDA:ssa
- Blockkaava datasiirto käynnistetään
cudaMemcpy-aliohjelmalla:
cudaError_t cudaMemcpy(
void *destination, // Kohdepuskuri
const void *source, // Lähdepuskuri
size_t count, // Siirron koko tavuina
enum cudaMemcpyKind kind); // Siirron tyyppi- Sallitut arvot
kind-argumentille ovat:cudaMemcpyHostToHostcudaMemcpyHostToDevicecudaMemcpyDeviceToHostcudaMemcpyDeviceToDevice
- Ei-blockkaava datasiirto tehdään
cudaMemcpyAsync-aliohjelmalla:
cudaError_t cudaMemcpyAsync(
void *destination,
const void *source,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
) - Käytettävä komentojono annetaan
stream-argumentilla - Oletuksena käytetään CUDA-laitteen oletuskomentojonoa
- Mikäli
cudaMemcpyAsync-aliohjelmalle annetaan argumenttina isäntälaitteen muistissa sijaitseva puskuri, täytyy tämän puskurin olla ns. page-locked / pinned - Käytännössä tämä tarkoittaa sitä, että käyttöjärjestelmä lupaa pitää puskurin fyysisessä RAM-muistissa DMA-ohjaimen tekemää asynkronistä siirtoa varten
- Page-locked muistia voidaan varata
cudaMallocHost-aliohjelmalla:
cudaError_t cudaMallocHost(void **ptr, size_t size); - Page-locked muisti vapautetaan
cudaFreeHost-aliohjelmalla:
cudaError_t cudaFreeHost(void *ptr); Ytimen asettaminen jonoon CUDA:ssa
- Ytimen käynnistys CUDA:ssa
kernel<<<gridSize, blockSize, localSize, queue>>>(args)gridSizemäärittää säieryhmien määrän. Voi olla luku taidim3blockSizemäärittää säieryhmän koon. Voi olla luku taidim3localSizemäärittää dynaamisesti varattavan lokaalin muistin määrän tavuinaqueuemäärittää käytettävän komentojononargsmäärittää ytimen argumentit
Varoitus ei-blockkaaviin datasiirtoihin liittyen
- Ajonaikainen järjestelmä takaa sen, että ydintä ei lähdetä suorittamaan ennen kuin sitä jonossa edeltävät komennot on suoritettu loppuun
- Ei-blockkaava datasiirto on siis turvallista ytimen näkökulmasta
- Isäntäohjelman puolella täytyy kuitenkin muistaa, että data siirretään asynkronisesti!
- Isäntäohjelman tulee käyttää blockkaavia siirtoja tai synkronoida suorituksensa GPU:n kanssa ennen kuin se voi turvallisesti käyttää datasiirtoon liittynyttä puskuria!
- Esimerkiksi seuraavaa tilanteen lopputulos on määrittelemätön:
// Aloitetaan ei-blockkaava siirto hostBuffer -> deviceBuffer
cudaMemcpyAsync(
deviceBuffer, hostBuffer, N*sizeof(int), cudaMemcpyHostToDevice);
for(int i = 0; i < N; i++)
hostBuffer[i] = i; // hostBufferin i:nes alkio saattaa olla siirretty
// GPU:n muistiin ennen tämän rivin suoritusta tai se
// saatetaan siirtää GPU:n muistiin vasta myöhemmin- Samanlainen tilanne tapahtuu myöskin tässä:
cudaMemcpyAsync(
hostBuffer, deviceBuffer, N*sizeof(int), cudaMemcpyDeviceToHost);
for(int i = 0; i < N; i++)
cout << hostBuffer[i] << endl; // Saattaa tulostaa deviceBufferin i:dennen
// alkion tai jotain muuta
Komentojonon synkronointi
- Isäntäohjelma voi synkronoida suorituksensa OpenCL komentojonon kanssa seuraavasti:
queue.finish(); // Aliohjelmasta palataan vasta kun kaikki komentojonossa olleen
// komennot on suoritettu loppuun- CUDA:ssa sama onnistuu seuraavasti:
cudaStreamSynchronize(queue);- Vaihtoehtoisesti isäntäohjelma voi odottaa kunnes aktiivinen CUDA-laite on suorittanut kaikki sille annetut tehtävät:
cudaDeviceSynchronize();Virheenkäsittelystä
- OpenCL:lässä virhetilanteet voi käsitellä
cl_int-tyyppisellä virhemuuttujalla tai poikkeuksien avulla (#define __CL_ENABLE_EXCEPTIONS) - Useimman CUDA:n aliohjelmat palauttavat
cudaError_t-tyyppisen virhemuuttujan - Ytimen asettaminen komentojonoon ei palauta virhekoodia CUDA:ssa vaan virhekoodi pitää kysyä erikseen:
cudaError_t cudaGetLastError(void)palauttaa edellisen komennon virhekoodin ja resetoi sen arvooncudaSuccesscudaError_t cudaPeekAtLastError(void)palauttaa edellisen komennon virhekoodin
Varoitus
- Komentojonoon asetettujen komentojen asynkroninen suoritus saattaa aiheuttaa ongelmia myöskin virhetilanteiden käsittelyssä
- Komennon komentojonoon asettanut aliohjelma/jäsenfunktio palauttaa tiedon vain niistä virheistä, jotka tapahtuivat silloin kun komento asetettiin komentojonoon
- Varsinaiset komennon suorittamiseen liittyvät virheet ilmoitetaan vasta myöhemmin!
- Esimerkki:
// Oikein toimiva muistisiirto, blockkaava / synkroninen
err = cudaMemcpy(
deviceBuffer, hostBuffer, N*sizeof(int), cudaMemcpyHostToDevice);
if(err != cudaSuccess) { ...
// Virheellisesti toimiva ydin, ei-blockkaava / asynkroninen
add_one<<<WGCount, localDim>>>(deviceBuffer, N);
if(cudaGetLastError() != cudaSuccess) {
// Käynnistys meni ok, joten ei virhettä!!!
}
// Oikein toimiva muistisiirto, blockkaava / synkroninen
cudaMemcpy(hostBuffer, deviceBuffer, N*sizeof(int), cudaMemcpyDeviceToHost);
if(err != cudaSuccess) {
// add_one-yimen aiheuttama virhe tulee ilmi täällä!!!
}- Voit synkronoida isäntäohjelman suorituksen jokaisen asynkronisen komennon jälkeen, jolloin
cl::CommandQueue::finish(),cudaStreamSynchronize(cudaStream_t stream)taicudaDeviceSynchronize()palauttavat ajonaikaisista virheestä kertovat virhekoodit: - Esimerkki:
add_one<<<WGCount, localDim>>>(deviceBuffer, N);
if(cudaGetLastError() != cudaSuccess) {
// Ilmoita virheistä, jotka tapahtuivat kun komentoa oltiin asettamassa
// komentojonoon
}
#if DEBUG
err = cudaDeviceSynchronize();
if(err != cudaSuccess) {
// Ilmoita ajonaikaisesta virheestä
}
#endif- Ohjelmakoodin kääntäminen
-D DEBUG-lipun kanssa aktivoi yllä esiintyneen debuggauskoodin
Ytimien kirjoittamisesta
Muistutus
- Säieryhmien ja säikeiden suoritusjärjestystä ei ole määritelty
- Esimerkiksi seuraavan koodin ei ole hyvin määritelty:
void swap(__local int *buff) {
int local_id = get_local_id(0);
int local_size = get_local_size(0);
// Yritetään vaihtaa taulukon luvut käänteiseen järjestykseen
int x = buff[local_id];
// Osa säikeistä ei ole vielä välttämättä suorittanut edeltävää riviä tässä
// vaiheessa!
buff[local_size-local_id-1] = x;
}Synkronointi
- Ohjelmoija voi kuitenkin käyttää esteitä ytimen suorituksen synkroimiseen säieryhmätasolla:
Synkronointi OpenCL:ssä
- Samaan säieryhmään kuuluvat säikeet voivat synkronoida
barrier-esteen avulla:
void barrier (cl_mem_fence_flags flags);- Argumenttina annettu
flags-lippu voi olla yhdistelmä seuraavista:CLK_LOCAL_MEM_FENCE-lippu takaa, että kaikki lokaaliin muistiin liittyneet operaatiot on suoritettu loppuunCLK_GLOBAL_MEM_FENCE-lippu takaa, että kaikki globaaliin muistiin liittyeet operaatiot on suoritettu loppuun
- Kaikkien säikeiden tulee suorittaa sama
barrier-komento!
Synkronointi CUDA:ssa
- CUDA:ssa
__syncthreads()-aliohjelma on sama OpenCL:n kuin
barrier(CLK_LOCAL_MEM_FENCE | CLK_GLOBAL_MEM_FENCE);- Tämän lisäksi CUDA:sta löytyy
__threadfence_block(),__threadfence()ja__threadfence_system()aliohjelmat, joiden lopputulos on heikompi, mutta niistä saattaa olla hyötyä joissakin tapauksissa - Tällä hetkellä
__syncthreads()-aliohjelma riittää ihan hyvin
Esimerkkejä
- Esimerkiksi aikaisempi ohjelmakoodi voitaisiin korjata seuraavasti:
void swap(__local int *buff) {
int local_id = get_local_id(0);
int local_size = get_local_size(0);
// Jokainen säie lukee luvun taulukosta
int x = buff[local_id];
// Odotetaan, että jokainen säie on lukenut oman lukunsa muuttujaan x
barrier(CLK_LOCAL_MEM_FENCE);
// Kirjoitetaan tulos takaisin taulukkoon
buff[local_size-local_id-1] = x;
}- Seuraava esimerkki ei toimi tai johtaa määrittelemättömään lopputulokseen:
void swap(__local int *buff, int n) {
int local_id = get_local_id(0);
// Järjestetään vain n ensimmäistä alkiota
if(local_id < n) {
int x = buff[local_id];
// Osa säikeistä ei välttämättä suorita tätä riviä ollenkaan, jonka
// seurauksena if-lohkoon tullet säikeet jäävät ikuisesti odottamaan
// niiden saapumista!
barrier(CLK_LOCAL_MEM_FENCE);
buff[n-local_id-1] = x;
}
}Printf
- CUDA ja OpenCL 1.2 tukevat
printf-aliohjelman käyttöä ytimen sisällä - Huomaa, että makon GPU tukee vain OpenCL 1.1:stä!
- Ytimestä tulostaminen hidastaa ohjelman suoritusta merkittävästi, joten käytä sitä vain debuggaus-tarkoituksiin ja vältä turhia tulostuksia
- Esimerkki:
__kernel void add_one(__global int *buffer, int n) {
const int global_id = get_global_id(0);
if(global_id < n)
buffer[global_id]++;
else
printf("Säie %d ei tehnyt mitään.\n", global_id);
}