Lukijalle
Alkuun annan sulle vinkin, |
Pakko tehdä on demoja, |
Tämä moniste on tarkoitettu oheislukemistoksi Ohjelmointi 2-kurssille.
Vaikka monisteen yksi teema onkin Java-kieli, ei kieli ole monisteen päätarkoitus. Päätarkoituksena on esitellä ohjelmointia. Esitystavaksi on valittu yhden ohjelman suunnitteleminen ja toteuttaminen alusta lähes loppuun saakka. Tämä Top-Down -metodi tuottaa varsin suuren kokonaisuuden, jonka hahmottaminen saattaa aluksi tuntua vaikealta.
Kunhan oppii kuitenkin katsomaan kokonaisuuksiin yksityiskohtien sijasta, asia helpottuu. Yksityiskohtia harjoitellaan monisteen esimerkeissä (Bottom-Up), joista suuri osa liittyy monisteen malliohjelmaan, mutta jotka silti voidaan käsittää mallista riippumattomina palasina.
Monisteen ohjelmat ovat saatavissa myös elektronisesti, jotta niiden toimintaa voidaan kokeilla kunkin vaiheen jälkeen.
Java-kieltä ja sen ominaisuuksia on monisteessa sen verran, että lukijalla on juuri ja juuri erittäin pienet mahdollisuudet selvitä ilman muuta kirjallisuutta.
Lukijan kannattaakin ilman muuta hankkia ja seurata tämän monisteen rinnalla jotakin varsinaista Java-ohjelmointikirjaa. Hyvä kotimainen vaihtoehto on esimerkiksi: Jorma Kyppö, Mika Vesterholm: Java-ohjelmointi, 2018, Talentum Oyj. Myös ohjelmointiympäristön mukana olevasta OnLine-avustuksesta (Help) saa tarvittavaa lisätietoa.
Monisteen esimerkkiohjelmat löytyvät elektronisessa muodossa:
Mikroluokka: n:\kurssit\ohj2\moniste\esim
WWW: https://gitlab.jyu.fi/tie/ohj2/moniste/-/tree/master/esimerkit/src
Edellä mainittuun polkuun lisätään vielä ohjelman yhteydessä mainittu polku.
Monisteessa on lukuisia esimerkkitehtäviä, joiden tekeminen on oppimisen kannalta lähes välttämätöntä. Vaikka lukija saattaa muuta kuvitellakin, ovat monisteen vaikeimmat tehtävät monisteen alussa. Mikäli loppupuolen tehtävät tuntuvat vaikeilta, ei monisteen alkuosa olekaan hallinnassa. Siksi kehotankin lukijaa aina vaikeuksia kohdatessaan palaamaan monisteen alkuosaan; siitä ei monikaan voi sanoa, ettei asioita ymmärtäisi.
Lopuksi kiitokset kaikille työtovereilleni monisteen kriittisestä lukemisesta. Erityisesti Tapani Tarvainen on auttanut suunnattomasti C-kieleen tutustumistani ja Jonne Itkonen vastaavasti tutustumista Java ja C++-kieleen ja olio-ohjelmointiin.
Alkuperäinen versio allekirjoitettu Palokassa 28.12.1991
Monisteen 3. korjattuun painokseen on korjattu edellisissä monisteissa olleita painovirheitä sekä lisätty lyhyt C-kielen "referenssi". Lisäksi kunkin esimerkkiohjelman alkuun on laitettu kommentti siitä, mistä tiedostosta lukija löytää esimerkin. Myös hakemistoa on parannettu vahventamalla määrittelysivun sivunumero.
Palokassa 28.12.1992
Monisteen 4. korjattuun painokseen on jopa vaihdettu monisteen nimi: Ohjelmointi++, kuvaamaan paremmin olio-ohjelmoinnin ja C++:n saamaa asemaa. Tätä kirjoittaessani moniste ei ole vielä kokonaan valmis ja kaikkia siihen tulevia muutoksia en vielä tässä pysty luettelemaan.
Joka tapauksessa olen monisteeseen lisännyt tekstiä - valitettavasti nimenomaan ohjelmointikieleen liittyvää - jota vuosien varrella olen huomannut opiskelijoiden jäävän kaipaamaan. Lisäksi kunkin luvun alkuun on lisätty suppea luettelo luvun pääteemoista ja luvussa esiintyvistä kielen piirteistä sekä niiden syntaksista. Tämä syntaksilista on helppolukuinen "lasten" syntaksi, varsinainen tarkka ja virallinen syntaksi pitää katsoa kielen määrityksistä.
Ohjelmalistauksiin on lisätty syntax-highlight, eli kielen sanat on korostettu, ja näin lukijan toivottavasti on helpompi löytää mitkä termit on itse valittavissa ja mitkä täytyy kirjoittaa juuri kuvatulla tavalla. Myös joitakin vinkkejä on lisätty. Pedagogisesti on vaikea päättää, saako esittää virheellisiä tai huonoja ohjelmia lainkaan, mutta vanha viidakon sananlasku sanoo että "Viisas oppii virheistä, tavallinen kansa omista virheistä ja tyhmä ei niistäkään". Siis mahdollisuus "viisaillekin" ja nämä virheelliset ohjelmat on merkitty surullisella naamalla: ?. Näin aivan jokaisen ei tarvitse rämpiä jokaista sudenkuoppaa pohjia myöten ominpäin.
Olio-ohjelmointi on kuvattu esimerkkien avulla ja varsinainen oliosuunnittelu - joka on erittäin tärkeää - on jätetty erittäin vähälle. Suosittelenkin lukijalle jonkin oliosuunnitteluun liittyvän kurssin käymistä tai kirjan lukemista.
Myös tätä kurssia edeltävä kurssi Ohjelmoinnin alkeet on kokenut muutoksia, ja vaikka kurssi meneekin nykyisin entistä pitemmälle, ei tästä monisteesta ole kuitenkaan poistettu kaikkea päällekkäisyyttä Ohjelmoinnin alkeet -monisteen kanssa. Toimikoon nämä päällekkäisyyden kertauksena ja kohtina, joissa luennoilla voidaan asia sivuttaa nopeammin. Joka tapauksessa lukijan kannattanee pitää myös Ohjelmoinnin alkeet -moniste tämän monisteen rinnalla.
Palokassa 5.1.1997
Monisteen 5. korjattuun painokseen on korjattu pieniä kirjoitusvirheitä ja epätäsmällisyyksiä. Samalla on poistettu hieman C-esimerkkejä ja yritetty enemmän jättää jäljelle esimerkkejä siitä, kuinka käytännössä kannattaa tehdä. Nyt erityisesti kurssia myös pitänyt Antti-Juhani Kaijanaho on antanut merkittävästi palautetta monisteesta.
Palokassa 30.12.2001
Monisteen uusi painos on kirjoitettu C++:n sijasta Java-ohjelmointia silmällä pitäen.
Monisteessa olevat Kalevala-mittaiset runot ovat syntaksin mukaisia. Lukija voi itse päättää riittääkö se. Sama pätee ohjelmoinnissa. Syntaktisesti oikea ohjelma on vielä kaukana toimivasta ohjelmasta.
Palokassa 30.12.2002
Monisteen vuoden 2012 versioon on lisätty graafisen käyttöliittymän tekeminen Swing-kehyksellä sekä korjattu lukuisia pieniä yksityiskohtia. Kiitoksia Santtu Viitaselle tehdystä työstä.
Palokassa 25.12.2011
Moniste on muutettu TIM-muotoon, eli siihen on lisätty interaktiivisia osia.
Palokassa 8.1.2015
Lisätty "testamenttikommentteja" (niitä varmaan tulee lisääkin) ja korttipelejä algoritmien harjoitteluun.
Palokassa 12.1.2025
Vesa Lappalainen
1. Johdanto
Alkoi kurssi, alkoi uusi
tuska tuli, moni jo huusi:
Javaa jankuttaa tuo ukko
syntaksia sammaltaapi.
Tokko tavalla tuollasella
ohjelmoimaan oppimahan
Java kieltä pänttämähän
Ceetä kalloon taikomahan.
Arvelee, ajattelevi,
pitkin päätänsä pitävi:
Ei oo ulkoo oppimista,
kieli väkisin vääntämistä.
Pohtimaan pitää heretä
ongelmia oikomahan
sulamahan suunittelu
pohja vankaksi valaman.
Tämän monisteen tarkoituksena on toimia tukimateriaalina opeteltaessa sekä algoritmisen että olio-ohjelmoinnin alkeita. Aluksi meidän tulee ymmärtää mitä kaikkea ohjelmointi pitää sisällään. Aivan liian usein ohjelmointi yhdistetään päätteen äärellä tapahtuvaan jonkin tietyn ohjelmointikielen koodin naputtamiseen. Tämä on ehkä ohjelmoinnin näkyvin, mutta myös toisaalta mekaanisin ja helpoin osa.
Ohjelmointi voidaan jakaa esimerkiksi seuraaviin vaiheisiin:
- tehtävän saaminen
- tehtävän tarkentaminen ja tarvittavien toimintojen hahmottaminen
- ohjelman toimintojen ja tietorakenteiden suunnittelu, oliosuunnittelu
- yksityiskohtaisten olioiden ja algoritmien suunnittelu
- OHJELMOINTITYÖKALUN VALINTA
- algoritmien/luokkien metodien tarkentaminen valitulle työkalulle
- ohjelmakoodin kirjoittaminen
- ohjelman testaus
- ohjelman käyttöönotto
- ohjelman ylläpito
Kannattaa huomata, että listalla varsinaisesti tietokoneella tehtävä työ on listan viimeisissä kohdissa. Pitkään ohjelmistojen suunnittelu ja toteutus seurasivatkin orjallisesti vaihe vaiheelta yllä olevan kaltaista listaa. Tämä vesiputousmalliksi kutsuttu toteutustapa oli ennen ohjelmistokehityksen kulmakivi, jolla toteutettiin käytännössä kaikki ohjelmointiprojektit. Maailmalla ilmestyi kuitenkin tutkimuksia, joiden mukaan suurin osa ohjelmistoprojekteista itse asiassa epäonnistui, mikä tietysti on hälyttävää millä tahansa alalla.
1.1 Ketterät menetelmät
Nykyään perinteisen vesiputousmallin rinnalle on noussut niin sanottu ketterä ohjelmistokehitys (Agile Software Development). Se on joukko menetelmiä joiden leimaavin piirre on ohjelmien kehittäminen pienissä pätkissä, joissa jokaisessa toteutetaan kaikki ohjelmistokehityksen vaiheet. On jopa mahdollista että yksi ihminen työstää useaa vaihetta kerralla! Ketterillä menetelmillä on oma julistus, Agile Manifesto, jonka arvoja ne pyrkivät noudattamaan.
- Yksilöt ja vuorovaikutus yli prosessien ja työkalujen
- Toimiva ohjelma yli kokonaisvaltaisen dokumentaation
- Asiakasyhteistyö yli sopimusneuvottelujen
- Muutoksiin vastaaminen yli suunnitelman seuraamisen
Tavoitteita tulkittaessa täytyy kuitenkin muistaa, että vaikka menetelmät pitävätkin lihavoituja asioita arvokkaampana, niin ne eivät tee silti muista merkityksettömiä.
Vaikka tavoitteet ovatkin yhteneväiset, niin menetelmien väliset erot ovat usein suuria. Jotkut saattavat painottuvat projektinhallintaan, kun taas joku tarjoaa käytännön ohjeita ohjelmoijan työskentelytapoihin.
1.2 Extreme Programming
Tämän kurssilla opetuksessa ja varsinkin harjoitustyön toteuttamisessa pyritään mahdollisuuksien mukaan soveltamaan ja lainaamaan paljon niin sanotulta Extreme Programming (XP) menetelmältä. Tietenkin menetelmä on kehitetty työelämän tarpeisiin, eikä sen soveltaminen sellaisenaan opetuskäyttöön ole mahdollista.
1.2.1 Kurssilla sovellettavia XP:n käytäntöjä
- Iteraatiot
- Aiemmista kokemuksista oppiminen
- Testilähtöinen ohjelmointi
- Pariohjelmointi
- Uudelleenrakentaminen
- Yhteisomistajuus
- Jatkuva integrointi
- Et tule tarvitsemaan sitä (yksinkertainen rakenne)
- Hallinnon (opettajat ja ohjaajat) taustatuki
- Tasainen työtahti
- Julkaisujen suunnittelu
- Hyväksyntätestaus
- Lyhyin väliajoin tuotettavat julkaisut (pienet julkaisut)
1.3 Ohjelman suunnittelu
Aluksi kurssi keskittyy ohjelmoinnin perusteiden, kuten algoritmien ja oman ohjelman suunnitteluun. Nykyisin suunnittelun alkuvaiheessakin tarvittava dokumentointi ja ideoiden sekä vaihtoehtojen kirjaaminen tehdään käyttäen tekstinkäsittelyohjelmia ja/tai kaavioiden piirtoa piirto-ohjelmilla. Varsinaisesta koodauksesta ei kuitenkaan alkuvaiheessa ole kysymys.
Ohjelman kehityksen eri vaiheissa saatetaan tarvittaessa palata takaisin alkumäärityksiin. Kuitenkin ohjelman valittujen toimintojen muuttaminen oman laiskuuden tai osaamattomuuden takia ei ole suotavaa. Ei saa lähteä ompelemaan kissalle takkia ja huomata, että kangas riittikin lopulta vain rahapussiin.
Usein ohjelmointikursseilla unohdetaan itse ohjelmointi ja keskitytään valitun työkalun - ohjelmointikielen - esittelyyn. Ajanpuutteen takia tämä onkin osin ymmärrettävää. Kuulijat kuitenkin hämääntyvät, eivätkä ymmärrä luennoitsijan tekevän edellä kuvatun listan kaltaista suunnittelutyötä myös kunkin pienen malliesimerkin kohdalla. Kokenut ohjelmoija saattaa pystyä hahmottamaan ongelman ratkaisun ja tarvittavat erikoistapaukset päässään silloin, kun on kyse erittäin lyhyistä malliesimerkeistä. Jossain vaiheessa ohjelmoinnin oppimista suunnittelu ja koodin kirjoittaminen tuntuvat sulautuvan yhteen.
Opiskelun alkuvaiheessa on kuitenkin syytä keskittyä nimenomaan ongelman analysointiin ja ohjelman suunnitteluun. Tässä paras apu on usein terve maalaisjärki. Mitä vähemmän ymmärtää itse ohjelmointikielistä, sitä vähemmän kielet rajoittavat luovaa ajattelua.
Usein ohjelman suunnittelu voidaan aloittaa jopa käyttöohjeen kirjoittamisella! Tällöin tulee tutkituksi ohjelmalta vaaditut ominaisuudet ja toimintojen loogisuus sekä helppokäyttöisyys! Nykytyökaluilla voidaan myös rakentaa suhteellisen helposti ensin ohjelman käyttöliittymä ilman oikeita toimintoja. Tätä "protoa" voidaan sitten tutkia yhdessä asiakkaan kanssa ja päättää toimintojen loogisuudesta ja riittävyydestä.
1.4 Työkalun valinta
Kun ohjelmaan on suunniteltu halutut toimenpiteet ja päätetty mitä tietorakenteita tarvitaan, on edessä työkalun valinta. Nykypäivänä ei ole itsestään selvää, että valitaan työkaluksi jokin perinteinen ohjelmointikieli. Vastakkain pitää asettaa erilaiset sovelluskehittimet, valmisohjelmat kuten tietokannat ja taulukkolaskennat, ehkä jopa tavallinen tekstinkäsittely sekä ohjelmointikielet. Matemaattisissa ongelmissa jokin symbolisen tai numeerisen laskennan paketti saattaa olla soveltuva.
Ratkaisu voi koostua myös useiden eri ohjelmien toimintojen yhdistelemisestä: CAD -ohjelmalla piirretään/digitoidaan kartan pohjakuva, tietokantaohjelmalla pidetään kirjaa paikoista ja pienellä C/C++ tai Java-kielisellä ohjelmalla suoritetaan ne osat, joita CAD-ohjelmalla tai tietokantaohjelmalla ei voida suorittaa.
Joskus työkaluksi valitaan prototyyppiä varten jokin sovelluskehitin tai tietokantaohjelmisto. Kun halutut toiminnot on perusteellisesti testattu ja tuotetta tarvitsee edelleen kehittää, voidaan ohjelmointi toteuttaa uudelleen vaikkapa Java-kielellä. Prototyyppi on rinnalla toimivana ja uudessa ohjelmassa käytetään samoja tietoja ja toimintoja.
1.5 Koodaus
Mikäli työkalun valinnassa päädytään olio/lausekieleen (esim. C++ tai Java), ei pyörää kannata keksiä uudelleen. Nelikulmioon nähden kolmikulmiossa on yksi poksaus vähemmän kierroksella, mutta kyllä silti ympyrä on paras. Siis käytetään toisten kirjoittamia valmiita olioita ja/tai aliohjelmapaketteja "likaisessa" työssä. Tosin nykyisin erityisesti WWW-ohjelmoinnnissa on oltava varovainen sen suhteen, että mitkä kirjastot ovat käytössä vielä viiden vuoden päästä. Joidenkin ohjelmien käyttöikä voi olla kymmeniä vuosia.
Aina tietenkin puuttuu joitakin alemman tason palasia. Nämä tietysti koodataan JA TESTATAAN ERILLISINÄ ennen varsinaiseen ohjelmaan liittämistä.
Siis itse koodaus on pienten aputyökalujen etsimistä, tekemistä, testaamista ja dokumentointia. Lopullinen koodaus on näiden aputyökaluista muodostuvan palapelin yhteen liittäminen.
Jo koodausvaiheessa kannattaa miettiä ongelman yleisiä ominaisuuksia. Jos ollaan kirjoittamassa telinevoimistelun pistelaskua naisten sarjaan, niin koodissa ei mitenkään tulisi estää ohjelman käyttöä myös miesten sarjassa. Siis telineiden nimet ja määrät pitäisi olla helposti muutettavissa.
VL 2025: ironista kyllä kirjoitin tuon kun olin katsonut televisiosta voimistelua. Totuus paljastui vuosia myöhemmin kun jälkikasvu alkoi harrastamaan kilpavoimistelua ja jouduin oikeasti tekemisiin voimistelun tuloslaskennan kanssa. Ei ollutkaan ihan niin helppoa kuin telkkarista näytti :-)
Koodausta voidaan tehdä joko BOTTOM-UP periaatteella, jolloin ensin rakennetaan työkalut (=olioluokat/aliohjelmat), jotka sitten kasataan yhteen. Toinen mahdollisuus on koodaus TOP-DOWN periaatteella, jolloin päätoiminnat kirjoitetaan ensin ja alatoiminnoista tehdään aluksi tyhjiä laatikoita. Myöhemmin valmiita ja testattuja alitoimintoja liitetään tähän runkoon. Valitulla menetelmällä ei ole vaikutusta lopputulokseen, ja joskus voikin olla hyvää vaihtelua siirtyä näpertelemään pikkuasioiden kimpussa isojen kokonaisuuksien sijasta tai päinvastoin.
Missään tapauksessa ohjelma ei synny siten kuin se kirjallisuudessa näyttää olevan: alkumäärittelyt, aliohjelmat ja päämoduuli.
Koodaajan on osattava hyvin käytettävä työkalu, esim. ohjelmointikieli. Kuitenkin jonkin ohjelmointikielen hyvän osaamisen avulla on suhteellisen helppo kirjoittaa myös muun kielisiä ohjelmia.
Koodaus on pääosin tekstinkäsittelyä ja 10-sormijärjestelmä nopeuttaa koodin syntymistä oleellisesti. Myös hyvä tekstinkäsittelytaito valmiiden palasten siirtelemisineen ja kopioimisineen helpottaa tehtävää.
1.6 Testaus
Ohjelman testaus alkaa jo suunnitteluvaiheessa. Valitut algoritmit ja toiminnot pitää pöytätestata teoriassa ennen niiden koodaamista. Suunnitteluvaiheessa täytyy miettiä kaikki mahdolliset erikoistapaukset ja todeta algoritmin selviävän niistäkin tai ainakin määritellä miten erikoistapauksissa menetellään. Testitapaukset kirjataan ylös myöhempää käyttöä varten.
Koodausvaiheessa kukin yksittäinen aliohjelma/luokka testataan kaikkine mahdollisine syötteineen pienellä testiohjelmalla. Aliohjelman kommentteihin voidaan kirjata suunnitteluvaiheessa todettu testiaineisto ja testausvaiheessa ruksataan testatut toiminnot ja erikoistapaukset. Tavan heikkous piilee kuitenkin siinä, että mikäli haluamme muuttaa nyt alkuperäistä koodia, meidän on mahdoton tietää vaikuttaako muutos johonkin toiseen ohjelmiston osa-alueeseen joka käyttää koodia hyväkseen.
Nykyisin ratkaisuksi on kehitetty testausta automatisoivia työkaluja, kuten Javan käyttämä JUnit. Yksikkötestauksen idea on kirjoittaa jokaisen ohjelmiston osaan testikoodi, mikä voidaan ajaa keskitetysti vaikka koko ohjelmistolle kerralla.
Eräs yksikkötestausta hyödyntävä tekniikka on testivetoinen kehitys (TDD, test-driven development). Sen tarkoituksena on kirjoittaa koodi testattavaksi ja testit ennen varsinaisen ohjelmakoodin kirjoittamista. Tämän ehkä aluksi nurinkuriselta tuntuvalla ajatuksella on kuitenkin useita hyötyjä. Kyse ei ole niinkään testaustyökalusta, vaan ohjelman suunnittelusta, josta syntyykin sivutuotteena valmiit testitapaukset.
Tällä kurssilla testaamiseen voi käyttää myös Jyväskylän yliopistossa kehitettyä ComTest työkalua. Työkalu helpottaa JUnit testien tekemistä ja sen avulla pystyy samalla luomaan myös kattavan JavaDoc dokumentaation.
Lopullisen ohjelman toimivuus riippuu hyvin paljon siitä, miten hyvistä palasista se on kasattu.
Ennen virheiden löytämiseksi testiohjelmiin lisättiin tulostuslauseita. Nykyisin tehokkaat debuggerit helpottavat testausta huomattavasti: ohjelman toimintaa voidaan seurata askel kerrallaan ja epäilyttävien muuttujien arvoja voidaan tarkistaa kesken suorituksen. On myös mahdollista laittaa ohjelma pysähtymään jonkin muuttujan saadessa virheellisen arvon.
Testaus on vaihe, missä hyvä koneenkäyttörutiini ja epäluulo ovat suureksi avuksi.
1.7 Hyväksymistestaus ja palaute
Ketterien menetelmien tärkeimpiä osa-alueita on jatkuva vuorovaikutus asiakkaan kanssa. Aluksi tällä kurssilla asiakkaana toimii oppilas itse suunnitellessaan harjoitustyöohjelman toiminnot ja käyttötarkoituksen. Harjoitustyötä tehdään pienissä vaiheissa, eli iteraatioissa, joiden tarkoitus on pitää ohjelma jatkuvasti toimivana kokonaisuutena, mihin on helppo lisätä uusia ominaisuuksia yksi kerrallaan. Vaiheen päätettyä tehdään hyväksymistestaus, jossa työ esitellään asiakkaalle (ohjaajalle), jolta saa vinkkejä ja palautetta ohjelman toiminnan parantamiseksi.
Jokaisessa vaiheessa toteutetaan jokin ohjelman osa-alue tai parannellaan vanhaa. Tämä työ sisältää suunnittelun, testauksen, koodauksen ja dokumentoinnin.
1.8 Käyttöönotto
Ketteriä menetelmiä käyttämällä ohjelman käyttöönottovaiheessa sen pitäisi olla testattu ja valmis. Tietysti julkaisuversioonkin pääsee lähes aina livahtamaan joitakin bugeja, mutta niiltä ei taitavinkaan ohjelmoija voi välttyä. Asiakas on lisäksi pidetty mukana koko prosessin ajan, eikä ikäviä yllätyksiä - joissa ohjelma ei olekaan toiminnallisuudeltaan sitä mitä on odotettu - pääse syntymään.
1.9 Ylläpito
Jos kuitenkin ohjelmasta paljastuu virheitä tai puuttuvia toimintoja. Virheet pitää korjata ja puuttuvat toiminnot mahdollisesti lisätä, jolloin ollaan jälleen ohjelmansuunnittelun alkuvaiheessa. Hyvin suunniteltuun ohjelmaan saattaa olla helppo lisätä uusia toimintoja ja vastaavasti huonosti suunnitellussa saattavat jopa tietorakenteet mennä uusiksi. Tosin tätäkään ei pidä pelätä, sillä yksinkertaisesti aina ei ole mahdollista ottaa etukäteen kaikkea huomioon.
VL24: Enää en edes sanoisi huonosti suunnitelluksi jos tietorakenteita (usein tietokannan tauluja) joutuu jälkeenpäin muuttamaan. Vaan viitaten tuohon edelliseen viimeiseen lauseeseen "ei aina osata etukäteen ottaa huomioon", tulee väkisin tilanteita mitkä selviävät vasta myöhemmin. Monen asiasta ymmärtämättömän ensimmäinen lause on "huonosti suunniteltu". Totuus on kuitenkin, että tarpeet muuttuvat kun pistetään kädet saveen. Siksi Agile-menetelmät.
Myös ohjelman alkuperäiset kirjoittajat ovat saattaneet häipyä ja mikäli kehitysprosessiin ei ole kiinnitetty tarpeellista huomiota, niin joku onneton kesätyöntekijä joutuu ensitöikseen paikkaamaan toisten huonosti dokumentoimaa sotkua.
1.10 Yhteenveto, kielellä ei väliä
Ohjelmointi ei yleensä ole yhden henkilön työtä. Eri henkilöt voivat tehdä eri vaiheita ohjelmoinnissa. Lähes aina tulee tilanne, missä jonkin toisen kirjoittamaa koodia joudutaan korjailemaan.
Oli ohjelmaa tekemässä kuinka monta henkilöä tahansa (vaikka vain yksi), pitää ohjelmointi jakaa vaiheisiin. Oikeaa ohjelmaa on mahdoton "nähdä" valmiina Java-kielisinä lauseina heti tehtävän määrityksen antamisen jälkeen. Aloitteleva ohjelmoija kuitenkin haluaisi pystyä tähän (koska hän "näkee" määrityksestä: Kirjoita ohjelma joka tulostaa "Hello world", heti myös Java-kielisen toteutuksen). Tämän takia ohjelmoinnin helpoin osa, eli koodaus koetaan ohjelmoinnin vaikeimmaksi osaksi - suunnittelu on unohtunut!
Valitulla ohjelmointikielellä ei ole suurtakaan merkitystä ohjelmoinnin toteuttamiseen. Jokin kieli saattaa soveltua paremmin johonkin tehtävään, mutta pääosin BASIC, Fortran, Pascal, C, Modula-2, ADA jne. ovat samantyylisiä lausekieliä. Samoin oliokielistä esimerkiksi C++, Java, C#, Delphi (Pascal) ja Python ovat hyvin lähellä toisiaan. Kun yhden osaa, on toiseen siirtyminen jo helpompaa.
Jos joku kuvittelee, ettei hänen tarvitse koskaan ohjelmoida C/C++ tai Java-kielellä, voi hän olla aivan oikeassakin. Nykyisin kuitenkin jokaisessa tietokantaohjelmassa, taulukkolaskentaohjelmassa ja jopa tekstinkäsittelyohjelmissakin (vrt. esim. TEX, joka on tosin ladontaohjelma) on omat ohjelmointikielensä. Osaamalla jonkin ohjelmointikielen perusteet, voi saada paljon enemmän hyötyä käyttämästään valmisohjelmasta. Ja joka väittää selviävänsä nykymaailmassa (ja sattuu lukemaan tätä monistetta) esimerkiksi ilman tekstinkäsittelyohjelmaa on suuri valehtelija!
2. Kerhon jäsenrekisteri
Nyt tavuja taikomahan,
koodia kokoamahan?
Tuosta tokkopa tulisi
ohjelmaapa oivallista.
Ongelma jo täytyy olla
suunnitelma siivitellä
aikeet aina aatostella
toki tarpeet tarkastella.
Saatatko tuon jo sanoa
tieto kusta tarvitahan
ohjelman ositeltavan
jo bitteiksi pilkottavan.
Nyt liimaile liittymätä
sitä silmälle suotavaksi
käyttäjälle nähtäväksi
muille mutristeltavaksi.
Mitä tässä luvussa käsitellään?
- tehtävän "analysointi"
- ohjelman vaatimien aputiedostojen sisällön suunnittelu
- ohjelman suunnittelu ohjelman tulosteiden avulla
- suunnitelman korjaus
- tarvittavien algoritmien hahmottaminen
- relaatiotietomalli
2.1 Tehtävän tarkennus
Ohjelman suunnittelu aloitetaan aina tehtävän tarkastelulla. Annettua tehtävää joudutaan usein huomattavasti tarkentamaan.
Olkoon tehtävänä suunnitella kerhon jäsenrekisteri. Onko kerho iso vai pieni? Mitä tietoja jäsenistä tallennetaan? Mitä ominaisuuksia rekisteriltä halutaan?
Mikäli sovitaan, että kerho on kohtuullisen pieni (esim. alle 500 jäsentä), ei meidän heti alkuun tarvitse miettiä parhaita mahdollisia hakualgoritmeja eikä tiedon tiivistämistä.
Mitä tietoja jäsenistä tarvitaan?
- nimi
- hetu
- katuosoite
- postinumero
- postiosoite
- kotipuhelin
- työpuhelin
- autopuhelin
- liittymisvuosi
- tämän vuoden maksetun jäsenmaksun suuruus
- lisätietoja
jne...
Mitä ominaisuuksia rekisteriltä halutaan?
- kerholaisten lisääminen
- kerholaisten poistaminen
- tietyn kerholaisen tietojen hakeminen
- tietyn kerholaisen tietojen muuttaminen
- postitustarrat postinumerojärjestyksessä
- nimilista nimen mukaisessa järjestyksessä
- lista jäsenmaksua maksamattomista jäsenistä
jne...
2.2 Työkalun valinta, vaihtoehtoja
On varsin selvää, ettei tätä nimenomaista tehtävää kannattaisi nykypäivänä lähteä itse ohjelmoimaan, vaan turvauduttaisiin tietokantaohjelmaan. Joissakin erikoistapauksissa saatetaan vaatia ominaisuuksia, joita tietokantaohjelmasta ei saada. Tällöin työkaluksi valittaisiin lausekieli ja tietokantaohjelmiston aliohjelmakirjasto, joka hoitelee varsinaiset tietokannan ylläpitoon yms. liittyvät toimenpiteet.
Edellinen analyysi on kuitenkin tehtävä työkalusta riippumatta! Esimerkin vuoksi jatkamme tehtävän tutkimista hieman pidemmälle tavoitteena ohjelmoida jäsenrekisteri jollakin lausekielellä.
2.3 Tietorakenteet ja tiedostot
Mikäli työkalun valinnassa on päädytty johonkin lausekieleen, on jossain vaiheessa päätettävä käytettävistä tietorakenteista. Esimerkin tapauksessa meillä on selvästikin joukko yhden henkilön tietoja. Mikäli yhden henkilön tietoa pidetään yhtenä yksikkönä (tietueena), on koko tietorakenne taulukko henkilöiden tiedoista. Taulukko voidaan tarvittaessa toteuttaa myös lineaarisena listana tai jopa puurakenteena. Mikäli kyseessä on pieni rekisteri, mahtuu koko tietorakenne ohjelman ajon aikana muistiin.
Missä tiedot tallennetaan kun ohjelma ei ole käynnissä? Tietenkin levyllä tiedostona. Minkä tyyppisenä tiedostona? Tiedoston tyyppinä voisi olla binäärinen tiedosto alkioina henkilötietueet. Tällaisen tiedoston käsittely hätätapauksessa on kuitenkin vaikeata. Varmempi tapa on tallentaa tiedot tekstitiedostoksi, jota tarvittaessa voidaan käsitellä millä tahansa tekstinkäsittelyohjelmalla. Tällöin on lisäksi usein mahdollista käsitellä tiedostoa taulukkolaskentaohjelmalla tai tietokantaohjelmalla ja näin joitakin harvinaisia toimintoja voidaan suorittaa rekisterille vaikkei niitä olisi alunperin edes älytty laittaa ohjelmaan mukaan.
Minkälainen tekstitiedosto? Ehkäpä yhden henkilön tiedot yhdellä rivillä? Miten yhden henkilön eri tiedot erotetaan toisistaan? Mahdollisuuksia on lähinnä kaksi: erotinmerkki tai tietty sarake. Valitaan erotinmerkki. Usein on mukavaa lisäksi laittaa joitakin huomautuksia eli kommentteja tiedostoon. Siis tallennustiedoston muoto voisi olla vaikkapa seuraava:
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
;sukunimi etunimi|hetu|katuosoite|postinumero|postiosoite|kotipuhelin|työpuhelin|
Ankka Aku|010245-123U|Paratiisitie 13|12345|ANKKALINNA|12-12324||
Susi Sepe|020347-123T||12555|Takametsä|||
Ponteva Veli|030455-3333||12555|Takametsä|||VL 2025: Jättäisin nykyisin pois sellaiset rivit, jotka eivät ole "samanmuotoisia keskenään". Eli nykyisin tallentaisin esimerkiksi tuon kerhon nimen eri tiedostoon.
Tällaisenaan tiedosto on varsin suttuinen luettavaksi. Vaikka valitsimmekin erotinmerkin erottamaan tietoja toisistaan, voimme silti kirjoittaa vastaavat tiedot allekkain sopimalla, ettei loppuvälilyönneillä ole merkitystä.
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
;sukunimi etunimi |hetu |katuosoite |postinumero|postiosoite|kotipuhelin|työpuhelin|
Ankka Aku |010245-123U|Paratiisitie 13 |12345 |ANKKALINNA |12-12324 | |
Susi Sepe |020347-123T| |12555 |Takametsä | | |
Ponteva Veli |030455-3333| |12555 |Takametsä | | |Nyt tiedostoa on helpompi lukea ja tyhjien kenttien jättäminen ei ole vaikeaa. Tiedosto vie kuitenkin levyltä enemmän tilaa kuin ensimmäinen versio, mutta sillä ei tietenkään nykyään ole mitään merkitystä. Lisäksi yhden henkilön tiedot eivät mahdu kerralla näyttöön. Onneksi kuitenkin lähes kaikki tekstieditorit suostuvat rullaamaan näyttöä myös sivusuunnassa. Mikäli saman henkilön tietoja jaettaisiin eri riveille, tarvitsisi meidän valita vielä tietueen loppumerkki (nytkin se on valittu: rivinvaihto).
2.4 Käyttöohje ja käyttöliittymä
Jatkosuunnittelu on ehkä helpointa tehdä suunnittelemalla ohjelman toimintaa käyttöohjeen tai käyttöliittymän tavoin.
Vaikka nykyaikaisilla ohjelmointiympäristöillä käyttöliittymän piirtäminen on tottuneelle käyttäjälle todella nopeaa, niin ensikertalaisen on kuitenkin helpompaa nopeampaa toteuttaa alustava suunnittelu perinteisesti esimerkiksi kynällä ja paperilla.
Suunnittelussa toimitaan käyttäjän ja helppokäyttöisyyden (= myös nopea käyttö, ei aina välttämättä hiiri) ehdoilla. On myös huomioitava ohjelmoitava alusta ja siinä vakiintuneet tavat toteuttaa toimintoja.
2.4.1 Ohjelman käynnistys
Ohjelma käynnistetään klikkaamalla kerho.jar-ikonia tai antamalla komentoriviltä komento
java -jar kerho.jarKun ohjelma käynnistyy, tulostuu näyttöön

Kerhon tiedot on tallennettu vaikkapa tiedostoon nimet.dat (hakemistoon kelmit). Näin voimme ylläpitää samalla ohjelmalla useiden eri kerhojen tietoja. Mitäpä jos tiedostoa ei ole? Tällöin voi syynä olla kirjoitusvirhe tai se, ettei rekisteriä ole vielä edes aloitettu. Miten ohjelman tulee tällöin menetellä? Mikäli käyttäjä antaa tiedoston nimen, jollaista ei tunneta, tulostuu näyttöön:
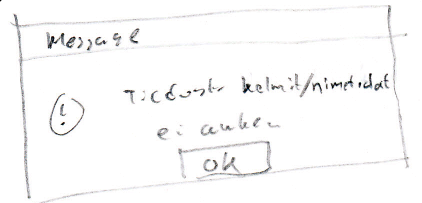
Tällöin käyttäjä voi aloittaa syöttämään uusia jäseniä tai jos kirjoitti nimen väärin, hän voi ottaa menusta Avaa-valinnan ja antaa uuden nimen
Edellä on edetty siihen saakka, kunnes ohjelmassa on päädytty pääikkunaan.
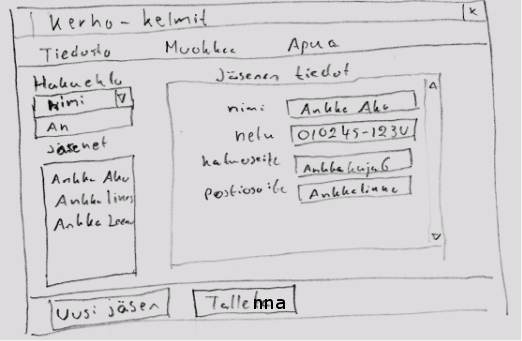
Pääikkunassa on seuraava menurakenne.
Tiedosto Muokkaa Apua
======== ======= =====
Tallenna Lisää uusi jäsen Apua
Avaa... Poista jäsen... Tietoja...
Tulosta...
LopetaSeuraavaksi voimme lähteä tarkastelemaan eri alakohtien toimintaa.
2.4.2 Hakeminen
Pääikkunan vasemmassa reunassa näkyy Hakuehto. Tästä voi valita minkä kentän mukaan etsitään. Tämän jälkeen tekstikenttään voi syöttää hakuehdon ja listaan tulee vain ne jäsenet joille haku toteutuu. Hakutermi saa löytyä valitusta kentästä mistä kohti vaan. Esimerkiksi jos kirjoitetaan hakuehtoon s, niin haetaan kaikki jäsenet joiden nimessä on s jossakin kohti.
Löytyneet jäsenet lajitellaan valitun hakukentän perusteella.
2.4.3 Muokkaaminen
Valittua jäsentä voidaan muokata menemällä tietoihin oikeaan kohtaan ja kirjoittamalla uusi arvo. Jos tietoon syötetään jotakin, mikä ei kelpaa, toimitaan seuraavasti:
Hetussa syötetty muodossa: 010243G1234
Tulee ilmoitus:
Väärä erotinmerkki
Samalla virheellinen syöttökenttä menee punaiseksi.2.4.4 Lisää uusi jäsen
Luo uuden tyhjän jäsenen.
2.4.5 Poista jäsen
Poistaa listasta valitun jäsenen. Varmistaa ennen poistoa.
Poistetaanko jäsen Ankka Iines?
Ok Cancel2.4.6 Tulosta
Tulostaa hakuehdon täyttävät jäsenet erilliseen ikkunaan halutussa muodossa. Tässä "esikatselussa" voi vielä muuttaa tietoja ja sitten tulostaa paperille.
2.4.7 Lopeta
Ohjelman lopetuksessa tulee huolehtia siitä, että ohjelman aikana mahdollisesti rekisteriin tehdyt muutokset tulevat tallennetuiksi.
Tämä voidaan tehdä automaattisesti tai tallennus voidaan varmistaa käyttäjältä. Automaattisen tallennuksen tapauksessa alkuperäinen tiedosto on ehkä syytä tallentaa eri nimelle.
2.4.8 Apua
Näyttää selaimessa ohjelman käyttöohjeen
2.4.9 Tietoja
Näyttää ohjelmasta tietoja vähän samaan tapaan kuin aloitusikkunassakin.
2.5 Hyväksymistestaus
Kun vaihe on valmis ja ohjelma täyttää sille asetetut vaatimukset se käydään läpi yhdessä asiakkaan ja tiimin kanssa, eli tässä tapauksessa jollakin kurssin ohjaajista. Usein tässä vaiheessa keksiikin työhön jotain parannuksia, mitä ei itse ole tullut ajatelleeksi. Viat yleensä korjataan seuraavaan vaiheeseen mennessä, mutta mikäli työ on jäänyt huomattavan keskeneräiseksi, niin kannattaa näyttää koko vaihe uudestaan.
Ensimmäisessä vaiheessa tutkitaan siis kirjoitettua käyttöohjetta, tietorakennetta ja piirrettyjä kuvia, jotka muodostavat alustavan suunnitelman ohjelman toiminnallisuudesta.
2.5.1 Tyypillisiä vikoja
Alussa tyypillisimmät viat liittyvät liian minimalistiseen dokumentaatioon. Dokumentaatiossa on hyvä pyrkiä täsmällisyyteen, sillä luotua tietoa hyödynnetään jatkuvasti projektin edetessä. Kaikki yleisimmät virheet johtuvat siitä, että yritetään oikaista asioissa, jotka vievät muutenkin vain murto-osan vaiheeseen käytetystä ajasta.
Tyypillistä on että mallitiedostot näyttävät jokseenkin tältä:
nimet.dat - ei näin
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
;sukunimi etunimi |hetu |katuosoite |postinumero|postiosoite|kotipuhelin|työpuhelin|
Joku1 |00000-5555 |Joku 1 |12345 |ANKKALINNA|12-12324 | |
Joku2 |…
…Tiedoston sisällöstä saa nyt jonkinlaisen idean, mutta selkeyden vuoksi mallidataa tarvitsee useita rivejä ja sen tulisi koostua "oikeista" arvoista. Dokumentaatiota kirjoittaessa pieni ajan säästäminen kostautuu useasti projektin edetessä. Kun sisällön tekee nyt kunnolla, niin samaa dataa voi käyttää hyödyksi viidennessä vaiheessa tietorakennekuvaa piirrettäessä, sekä mallitiedostona ohjelmaa luotaessa.
Lisäksi kannattaa miettiä ohjelman käyttötarkoitusta. Olisi rasittavaa jos Kerho aina varmistaisi saako käyttäjän lisätä, koska virheellisesti luodun henkilön tietoja voi kuitenkin jälkikäteen muokata. Käyttäjälle näytettävät varmistusdialogit sopivat peruuttamattomien muutoksien yhteyteen, mutta väärässä paikassa käytettynä ne hidastavat käyttöä täysin turhaan.
Ennen harjoitustyön näyttämistä kannattaa aina käydä tarkistamassa kurssin wikistä malliharjoitustyö ja tyypilliset harjoitustyön viat, jolloin selviää turhalta korjaamiselta.
2.6 Tarvittavien algoritmien hahmottaminen
Nyt olemme selvillä ohjelman toiminnasta. Edellisestä käyttöohjeesta voimme etsiä mitä työkaluja (aliohjelmia) tarvitsemme ohjelman toteutuksessa. Ainakin seuraavat tulevat helposti mieleen:
2.6.1 Ylemmän tason aliohjelmat
- tiedoston lukeminen
- tiedoston tallentaminen
- henkilön tietojen kysyminen päätteeltä
- tiedoston lajittelu haluttuun järjestykseen
- tiedon etsiminen tiedostosta tietyllä hakuehdolla
- uuden henkilön lisääminen tiedostoon
- henkilön poistaminen tiedostosta
.
2.6.2 Alemman tason aliohjelmat
Mikäli tutkimme yo. palasia tarkemmin, tarvitsemme ehkä seuraavia pienempiä ohjelman palasia (apualiohjelmia):
pitkän merkkijonon pilkkominen osamerkkijonoihin annetun merkin kohdalta
loppuvälilyöntien poistaminen merkkijonosta
isojen ja pienien kirjainten muuttaminen merkkijonossa esimerkiksi:
AKU ANKKA -> Aku Ankka aku ankka -> Aku Ankka aKU ANkKa -> AKU ANKKAhetun oikeellisuuden tarkistus
ovatko merkkijonot "
*aku*" ja "AKU ANKKA" samoja?
2.7 Koodaus ohjelmointikielelle
Seuraava vaihe olisi suunnitelman koodaaminen valitulle ohjelmointikielelle. Voisimme kirjoittaa aluksi löytämiämme alimman tason aliohjelmia (BOTTOM-UP-suunnittelu) ja testata ne toimiviksi. Voisimme myös kirjoittaa pääohjelman ja tyhjiä aliohjelmia testataksemme ohjelman rungon (TOP-DOWN). Puuttuvien toimintojen kohdalla ohjelma voidaan laittaa sanomaan.
TOIMINTAA EI OLE VIELÄ TOTEUTETTU!Emme kuitenkaan osaa vielä riittävästi ohjelmointikieltä, jotta voisimme aloittaa koodauksen. Huomattakoon, ettei yllä olevassa suunnitelmassa ole missään kohti vedottu käytettävään ohjelmointikieleen. Palaamme myöhemmin takaisin ohjelman osien koodaamiseen.
2.8 Varautuminen tulevaan, eli relaatiotietomalli
Vaikka sihteerimme ei juuri nyt huomannutkaan, saattaa hän tulevaisuudessa esimerkiksi kysyä miten rekisterillä pidettäisiin yllä tietoja jäsenten harrastuksista. Mietitäänpä?
Ensin miten harrastukset muuttaisivat tiedostomuotoamme?
2.8.1 Kaikki samassa tietueessa
Eräs mahdollisuus olisi lisätä kunkin rivin loppuun jollakin erotinmerkillä harrastukset:
nimet.dat - harrasteet samalle riville
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
; sukunimi etunimi |hetu |…|harrastukset
Ankka Aku |010245-123U|…|kalastus,laiskottelu,työn pakoilu
Susi Sepe |020347-123T|…|possujen jahtaaminen,kelmien kerho
Ponteva Veli |030455-3333|…|susiansojen rakentaminenRatkaisu toimisi tietyissä erityistapauksissa. Ongelmia tulisi esimerkiksi jos pitäisi kuhunkin harrastukseen liittää esimerkiksi harrastuksen aloitusvuosi, viikoittain harrastukseen käytetty tuntimäärä jne.
2.8.2 Erimalliset tietueet
Edellinen ongelma ratkeaisi esimerkiksi laittamalla henkilön tietojen rivin perään jollakin tavalla eroavia rivejä, joilla harrastuksen on lueteltu:
nimet.dat - harrasteet omalle riville
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
; sukunimi etunimi |hetu |katuosoite |postinumero|postiosoite|kotipuhelin|työpuhelin|
Ankka Aku |010245-123U|Paratiisitie 13|12345 |ANKKALINNA |12-12324 | |
- kalastus | 1955 | 20
- laiskottelu | 1950 | 20
- työn pakoilu | 1952 | 40
Susi Sepe |020347-123T| |12555 |Takametsä | | |
- possujen jahtaaminen | 1954 | 20
- kelmien kerho | 1962 | 2
Ponteva Veli |030455-3333| |12555 |Takametsä | | |
- susiansojen rakentaminen | 1956 | 15Ratkaisu olisi aivan hyvä ja tämän ratkaisun valitsemiseksi meidän ei tarvitsisi tehdä mitään muutoksia tiedostomuotoomme vielä tässä vaiheessa.
Huono puoli on kuitenkin se, että tämän muotoisen tiedoston siirrettävyys muihin järjestelmiin on varsin huono.
2.8.3 Relaatiomalli tiedostoon
Suurin osa tämän hetken valmiista järjestelmistä käyttää relaatiotietokantamallia. Tämä tarkoittaa sitä, että koko tietokanta koostuu pienistä tauluista, jossa kukin rivi (=tietue) on samaa muotoa. Eri taulujen välillä tiedot yhdistetään yksikäsitteisten avainkenttien avulla. Meidän esimerkissämme nimet.dat olisi yksi tällainen taulu (relaatio) ja henkilötunnus kelpaisi yhdistäväksi avaimeksi.
Kuitenkin henkilötunnus on varsin pitkä kirjoittaa ja välttämättä sitä ei saada kaikilta. Lisäksi tunnus voi vaihtua erinäisitä syistä. Jos tällainen pelko on olemassa, täytyy avain luoda itse. Itse ohjelman käyttäjän ei tarvitse tietää mitään tästä uudesta muutoksesta, vaan ohjelma voi itse generoida avaimet ja käyttää niitä sisäisesti.
Henkilötunnukseen liittyy vielä nykyisenä tietoturva-aikakautena sellaisia ongelmia, että sitä ei oikeastaan edes saisi kerätä. Osin sama voi jopa koskea tietoa josta selviää syntymäaika. Ja moni muukin kerättävä tieto voi olla ristiriitaista tietosuojalakien kanssa.
Valitaan yksilöiväksi tunnisteeksi vaikkapa juoksevasti generoituva numero. Jos jäseniä poistetaan jää ko. jäsenen numero vapaaksi eikä sitä yritetäkään enää käyttää. Uuden jäsenen numero olisi sitten aina suurin jäsenen numero +1.
nimet.dat - relaatiokannan päätaulu
Kelmien kerho ry
; Kenttien järjestys tiedostossa on seuraava:
;id|sukunimi etunimi |hetu |katuosoite |postinumero|postiosoite|kotipuhelin|työpuhelin|
1 |Ankka Aku |010245-123U|Paratiisitie 13 |12345 |ANKKALINNA|12-12324 | |
2 |Susi Sepe |020347-123T| |12555 |Takametsä | | |
4 |Ponteva Veli |030455-3333| |12555 |Takametsä | | |Harrastukset kirjoitetaan toiseen tiedostoon (hakemistoon kelmit), jossa tunnusnumerolla ilmaistaan kuka harrastaa mitäkin harrastusta.
harrastukset.dat - harrasteet relaation avulla
;id|harrastus |aloit |viikossa
1 |kalastus | 1955 | 20
1 |laiskottelu | 1950 | 20
1 |työn pakoilu | 1952 | 40
2 |possujen jahtaaminen | 1954 | 20
2 |kelmien kerho | 1962 | 2
4 |susiansojen rakentaminen | 1956 | 15Nyt esimerkiksi kysymykseen "Mitä Sepe Susi harrastaa" saataisiin vastus etsimällä ensin Sepe Suden tunnus (2) tiedostosta nimet.dat. Sitten etsittäisiin ja tulostettaisiin kaikki rivit joissa tunnus on 2 tiedostosta harrastukset.dat.
Myös vastaus kysymykseen "Ketkä harrastavat laiskottelua" löytyisi suhteellisen helposti.
Tämä ratkaisu vaatii muutoksen tiedostomuotoomme jo suunnitelman tässä vaiheessa, mutta toisaalta mikäli ratkaisu valitaan, voidaan sen ansiosta lisätä jatkossa vastaavia "monimutkaisia" kenttiä rajattomasti tekemällä kullekin oma "taulu".
Valitsemmekin siis tämän ratkaisun, eli annamme kullekin jäsenelle tunnusnumeron heti alusta pitäen. Itse ohjelman käyttösuunnitelmaan ei tässä vaiheessa tarvita muutoksia.
Käytännössä usein vielä annetaan harrastustiedostonkin jokaiselle riville oma juokseva id-numero.
Tehtävä 2.1 Ketkä harrastavat?
Kirjoita algoritmi joka relaatiomallin tapauksessa vastaa kysymykseen "Ketkä harrastavat harrastusta X".
2.8.4 XML-muotoinen tiedosto
Nykyisin on kovasti muotia, että jokainen ohjelma osaa lukea ja kirjoittaa XML-muotoista tiedostoa (Extensible Markup Language). Meidän ohjelmamme tiedosto voisi olla vaikka seuraavan näköinen XML-muotoisena:
kelmit.xml - kerho XML-muodossa
<?xml version="1.0"?>
<kerho>
<kerhonnimi>Kelmien kerho ry</kerhonnimi>
<jasenet>
<id>1</id>
<nimi>Ankka Aku</nimi>
<hetu>010245-123U</hetu>
<katuosoite>Paratiisitie 13</katuosoite>
<postinumero>12345</postinumero>
<postiosoite>ANKKALINNA</postiosoite>
<kotipuhelin>12-12324</kotipuhelin>
<harrastukset>
<harrastus>kalastus</harrastus>
<aloit>1955</aloit>
<viikossa>20</viikossa>
</harrastukset>
<harrastukset>
<harrastus>laiskottelu</harrastus>
<aloit>1950</aloit>
<viikossa>20</viikossa>
</harrastukset>
<harrastukset>
<harrastus>tyon pakoilu</harrastus>
<aloit>1952</aloit>
<viikossa>40</viikossa>
</harrastukset>
</jasenet>
<jasenet>
<id>2</id>
<nimi>Susi Sepe</nimi>
<hetu>020347-123T</hetu>
<postinumero>12555</postinumero>
<postiosoite>Takametsa</postiosoite>
<harrastukset>
<harrastus>possujen jahtaaminen</harrastus>
<aloit>1954</aloit>
<viikossa>20</viikossa>
</harrastukset>
<harrastukset>
<harrastus>kelmien kerho</harrastus>
<aloit>1962</aloit>
<viikossa>2</viikossa>
</harrastukset>
</jasenet>
<jasenet>
<id>4</id>
<nimi>Ponteva Veli</nimi>
<hetu>030455-3333</hetu>
<postinumero>12555</postinumero>
<postiosoite>Takametsa</postiosoite>
<harrastukset>
<harrastus>susiansojen rakentaminen</harrastus>
<aloit>1956</aloit>
<viikossa>15</viikossa>
</harrastukset>
</jasenet>
</kerho>Kuten edeltä nähdään, on XML varsin tuhlaileva tallennusmuoto. Sen käyttöä puoltaa lähinnä sen standardinmukaisuus. Tuon tiedoston voi lukea tulevaisuudessa vaikka millä ohjelmalla. Haittapuolena on työläämpi lukeminen omassa ohjelmassa. Tosin jos on tarkoitus selvitä vain ylläkuvatun mukaisesta tiedostosta, ei koodaus ole kovin paljon monimutkaisempaa kuin muidenkaan tiedostomuotojen kanssa. Lisäksi esim. Java-kieleen löytyy useita XML-jäsentimiä valmiiksi käytettävinä luokkina.
2.8.5 JSON-muotoinen tiedosto
Nykyisin erittäin suosittu muoto on JSON (JavaScript Object Notation). Se on XML:ää vähemmän tilaa tuhlaileva, mutta antaa lähes samat hyvät puolet.
{
"kerho": {
"kerhonnimi": "Kelmien kerho ry",
"jasenet": [
{
"id": "1",
"nimi": "Ankka Aku",
"hetu": "010245-123U",
"katuosoite": "Paratiisitie 13",
"postinumero": "12345",
"postiosoite": "ANKKALINNA",
"kotipuhelin": "12-12324",
"harrastukset": [
{
"harrastus": "kalastus",
"aloit": "1955",
"viikossa": "20"
},
{
"harrastus": "laiskottelu",
"aloit": "1950",
"viikossa": "20"
},
{
"harrastus": "tyon pakoilu",
"aloit": "1952",
"viikossa": "40"
}
]
},
{
"id": "2",
"nimi": "Susi Sepe",
"hetu": "020347-123T",
"postinumero": "12555",
"postiosoite": "Takametsa",
"harrastukset": [
{
"harrastus": "possujen jahtaaminen",
"aloit": "1954",
"viikossa": "20"
},
{
"harrastus": "kelmien kerho",
"aloit": "1962",
"viikossa": "2"
}
]
},
{
"id": "4",
"nimi": "Ponteva Veli",
"hetu": "030455-3333",
"postinumero": "12555",
"postiosoite": "Takametsa",
"harrastukset": [
{
"harrastus": "susiansojen rakentaminen",
"aloit": "1956",
"viikossa": "15"
}
]
}
]
}
}2.8.6 YAML
Nykyisin yksi käytetty muoto on myös YAML, jota käytetään paljon esimerkiksi TIMissä. YAML on kohtuullisen mukava käsin kirjoitettavaksi.
kerho:
kerhonnimi: Kelmien kerho ry
jasenet:
- id: '1'
nimi: Ankka Aku
hetu: 010245-123U
katuosoite: Paratiisitie 13
postinumero: '12345'
postiosoite: ANKKALINNA
kotipuhelin: 12-12324
harrastukset:
- harrastus: kalastus
aloit: '1955'
viikossa: '20'
- harrastus: laiskottelu
aloit: '1950'
viikossa: '20'
- harrastus: tyon pakoilu
aloit: '1952'
viikossa: '40'
- id: '2'
nimi: Susi Sepe
hetu: 020347-123T
postinumero: '12555'
postiosoite: Takametsa
harrastukset:
- harrastus: possujen jahtaaminen
aloit: '1954'
viikossa: '20'
- harrastus: kelmien kerho
aloit: '1962'
viikossa: '2'
- id: '4'
nimi: Ponteva Veli
hetu: 030455-3333
postinumero: '12555'
postiosoite: Takametsa
harrastukset:
- harrastus: susiansojen rakentaminen
aloit: '1956'
viikossa: '15'2.8.7 TOML
Yksi vaihtoehto on myös TOML. TOMLissa sisennykset eivät sinällään vaikuta ja siinä sisäkkäisyys hoidetaan kertomalla jokaisen "attribuutin" kohdalla sen isäsolmujen nimet. Tosin TOMLissakin saa sisentää.
[kerho]
kerhonnimi = "Kelmien kerho ry"
[[kerho.jasenet]]
id = "1"
nimi = "Ankka Aku"
hetu = "010245-123U"
katuosoite = "Paratiisitie 13"
postinumero = "12345"
postiosoite = "ANKKALINNA"
kotipuhelin = "12-12324"
[[kerho.jasenet.harrastukset]]
harrastus = "kalastus"
aloit = "1955"
viikossa = "20"
[[kerho.jasenet.harrastukset]]
harrastus = "laiskottelu"
aloit = "1950"
viikossa = "20"
[[kerho.jasenet.harrastukset]]
harrastus = "tyon pakoilu"
aloit = "1952"
viikossa = "40"
[[kerho.jasenet]]
id = "2"
nimi = "Susi Sepe"
hetu = "020347-123T"
postinumero = "12555"
postiosoite = "Takametsa"
[[kerho.jasenet.harrastukset]]
harrastus = "possujen jahtaaminen"
aloit = "1954"
viikossa = "20"
[[kerho.jasenet.harrastukset]]
harrastus = "kelmien kerho"
aloit = "1962"
viikossa = "2"
[[kerho.jasenet]]
id = "4"
nimi = "Ponteva Veli"
hetu = "030455-3333"
postinumero = "12555"
postiosoite = "Takametsa"
[[kerho.jasenet.harrastukset]]
harrastus = "susiansojen rakentaminen"
aloit = "1956"
viikossa = "15"Eri muotojen välisiä muunnoksia voi kokeilla esimerkiksi muuntimella:
Tehtävä 2.2 Mikä on tilaa säästävin tallennusmuoto
Laske mikä edellä esitetyistä vaihtoehtoisista tiedostomuodoista on tilaa säästävin kun rivinvaihtomerkin lasketaan vievän yhden merkin verran tilaa ja välilyönnit "unohdetaan". Laske karkeasti "merkkejä/jäsen".
2.9 Graafiset käyttöliittymät
Luultavammin nopein tapa käyttöliittymäsuunnittelijalle tai ohjelmoijalle on suunnitella graafinen käyttöliittymä kynän sijaan suoraan jollakin nykyaikaisella graafisella ohjelmointiympäristöllä. Tähän osaan sitten lisätään heti tai jälkeenpäin itse toiminnallisuus. Tällaisia työkaluja on esimerkiksi Eclipse (vaatii WindowBuilder pluginin), NetBeans, Visual Studio, Blend, C++Builder, Delphi ja myös muiden ohjelmointikielten resurssityökalut.
Ohjelma suunnitellaan nimenomaan "piirtämällä" käyttäjälle näkyvä käyttöliittymän osa. Tässä tilanteessa on mahdollista pitää jopa asiakas mukana, jolloin ohjelman vaatimukset ja suunnitelmat selkeytyvät molempiin suuntiin. Ohjelmasta saattaa puuttua jotain tärkeitä ominaisuuksia, se saattaa olla liian vaikea käyttää, eikä ole myöskään tavatonta että alustavasti ohjelmaan on suunniteltu jopa tarpeettomia osia. Tilanteessa kiteytyy pitkälti se miksi johdanto-osuudessa esitellyt ketterien menetelmien arvot ovat käytännössä niin toimivia.
2.9.1 Komponentit
Tyypillisesti käyttöliittymät koostuvat ns. komponenteista. Ohjelmointikielelle tehdyt valmiit käyttöliittymäkirjastot sisältävät joukon valmiita komponentteja, kuten ikkunoita, paneeleita, tai vaikkapa nappeja. Yleensä komponentit rakentuvat muutamasta erilaisesta tyypistä, joskin käytettyjen kirjastojen välillä saattaa olla jonkinlaisia eroja.
Ikkunat (Windows) ovat korkean tason komponentteja, jotka sisältävät muita komponentteja. Ohjelmassa on yleensä yksi pääikkuna, jolla tosin voi olla lapsia, eli toisia ikkunoita. Tyypillisesti tyhjä ikkuna sisältää yläpalkin, jossa on ikoni, tekstiä, ikkunan kokoon vaikuttavat pikanäppäimet ja rasti sulkemista varten. Ikkunan "tyhjä" osio koostuu säiliöstä.
Säiliöt (Containers) ovat ikkunoita matalamman tason komponentteja, joiden tehtävä on helpottaa muiden komponenttien ryhmittelyä erilaisten sijoitteluiden (layout) avulla. Monimutkaiset rakenteet saattavat vaatia useiden sisäkkäisten ja rinnakkaisten säiliöiden käyttöä.
Valikot (Menus) ovat tapa jäsennellä kontrolleja. Sijoitellaan usein ohjelman yläreunaan tai esimerkiksi hiiren oikean painikkeen taakse.
Kontrollit (Controls), kuten esimerkiksi napit, tekstikentät, muokattavat tekstikentät, edistymispalkit ja valintalaatikot, ovat tyypillisesti matalimman tason komponentteja, jotka toteuttavat jotakin täsmällistä toiminnallisuutta.

Komponenttien sijoittelussa ja niiden toiminnassa kannattaa matkia paljon muita ohjelmia. Toki valikkopalkki on mahdollista laittaa vaikka ikkunan alareunaan, mutta samalla varmasti kasvattaa käyttäjän kynnystä oppia ohjelman sujuva käyttö. Kannattaa myös miettiä ohjelman käyttötarkoitusta ja alustaa. Hiiri ole välttämättä ainoa tapa käyttää graafistakaan ohjelmaa, joten usein tarvittavaan ohjelmaan on hyvä olla jonkinlaisia käyttöä nopeuttavia pikanäppäimiä. Toisaalta helppokäyttöisimmänkään tietokoneohjelman käytettävyys tuskin siirtyy sellaisenaan kännykälle.
Swing oli käytössä ennen vuotta 2016 olleilla kursseilla. Luku 2.9 kannattaa silmäillä päällisin puolin ja tilalla kannattaa lukea vuonna 2016- SceneBuilder-sivut, joilla kerrotaan nykyisin käytössä olevasta JavaFX-kirjastosta.
2.9.2 Omat komponentit
On kuitenkin selvää, ettei valmis kirjasto voi tarjota suoraan kaikkea tarpeellista. Tähän on käytännössä kolme erilaista lähestymistapaa. Ensimmäinen - yleensä tarpeettoman työläs - ratkaisu on luoda tarvittavan toiminnallisuuden tarjoavat osa itse. Tällaisen komponentin pitää täyttää tietty määrä sille asetettuja vaatimuksia, jonka jälkeen se on käytettävissä käyttöliittymässä. Käytännöllisempää kuin tyhjästä aloittaminen usein onkin ylikirjoittaa ja laajentaa haluttu toiminnallisuus jo valmiista komponentista.
Ohjelmoinnissa hyvä nyrkkisääntö on, että samaa koodia ei kannata kirjoittaa kahdesti, vaan silloin se tulee refaktoroida esimerkiksi uuteen funktioon. Sama periaate toimii käyttöliittymien kohdalla. Kerho-ohjelmasta huomaamme, että jäsenten tiedot syötetään kenttiin, joissa vasemmalla puolella on tekstiä ja oikealla syötekenttä. Tällöinhän olisi kätevää, jos voisimme yhdistää nämä kaksi komponenttia yhdeksi kokonaisuudeksi. Tätä ratkaisua kutsutaan koostamiseksi. Käyttäessämme Javan Swing kirjastoa, voimme luoda esimerkiksi EditPanel -komponentin, jolla on vaihdettava tekstikenttä (JLabel) ja kirjoituskenttä (JTextField).

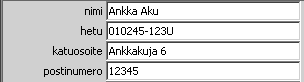
2.9.3 Graafisten käyttöliittymien suunnittelutyökalut
Käytettävästä ympäristöstä ja ohjelmointikielestä riippumatta käyttöliittymien suunnittelutyökalut muistuttavat hyvin paljon toisiaan. Esimerkkinä on käytetty Eclipseen asennettua WindowBuilder Pro -laajennusta Javan Swing-ympäristössä. Toiminnallisuuteen ei kuitenkaan syvennytä kuin pinnallisesti, koska työkalujen kehittyminen on nopeaa ja on mahdollista, että seuraavan version kohdalla tämäkin moniste on jo vanhentunut.
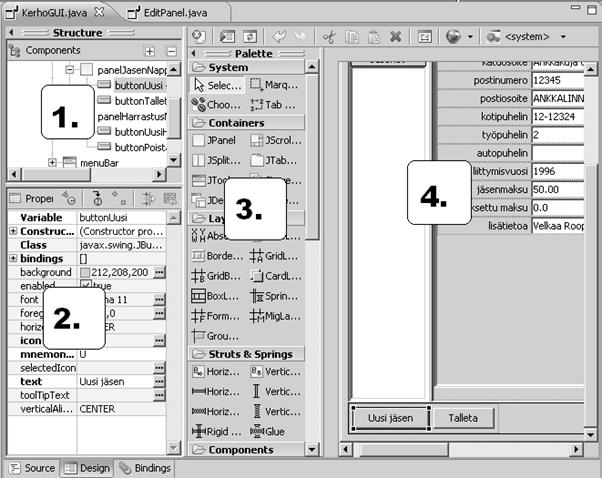
- Komponentit ja niiden sisäkkäinen rakenne (Structure). Kannattaa myös huomata että kaikki esikatselussa näkyvä, pääikkunaa myöten, on oma komponenttinsa.
- Ominaisuudet (Properties). Komponentin voi aktivoidaa joko rakenne- tai esikatseluikkunasta, jolloin sen ominaisuuksia voi muuttaa. Erilaisilla komponenteilla on toisistaan eroavat ominaisuudet. Tällaisia ominaisuuksia ovat esimerkiksi napissa lukeva teksti tai sen koko.
- Käytettävissä olevat työkalut ja komponentit (Palette). Kokoelma valmiita komponentteja, joita pystyy ottamaan käyttöön vetämällä halutun joko rakenne- tai esikatseluikkunaan
- Esikatselu (Preview).
Ohjelmointikieli ja siinä käytetyt kirjastot kyllä tuovat itse ohjelmakoodiin suuriakin eroja. Nykyään monet kirjastot käyttävät hyväkseen XML-tiedostoja, joihin tallennetaan ulkoasun ja komponenttien ominaisuudet samaan tapaan kuin html-tiedostoihin. Kurssilla käytetty Javan Swing-kirjasto ei kuitenkaan tätä mahdollisuutta ainakaan vielä tarjoa. XML:n käytöllä saavutetaan ainakin teoriassa parempi siirrettävyys eri järjestelmien ja laitteiden välillä. Eri tekniikoiden välillä ei kuitenkaan ole mitään yhtenäistä standardia, mutta XML-pohjaiset toteutukset on kuitenkin helpompi tulkita.
2.9.4 Tapahtumat
Käyttöliittymien toiminnallisuus toteutetaan tapahtumien (event) avulla. Hiiren oikea näppäin halutun komponentin päällä avaa valikon josta voi tutkia erilaisista käyttäjän toimista aktivoituvia tapahtumia. Oikean toiminnallisuuden kanssa pitää hieman miettiä. Miten painikkeen (Button) painaminen tapahtuu? Nopeasti voisi ajatella että kun hiiren vie painikkeen päälle ja painaa (MousePressed), niin on intuitiivista että seuraa tapahtuma. Näinhän ei kuitenkaan ole, vaan yleensä tapahtuma seuraa vasta sitten kun hiiri on painettu alas ja päästetty ylös (MouseClicked). Oikea tapahtuma painikkeelle on kuitenkin ActionPerformed, joka huomio myös näppäimistön avulla tehdyt valinnat.
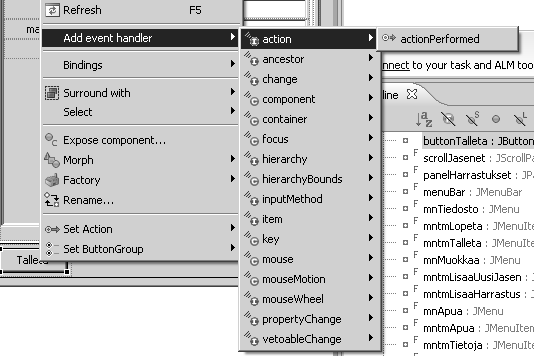
Tapahtuman luominen lisää seuraavat rivit koodiin. Ohjelma lisää painikkeelle uuden tapahtumakuuntelijan. Ohjelmakoodin toiminnan ymmärtäminen vaatii kuitenkin suhteellisen edistynyttä olio-ohjelmoinnin tietämystä, joten ei kannata säikähtää vaikka tekninen toteutus ei täysin aukeaisikaan.
buttonTallenna.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
//tähän voi kirjoittaa omaa ohjelmakoodia
tallenna();
}
});Lohkoon jossa kutsumme tallenna()-metodia olisimme tietysti voineet kirjoittaa halutun toiminnallisuuden suoraankin. Metodikutsu on kuitenkin parempi tapa, koska koodista tulee näin paremmin jäsenneltyä ja tulkittavaa. On myös mahdollista että tarvitsemme samaa toiminnallisuutta useampaan kertaan. Tällöin voisimme laittaa esimerkiksi CTRL+S pikanäppäinyhdistelmän osoittamaan samaan metodiin.
Tässä vaiheessa ohjelmamme ei osaa kuitenkaan vielä tallentaa mitään, joten metodin tehtävä on vain kertoa se erillisessä dialog-ikkunassa.
private void tallenna() {
JOptionPane.showMessageDialog(null, "ei osata vielä tallentaa");
}3. Algoritmin suunnittelu
Kirjettä jos kirjoittelet,
ulkomaille viestittelet,
tokko Ruohtia viskomassa,
turhaan sanoja kiskomassa?
Aloittanet aatoksilla,
kotokielellä pohtimalla,
viestin vääntöö valmistellen,
siistimiseksi sisällön.
Sama kaava koodatessa
kääntäjätä käskiessä
kotokieltä alkuun käytä
vasta sitten ruutuun täytä.
Algoritmit alkuun teeppä
koneen kimppuun vasta meeppä
kun selvillä on tarkka kaava
jopa kääntyy Cee ja Jaava.
Mitä tässä luvussa käsitellään?
- mikä on algoritmi
- vertailu ja lajittelu
- algoritmin kompleksisuus
- alkion etsiminen joukosta
Kun ohjelman suunnittelu on edennyt siihen pisteeseen, että tarvitaan yksityiskohtaisia algoritmeja, meneekin jo monella sormi suuhun.
Vaikeudet johtuvat taas liian hankalasta ajattelutavasta ja siitä, että algoritmi yritetään nähdä osana koko ohjelmaa. Tästä ajattelutavasta on luovuttava ja osattava määritellä tarvittava algoritmi omana kokonaisuutenaan, jota suunniteltaessa sitten unohdetaan kaikki muu.
3.1 Algoritmi
Algoritmi on se joukko toimenpiteitä, joilla annettu tehtävä saadaan suoritettua. Mieti esimerkiksi miten selostat kaverillesi ohjeet juna-asemalta opiskeluboxiisi.
Voit tietysti antaa ohjeet myös muodossa "Tule osoitteeseen Ohjelmoijankuja 17 B 5". Tämäkin on varsin hyvä algoritmi. Kaverin vain oletetaan nyt osaavan enemmän. Kaverin oletetaan osaavan etsiä katuluettelosta kadun paikka ja keksivän itse menetelmän tulla asemalta sinne. VL 2025: Siis ennenkuin kaikilla oli puhelimet ja niissä GPS, mitenkähän nykyihminen pärjäisi.
Toisaalta kaverisi saattaa hypätä taksiin ja sanoa kuskille osoitteen. Tämä on hyvä ja helppo algoritmi, mutta ehkä liian kallis opintovelkaiselle opiskelijalle. Mikäli algoritmia tarvitaan useasti, voidaan sitä myöhemmin parantaa tyyliin:
- kävele asemalta sinne ja sinne
- hyppää bussiin se ja se
- jneTarkennettu algoritmi voisi olla myös seuraavanlainen:
Valitse seuraavista:
1. Kello 7-20:
- kävele kirkkopuistoon
- nouse bussiin no 3 joka lähtee 15 yli ja 15 vaille
2. Sinulla on rahaa tai saat kimpan:
- ota taksi
3. Ei rahaa tai haluat ulkoilla:
- käveleEdellä eri kohdat eivät ole toisiaan poissulkevia. Kello voi olla 9 ja rahaakin voi olla, mutta siitä huolimatta halutaan kävellä. Hyvässä algoritmissa ei saa olla tällaisia epätäsmällisyyksiä, vaan ohjelmoijan tulee etukäteen jo päättää mitä missäkin tapauksessa tehdään. Esimerkiksi:
1. Jos haluat ulkoilla, niin
- kävele.
2. Muuten jos kello 7-20:
- kävele kirkkopuistoon
- nouse bussiin no 3 joka lähtee 15 yli ja 15 vaille
3. Muuten jos sinulla on rahaa tai saat kimpan:
- ota taksi
4. Muuten
- käveleTässäkin algoritmissa jää vielä kaverillekin tehtävää: Miten kävellään? Miten astutaan bussiin jne..
No tätä ei kaverille ehkä enää selostetakaan. Lapsille nämä asiat on aikanaan opetettu ja myöhemmin ne kuitataan yhdellä tai kahdella sanalla. Sama pätee ohjelmoinnissakin. Kerran tehtyä ei joka kerran pureksita uudelleen (vrt. aliohjelma)!
Tehtävä 3.1 Kävelyohjeet
Yritä kirjoittaa ohjeet siitä miten kävellään.
Kirjoita kaverillesi kävelyohjeet (missä käännytään, ei miten kävellään) rautatieasemalta asunnollesi.
3.2 Lajittelu yleisesti
Kerhon jäsenrekisteriä suunniteltaessa tulee jossakin kohtaa vastaan tilanne, jossa nimet tai osoitteet pitää pystyä lajittelemaan jollakin tavalla.
3.2.1 Nimien ja numeroiden vertaus
Jos osaamme lajitella numeroita, niin osaammeko lajitella nimiä? Vastaus on KYLLÄ. Mikä numeroiden lajittelussa on oleellista? Oleellista on tietää onko numero A pienempi kuin numero B. Miten tämä sitten soveltuu nimille? Jos osaamme päättää onko nimi A aakkosissa ennen kuin nimi B, on ongelma ratkaistu.
Verrataanpa erilaisia nimiä:
A: Kassinen Katto
B: Ankka AkuB on ensin aakkosissa. Miksi? Koska B:n ensimmäinen kirjain (A) on ennen nimen A ensimmäistä kirjainta (K).
A: Kassinen Katto
B: Karhukopla 701107Nytkin B on ensin. Siis miten vertaamme kahta nimeä?
Vertaamme nimiä merkki kerrallaan kunnes vastaan tulee erisuuret
kirjaimet. Kumpi erisuurista kirjaimista on aakkosissa ennen, määrää sen
kumpi nimistä on aakkosissa ennen.
Siinä meillä on algoritmi joka on varsin selvä. Jos algoritmi haluttaisiin vielä kirjoittaa "lausekieliseen" muotoon, niin se olisi suurin piirtein seuraavanlainen:
1. siirry kummankin nimen ensimmäiseen kirjaimeen
2. jos kummankin nimen viimeinen merkki on ohitettu, niin nimet ovat
samat
3. jos toisessa nimessä viimeinen merkki on ohitettu, niin se on ennen
aakkosissa
4. verrataan vuorossa olevia kirjaimia kummastakin nimestä
- jos samat, niin siirrytään seuraaviin kirjaimiin ja jatketaan kohdasta 2.
- jos erisuuret, niin se ensin aakkosissa, jonka kirjain on ensinTähän vielä pieni "viilaus enemmän strukturoidummaksi", niin meillä olisikin valmis (ali)ohjelma nimien vertaamiseksi.
3.2.2 Algoritmin sanallinen versio on kuvaavampi!
Vaikka esitimmekin algoritmin "lausekielisenä" kohdittain numeroituna, ei koskaan pidä unohtaa sitä ennen ollutta sanallista versiota, joka on selkeämpi kuvaus siitä ideasta, mitä tehdään!
Siis kirjoita aina ensin sanallinen kuvaava kuvaus algoritmista ja vasta sitten sen yksityiskohtainen "lausekielinen" versio!
3.2.3 Numeroiden järjestäminen
Näin ollen on aivan yksi lysti opettelemmeko järjestämään nimiä vai numeroita. Siksi paneudummekin seuraavassa numeroiden järjestämiseen. Kuulostaako vaikealta?
Otapa käteesi korttipakka ja ota sieltä esiin vaikkapa vain kaikki padat. Nyt sinulla on joukko "numeroita" (A=1, K=13, Q=12, J=11), yhteensä 13 kappaletta. Sekoita kortit! Yritä järjestää kortit suuruusjärjestykseen siten, ettet tarvitse pöytätilaa kuin yhden kortin verran, loput kortit pidät kädessäsi.
Millaisen algoritmin saat? Ehkäpä seuraavan (insertion sort):
Pöydällä on lajiteltujen kasa. Aluksi tietysti tyhjä. Ota
kädestäsi seuraava kortti ja laita pöydällä olevaan kasaan
omalle paikalleen. Jatka kunnes kädessä ei enää kortteja."Lausekielisenä":
1. ota kädessä olevan kasan päällimmäinen kortti
2. sijoita se pöydällä olevaan kasaan paikalleen
3. mikäli kortteja vielä jäljellä, niin jatka kohdasta 1.Kokeile itse
Sovella tässä siten, että otat päällimmäisen kortin Varasto-pakasta ja laitat ensimmäisen kortin "pöydälle" vasemmalle. Seuraavan kortin joko sen vasemmalle tai oikealle puolelle jne. Tarvittaessa tee tilaa uudelle paikalle siirtämällä muita pykälä oikealle.
Jos korteilla on sama numeroarvo, katso seuraavaksi maa järjestyksessä: ♣ (risti) < ♠ (pata) < ♦ (ruutu) < ♥ (hertta). Eli esim ♠4 < ♦4.

Algoritmisi voi olla myös seuraava (selection sort):
Etsitään aina pienin kortti ja laitetaan se pöydälle olevan
kasan päällimmäiseksi. Jatketaan kunnes kädessä olevat
kortit on loppu.Eli "lausekielisenä":
1. etsi kädessäsi olevista korteista pienin
2. laita se pöydällä olevan pinon päällimmäiseksi
3. mikäli vielä kortteja jäljellä, niin jatka kohdasta 1.Kokeile itse
Sovella niin, että laita punainen osoitin vasemmanpuoleisin kortin kohdalle (merkki järjestyksessä olevista). Sitten siirrä musta pienimmän punaisen kohdalla tai sen oikealle puolella olevan kohdalle. Paina Vaihda. Siirrä punaista pykälä oikealle ja toista. Eli edellä oleva "pöydällä oleva pino" on se punaisen vasemmalle puolen oleva osuus.

Tehtävä 3.2 Muita lajittelualgoritmeja
Mitä muita mahdollisia "lajittelumenetelmiä" keksit?
Siinä eräitä ratkaisuja tähän "hirveän vaikeaan" ongelmaan. Ratkaisuissa on tiettyjä huonoja puolia, mutta ratkaisut ovat todella yksinkertaisia ja jokaisen itse keksittävissä.
Tehtävä 3.3 Algoritmin kompleksisuus
Mikäli kahden kortin vertaaminen lasketaan yhdeksi "operaatioksi", niin kuinka monta "operaatiota" joudumme tekemään, jotta pakka on lajiteltu Selection Sortilla?
Edellisen tehtävän vastausta sanotaan algoritmin kompleksisuudeksi.
Tehtävä 3.4 Lajittelujärjestys
Edellinen algoritmi (selection sort) toimi siten, että kortit jäivät pöydälle suurin päällimmäiseksi (kokeiluissa oikeaan reunaan). Miten algoritmia pitää muuttaa, jotta pienin saataisiin päällimmäiseksi?
Ei siis ole suurtakaan väliä pitääkö lajitella nouseva vai laskeva järjestys!
3.2.4 Kuplalajittelu
Kokeillaanpa vielä erästä algoritmia: Sotke kortit kädessäsi uudelleen.
Bubble sort:
Vertaa aina kahta peräkkäistä korttia keskenään. Mikäli ne
ovat väärässä järjestyksessä, vaihda ne keskenään. Kun koko
pakka on käyty lävitse, aloita alusta ja jatka kunnes yhtään
kertaa ei tarvitse vaihtaa peräkkäisiä kortteja.Kokeile itse
Sovella niin, että laitat punaisen vasemmanpuolimmaiseen korttiin ja mustan sen oikealle puolelle. Jos ne ovat väärässä järjestyksessä, vaihda. Sitten siirrä molempia yksi oikealle ja toista uudelleen. Kun musta oikeassa reunassa, niin palaa alkuun ja tee uudelleen kunnes järjestyksessä.

Tehtävä 3.5 Kuplalajittelu
Tuleeko pakka järjestykseen tällä algoritmilla? Voidaanko algoritmia nopeuttaa mitenkään? Kirjoita algoritmista "lausekielinen" versio.
3.2.5 Lajittelu avaimen mukaan
Kirjoita nyt joukko pahvilappuja, joissa kussakin on henkilön nimi, osoite ja puhelinnumero.

Sekoita laput ja kokeile toimiiko edelliset algoritmit mikäli laput järjestetään nimien mukaan. Ai tyhmä ehdotus! Tässä se onkin ohjelmoinnin vaikeus. Asiat ovat yksinkertaisia! Eiväthän ne osoitteet siellä lajittelua sotke.
Mikäli laput järjestetään nimen mukaan, sanotaan nimen olevan lajitteluavaimena. Lajitteluavaimeksi voitaisiin valita myös osoite tai puhelinnumero. Mikäli kahdella henkilöllä olisi sama nimi, voitaisiin nämä kaksi järjestää osoitteen perusteella. Tällöin lajitteluavain muodostuisi merkkijonosta johon olisi yhdistettynä nimi ja osoite.
3.2.6 Algoritmin parantaminen
Kaikki edelliset algoritmit ovat kompleksisuudeltaan normaalitapauksessa samanlaisia.
Tehtävä 3.6 Loppuminen erikoistapauksessa
Mikä edellisistä algoritmeista loppuu nopeasti, mikäli kortit jo olivat järjestyksessä?
Ohjelman toimintaan saattamisen kannalta olisi riittävää löytää jokin toimiva algoritmi. Myöhemmin, mikäli ohjelman toiminta todetaan hitaaksi ko. algoritmin kohdalta, voidaan algoritmia yrittää tehostaa. Lajittelussa tehostus saattaisi olla vaikkapa QuickSort (mukana mm. C-kielen standardikirjastossa).
Tehtävä 3.7 QuickSortin kompleksisuus
Jos algoritmin kompleksisuus on esimerkiksi \(2n^2+n\), sanotaan että kompleksisuus on \(O(n^2)\), eli usein kiinnostaa vain kompleksisuuden suurin "potenssi". QuickSortin keskimääräinen kompleksisuus on \(O(n \log_2 n)\). On olemassa myös erikoistapauksissa toimivia lajitteluja, joissa kompleksisuus on \(O(n)\). Piirrä kuva jossa on Selection Sortin, QuickSortin ja lineaarisen lajittelun käyttämä "aika" piirrettynä lajiteltavien alkioiden (n=10,100,1000,10000,1000000) funktiona.
Tehtävä 3.8 Lisäys oikealle paikalleen vaiko lisäys loppuun ja lajittelu?
Tutki kumpiko on työmäärältään edullisempaa jos järjestettyyn taulukkoon tulee lisättäväksi suuri määrä uusia alkiota
1. lisätä alkio aina taulukkoon oikealle paikalleen
2. lisätä alkio aina taulukon loppuun ja kun kaikki alkiot on
lisätty, niin lajitella taulukko3.3 Algoritmin tarkentaminen
Edellisissä lajittelualgoritmeissa oli vielä muutamia aukkopaikkoja!
Etsi pienin? Laita oikealle paikalleen?3.3.1 Pienimmän etsiminen
Miten kädessä olevista korteista voidaan etsiä pienin. Yksi mahdollisuus on kuljettaa "pienin ehdokasta" läpi koko pakan. Mikäli matkan varrelta löytyy parempi ehdokas, otetaan tämä tilalle. Edellä mainittu kuplalajittelu korjattuna perustuu nimenomaan tähän ideaan.
Entä jos kädessä olevien korttien järjestystä ei haluta muuttaa? Voisimme menetellä esimerkiksi seuraavasti (alkuarvaus ja arvauksen korjaaminen):
0. vedä kädessä olevan pakan ylin kortti hieman esille
ota ensimmäinen kortti tutkittavaksi
1. vertaa tutkittavaa korttia ja esiinvedettyä korttia
2. mikäli tutkittava on pienempi, vedä se esiin ja työnnä
edellinen takaisin
3. siirry tutkimaan seuraavaa korttia ja jatka kohdasta 1.
kunnes olet tutkinut koko pakanKokeile itse
Sovella niin, että laitat punaisen vasemmanpuolimmaiseen korttiin ja mustan sen oikealle puolelle. Jos mustan kohdalla pienempi, siirrä punainen mustan kohdalle. Siirrä mustaa oikealle. Jatka kunnes musta ohi korteista. Voit tehdä näppäimistöltä niin, että nuoli oikealle siirtää mustaa ja r siirtää punaisen mustan kohdalle.

Kokeile itse
Kokeile miten voit etsiä pienimmän "sokkona".
3.3.2 Paikalleen sijoittaminen
Miten kortti sijoitetaan paikalleen jo lajiteltuun kasaan? Esimerkiksi seuraavasti:
0. laita uusi kortti päällimmäiseksi lajiteltuun kasaan
1. vertaa uutta ja seuraavaa
2. mikäli väärässä järjestyksessä, niin vaihda ne keskenään
ja jatka kohdasta 1.Kokeile itse
Tässä ainakin ensimmäiset 5 korttia vasemmalta ovat järjestyksessä. Sovelletaan edellistä siten, että tulkitaan lajiteltujen kasaksi ne 5 ensimmäistä ja kuudes kortti uudeksi. Laita punainen osoitin 5. kortin kohdalle ja musta 6. kohdalle, niin ollaan em algoritmin "alkutilanteessa". Sitten kuljeta Vaihda-painikkeella ja punaista ja mustaa aina pykälä vasemmalle siirtäen paikassa 6 ollut kortti kohdalleen. Toki se voi olla tuurilla paikallaan hetikin. Voit käyttää myös näppäimiä space (vaihda) ja Ctrl-nuoli vasemmalle (siirrä punaista ja mustaa vasemmalle). Toista sitten vielä kuljettamalla 7. ja sitetn 8. kortti paikalleen.
3.4 Haku järjestetystä joukosta
Usein tulee vastaan myös tilanne, jossa tietyn henkilön tiedot pitäisi hakea esimerkiksi nimen mukaan. Mikäli valittu tietorakenne on järjestetty nimen mukaan, voidaan hakemisessa käyttää vaikkapa puolitushakua.
Nimen hakeminen ei taas poikenne kortin etsimisestä järjestetystä korttipakasta vai mitä?
3.4.1 Suora haku
Kun kortit ovat järjestämättä, niin miten löydät haluamasi kortin?
Ota seuraava kortti. Mikäli etsittävä niin lopeta, muuten ota taas
seuraava.Algoritmi on OK 13 kortille, mutta kokeilepa Äystön etsimistä puhelinluettelosta tällä algoritmilla (muista lukea jokainen nimi ennen Äystöä)!
3.4.2 Puolitushaku
Mikäli 13 korttiasi on järjestyksessä ja sinun pitäisi mahdollisimman vähällä pläräämisellä löytää vaikkapa pata 4, niin miten voisit menetellä?
1. laita pakka pöydälle kuvapuolet ylöspäin
2. laita pakka puoliksi
3. laita molemmat pakat pöydälle kuvapuolet ylöspäin
4. kummassako kasassa etsittävä on?
5. heitä se pakka pois jossa etsittävä ei ole
6. jos etsittävä ei päällimmäinen, niin jatka kohdasta 1.Vaikuttaa tyhmältä 13 kortille, mutta kokeilepa 1000 kortilla! Tai kokeile nyt etsiä ÄYSTÖÄ puhelinluettelosta tällä algoritmilla.
Tehtävä 3.9 Puolitushaku
Kirjoita puolitushausta kunnon "lausekielinen versio" kun meillä on sivunumeroitu kirja, jonka kullakin sivulla on täsmälleen yhden henkilön tiedot. Sivunumeroita kirjassa on N-kappaletta. Aloitat sivuista S1=0 ja S2=N+1. Miten jatkat mikäli pitää etsiä nimi NIMI?
Tehtävä 3.10 Puolitushaun kompleksisuus
Mikä on puolitushaun kompleksisuus?
3.5 Yhteenveto
Tätä on ohjelmointi! Kykyä (ja rohkeutta) sanoa selvät asiat täsmällisesti. Jossain vaiheessa vaihdamme vain täsmällisyyden astetta ja "lausekielen" sijasta siirrymme käyttämään oikeata lausekieltä, esim. Java-kieltä. Nämä omatekoiset algoritmit kannattaa kuitenkin säilyttää ja kirjata näkyviin todellisen ohjelman kommentteihin. Arviot algoritmin nopeudesta kannattaa myös laittaa kommentteihin, jotta jälkeenpäin on helpompi etsiä jo tekovaiheessa hitaaksi epäiltyjä kohtia. Miksi jättää seuraavalle lukijalle sama tehtävä ihmeteltäväksi, jos olemme sen toteutuksen jo jonnekin kirjanneet.
Algoritmit kannattaa testata huolellisesti jossain tutussa ympäristössä. Hyvin moni ohjelmointiongelma vektoreiden (=taulukko, =kasa kortteja, =ruutupaperi, =sivunumeroitu kirja jne.) kanssa samaistuu johonkin jokapäiväiseen ilmiöön. Kuten etsiminen puhelinluettelosta, korttipakan järjestäminen jne. Yritä etsiä näitä yhteyksiä ja kokeile ensin ratkaista ongelma tällä tavoin. Siirrä ratkaisu sitten "lausekielelle" ja lopulta ohjelmointikielelle.
Äläkä yritä liikaa, vaan jaa aina ongelma pienempiin osiin, kunnes tulee vastaan sen kokoisia osaongelmia, jotka osataan ratkaista! Tällaista osaongelman ratkaisijaa sanotaan ohjelmointikielessä aliohjelmaksi.
Kun osaongelma on ratkaistu, unohda se miten sen ratkaisija toimii ja käsittele ratkaisijaa vain yhtenä yksinkertaisena toimenpiteenä (vrt. aikaisempi kävelyesimerkki). Tämä on myös eräs ohjelmoinnin "vaikeus". Kirjoittaja haluaa nähdä kaikkien osien toiminnan yhtäaikaisesti. Tämä on kuitenkin mahdotonta. Siis kun jokin osa tekee hommansa, niin tehköön se sen miten tahansa.
Huono on johtaja joka kyttää koko ajan alaisiaan, eikä luota siihen, että nämä tekevät heille annetun tehtävän. Tässä mielessä ohjelmointia voisi verrata yrityksen johtamiseen: Johtaja jakaa koko yrityksen pyörittämisessä tarvittavia tehtäviä alaisilleen (aliohjelmille). Nämä saattavat edelleen jakaa joitakin osatehtäviä omille alaisilleen (aliohjelma kutsuu toista aliohjelmaa) jne. Johtaja (=ohjelmoija ja pääohjelma) kokoaa alaisten tekemän työn toimivaksi kokonaisuudeksi ja firma tuottaa.
Tehtävä 3.11 Kumin paikkaus
Kirjoita algoritmi polkupyörän kumin paikkaamiseksi.
Tehtävä 3.12 Sunnuntai-ilta
Kirjoita algoritmi sunnuntai-illan viettoa varten (muista että ohjelmoinnin demot on maanantaina).
Tehtävä 3.13 Onkiminen
Kirjoita algoritmi 10 ei-alimittaisen kalan onkimiseksi mato-ongella.
Tehtävä 3.14 Järjestyksen kääntäminen päinvastaiseksi
Kirjoita algoritmi pöydälle levitetyn 13 kortin kääntämiseksi päinvastaiseen järjestykseen.
Kokeile itse
Sovella niin, että laitat punaisen vasemmanpuolimmaiseen korttiin ja mustan sen oikealle puolelle. Jos mustan kohdalla pienempi, siirrä punainen mustan kohdalle. Siirrä mustaa oikealle. Jatka kunnes musta ohi korteista. Voit tehdä näppäimistöltä niin, että d siirtää punaista, nuoli vasemmalle siirtää mustaa space vaihtaa.
4. Algoritmeissa tarvittavia rakenteita
Tarvitaan nyt silmukoita,
kaiken maailman taulukoita,
eri ehtoja kummastella,
aliohjelmia aavistella.
Mitä tässä luvussa käsitellään?
- silmukat ja valintalauseet
- totuustaulut
- pöytätesti
- muuttujat
- taulukot
- osoittimet
Vaikka jatkossa keskitymmekin oliopohjaiseen ohjelmointiin, tarvitaan yksittäisen olion metodin toteutuksessa algoritmeja. Riippumatta käytettävästä ohjelmointikielestä, tarvitaan algoritmeissa aina tiettyjä samantyyppisiä rakenteita.
Käsittelemme seuraavassa tyypilliset rakenteet nopeasti lävitse. Tarvitsisimme asioille enemmänkin aikaa, mutta otamme asiat tarkemmin esille käyttämämme ohjelmointikielen opiskelun yhteydessä. Lukijan on kuitenkin asioita tarkennettaessa syytä muistaa, ettei rakenteet ole mitenkään sidottu ohjelmointikieleen. Vaikka ne näyttäisivät kielestä täysin puuttuvankin (esim. assembler), voidaan ne kuitenkin lähes aina toteuttaa.
4.1 Ehtolauseet
Triviaaleja algoritmeja lukuun ottamatta algoritminen suoritus tarvitsee ehdollisia toteutuksia:
Jos kello yli puolenyön ota taksi
muuten mene linja-autollaEhtolauseita voi ehtoon tulla useampiakin ja tällöin on syytä olla tarkkana sen kanssa, mihin ehtoon mahdollinen muuten-osa liittyy:
Jos kello 00.00-07.00
Jos sinulla on rahaa niin ota taksi
muuten kävele
muuten mene linja-autollaTehtävä 4.1 Ajanlisäys
Jos sinulla on muuttujassa t tunnit ja muuttujassa m minuutit, niin kirjoita algoritmi miten lisäät n minuuttia kellonaikaan t:m.
Tehtävä 4.2 Postimaksu
Kirjoita algoritmi g-painoisen kirjeen postimaksun määräämiseksi (saat keksiä hinnaston itse).
4.2 Valintalauseet
Usein ehtoja kasaantuu niin paljon, että peräkkäiset ja sisäkkäiset ehtolauseet muodostavat varsin sekavan kokonaisuuden. Tällöin voi olla helpompi käyttää valintalausetta:
Yritys myy verkkokaupasta erilaisia tietoteknisiä tuotteita. Jokaisella tuoteryhmällä on vastaava henkilö, jonka sähköpostiin halutaan ohjata oikeat tukipyynnöt. Käyttäjä valitsee tuotekategorian alasvetovalikosta, jonka perusteella pyyntö lähtetään oikealle henkilölle.
Tietokoneet -> Matti
Puhelimet -> Marko
Kamerat -> Terttu
Audio,Muut -> NikoTehtävä 4.3 Korvaaminen ehtolauseilla
Mieti kuinka valintalauseen logiikka korvattaisiin ehtolauseiden avulla.
4.3 Silmukat
Hyvin usein algoritmi tarvitsee toistoa: Esimerkiksi ohjeet (vuokaavio) hiekkarannalla toimimiseksi jos nenä näyttää merelle päin:
Ehtolause voi olla silmukan alussa, tällöin on mahdollista, ettei silmukan runkoa tehdä yhtään kertaa. Ehto voi olla myös silmukan jälkeen, jolloin silmukan runko tehdään vähintään yhden kerran. Joissakin kielissä on lisäksi mahdollisuus silmukan rungon keskeltä poistuminen.
Silmukoihin liittyy aina ohjelmoinnin eräs klassisimmista vaaroista: päättymätön silmukka! Tämän takia silmukoita tulee käsitellä todella huolella. Eräs oleellinen asia on aina muistaa suorittaa silmukan rungossa jokin silmukan lopetusehtoon vaikuttava toimenpide. Mitä tapahtuu muuten?
Myös silmukan suorituskertojen lukumäärän kanssa tulee olla tarkkana. Silmukka tulee helposti suoritettua yhden kerran liikaa tai yhden kerran liian vähän.
Tehtävä 4.4 Uiminen
Mitä eroa on kahdella edellä esitetyllä "uimaan-meno" -algoritmilla? Mitä ehtoja algoritmiin voisi vielä lisätä?
Tehtävä 4.5 Ynnää luvut 1-100
Kirjoita algoritmi lukujen 1-100 yhteenlaskemiseksi sekä do-while- että while -silmukan avulla.
4.4 Muuttuja-käsite
Algoritmeissa tarvitaan usein muuttujia.
kellonaika
rahan määrä4.4.1 Yksinkertaiset muuttujat
Yksinkertaisessa tapauksessa muuttuja voi olla yksinkertaista tyyppiä kuten kellonaika (jos ilmaistu minuutteina), rahasumma jne.
Yksinkertainen luvun jaollisuuden testausalgoritmi voisi olla vaikkapa seuraavanlainen:
Jaetaan tutkittavaa lukua jakajilla 2,3,5,7...luku/2.
Jos jokin jako menee tasan, niin ei alkuluku:
0. Laita jakaja:=2, kasvatus:=1,
Jos luku=2 lopeta, alkuluku
1. Jaa luku jakajalla. Meneekö jako tasan?
- jos menee, on luku jaollinen jakajalla, lopeta
2. Kasvata jakajaa kasvatus arvolla (jakaja:=jakaja+kasvatus)
3. Kasvatus:=2; (koska parillisilla ei kannata enää jakaa)
4. Onko jakaja<luku/2?
- jos on, niin jatka kohdasta 1
- muuten lopeta, luku on alkulukuTehtävä 4.6 Vuokaavio
Piirrä jaollisuuden testausalgoritmista vuokaavio.
4.4.2 Pöytätesti
Hyvin usein algoritmi kannattaa pöytätestata. Pöytätesti alkaa kirjoittamalla sarakkeiksi kaikki algoritmissa esiintyvät muuttujat. Muuttujiksi voidaan kirjoittaa myös algoritmissa esiintyviä ehtoja. Tällainen muuttuja voi saada arvon kyllä tai ei. Pöytätestin riveiksi kirjoitetaan algoritmin eteneminen vaiheittain. Sarakkeisiin muuttujille kirjoitetaan uusia arvoja vain niiden muuttuessa.
Testataan esimerkiksi edellisen esimerkin algoritmi:
+-----+------+------+--------+--------+-------+---------+-----------+
|askel| Luku |Jakaja|Kasvatus| Luku/ | Jako | Jakaja< | Tulostus |
| | | | | Jakaja | tasan?| Luku/2? | |
+=====+======+======+========+========+=======+=========+===========+
| 0 | 25 | 2 | 1 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 12.500 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 3 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 3<12.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 8.333 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 5 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 5<12.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 5.000 | kyllä | | Jaollinen |
| | | | | | | | 5:llä |
+-----+------+------+--------+--------+-------+---------+-----------++-----+------+------+--------+--------+-------+---------+-----------+
|askel| Luku |Jakaja|Kasvatus| Luku/ | Jako | Jakaja< | Tulostus |
| | | | | Jakaja | tasan?| Luku/2? | |
+=====+======+======+========+========+=======+=========+===========+
| 0 | 23 | 2 | 1 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 11.500 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 3 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 3<11.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 7.667 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 5 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 5<11.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 4.600 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 7 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 7<11.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 3.286 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 9 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 9<11.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 2.556 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 11 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 11<11.5 | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 1 | | | | 2.091 | ei | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 2 | | 13 | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 3 | | | 2 | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+
| 4 | | | | | | 13>11.5 | Alkuluku |
| | | | | | | | |
+-----+------+------+--------+--------+-------+---------+-----------+Usein pöytätesti antaa hyviä vinkkejä myös algoritmin jatkokehittelylle. Käytännön työssä osa pöytätestistä voidaan suorittaa debuggereiden avulla. Joskus kuitenkin voi olla niin paljon esitietoa algoritmille, että tarvittavan testiohjelman rakentaminen voi olla työlästä. Pöytätestihän voidaan aloittaa minkälaisesta alkutilasta tahansa. Samoin yksi pöytätestin etuja on siitä jäävä historia. Usein debuggerit näyttävät vain yhden ajanhetken tilanteen, siis yhden pöytätestin rivin kerrallaan.
Tehtävä 4.7 Algoritmin parantaminen
Tarvitsisimmeko algoritmin kohtaa 4 lainkaan? Voitaisiinko algoritmin lopetus hoitaa muuten?
Tehtävä 4.8 Pöytätesti
Pöytätestaa edellinen algoritmi kun syöttönä on luku 121.
Pöytätestaa molemmat Ynnää luvut 1-100 -algoritmisi versiona Ynnää luvut 1-6.
4.4.3 Yksiulotteiset taulukot, alkiot rivissä
Tutkikaamme aikaisempia korttipakkaesimerkkejämme! Nyt tietorakenteeksi ei enää riitäkään pelkkä yksi muuttuja. Mikäli pakasta on otettu esiin pelkät padat, tarvitsisimme 13 muuttujaa. Näiden kunkin nimeäminen erikseen olisi varsin työlästä.
Tarvitsemme siis jonkin muun tietorakenteen. Mahdollisuuksia on useita: listat, jonot, pinot ja taulukot. Ohjelmoinnin alkuvaiheessa taulukot ovat tietorakenteista helpoimpia, joten keskitymme niihin aluksi.
Varataan pöydältä tilaa leveyssuunnassa 13 kortille. Varattua tilaa voimme nimittää taulukoksi tai vektoriksi. Taulukon yksi alkio on yhdelle kortille varattu paikka. Taulukon yhden alkion sisältö on se kortti, joka on siinä paikassa.
Mikäli numeroimme varatut paikat vaikkapa 0:sta alkaen vasemmalta oikealle, on meidän korteillamme osoitteet 0-12:

Nyt voimme käsitellä yksittäisiä kortteja aivan kuin ne olisivat yksittäisiä muuttujia. Viittaamme tiettyyn korttipaikkaan (taulukon alkioon) sen indeksillä (olkoon taulukon nimi kortit):
paikassa kortit[5] meillä on pata 9
paikassa kortit[8] meillä on pata akkaMinkälaisia algoritmeja tulee vastaan taulukoita käsiteltäessä? Esim. ♠9:n siirtäminen taulukon viimeiseksi vaatisi ♠4:en siirtämistä paikkaan 5. ♠6:en siirtämistä paikkaan 6, ♠Q:n siirtämistä paikkaan 7 jne. Näin loppuun saataisiin raivatuksi paikka ♠9:lle.
Lajittelun ilman valtaisaa korttien siirtelyä voisimme hoitaa seuraavasti:
0. laita alku paikkaan 0
1. etsi alku paikasta lähtien pienin kortti
2. vaihda pienin ja paikassa alku oleva kortti
3. alku:=alku+1
4. mikäli alku<suurin indeksi, niin jatka 1Sovitaan, että ässä=1. Nyt pienimmän kortin etsimisalgoritmi voisi olla seuraava:
0. Alkuarvaus: pien.paikka:=alku, tutki:=alku
1. Jos kortit[tutki] < kortit[pien.paikka]
niin pien.paikka:=tutki
2. tutki:=tutki+1
3. Jos tutki<=suurin indeksi, niin jatka 1.Voisimme vielä pöytätestata algoritmin (pp = pienimmän paikka ⇧, t = tutkittava paikka):
| as- kel | pp ⇧ | tut ki t | Kor tit 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | [t]< [pp] | tutki < suur ind |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | ♠7 | ♠3 | ♠K | ♠2 | ♠5 | ♠9 | ♠4 | ♠6 | ♠Q | ♠10 | ♠J | ♠A | ♠8 | ||
| 1 | ⇧t | 7<7 ei | |||||||||||||||
| 2&3 | 1 | juu | |||||||||||||||
| 1 | 1 | ⇧ | t | 3<7 juu | |||||||||||||
| 2&3 | 2 | juu | |||||||||||||||
| 1 | ⇧ | t | K<3 ei | ||||||||||||||
| 2&3 | 3 | juu | |||||||||||||||
| 1 | 3 | ⇧ | t | 2<3 juu | |||||||||||||
| 2&3 | 4 | juu | |||||||||||||||
| 1 | ⇧ | t | 5<2 ei | ||||||||||||||
| 2&3 | 5 | juu | |||||||||||||||
| 1 | ⇧ | t | 9<2 ei | ||||||||||||||
| 2&3 | 6 | juu | |||||||||||||||
| 1 | ⇧ | t | 4<2 ei | ||||||||||||||
| 2&3 | 7 | juu | |||||||||||||||
| 1 | ⇧ | t | 6<2 ei | ||||||||||||||
| 2&3 | 8 | juu | |||||||||||||||
| 1 | ⇧ | t | Q<2 ei | ||||||||||||||
| 2&3 | 9 | juu | |||||||||||||||
| 1 | ⇧ | t | 10<2 ei | ||||||||||||||
| 2&3 | 10 | juu | |||||||||||||||
| 1 | ⇧ | t | J<2 ei | ||||||||||||||
| 2&3 | 11 | juu | |||||||||||||||
| 1 | 11 | ⇧ | t | A<2 juu | |||||||||||||
| 2&3 | 12 | juu | |||||||||||||||
| 1 | ⇧ | t | 8<A ei | ||||||||||||||
| 2&3 | 13 | ei |
Tehtävä 4.9 Lajittelun testaus
Oletetaan, että pienimmän etsimisalgoritmi toimii. Pöytätestaa edellä esitelty lajittelualgoritmi edellisen pöytätestin mukaisella korttien järjestyksellä.
Onko tämä insertion sort? Missä on lajiteltujen kasa ja missä lajittelemattomien?
Tehtävä 4.10 Korttien poisto
Kirjoita algoritmi kuvakorttien poistamiseksi taulukosta käyttäen indeksejä.
4.4.4 Osoittimet
Edellisessä pöytätestissä merkitsimme pienen merkin niiden korttien kohdalle, joita kunakin hetkenä tutkimme. Kun tutkimme esimerkiksi paikoissa 3 ja 10 olevia kortteja (P2 ja PJ) voisimme sanoa, että muuttuja pien.paikka osoitti korttiin pata 2 ja muuttuja tutki korttiin pata jätkä. Näin ollen voisimme oikeastaan sanoa, että (indeksi)muuttujat pien.paikka ja tutki ovat osoittimia korttipakkaan. Niiden osoittamassa paikassa (indeksit 3 ja 10) on tietyt kortit (P2 ja PJ).
Lajittelualgoritmi voitaisiin lausua esimerkiksi:
0. levitä kortit rinnakkain pöydälle
osoita vasemman käden etusormella ensimmäiseen korttiin
1. etsi vasemman käden osoittamasta kohdasta alkaen oikealle
pienin kortti ja osoita sitä oikean käden etusormella
2. vaihda etusormien kohdalla olevat kortit keskenään
3. siirrä vasemman käden etusormea yksi kortti oikealle päin
4. mikäli vasen sormi vielä kortin päällä, jatka kohdasta 1.
Osoittimen ja indeksin ero on siinä, että osoittimen tapauksessa emme yleensä koskaan ole kiinnostuneita itse osoittimen arvosta (osoitteesta, siitä indeksistä missä kohdin olemme menossa), vaan osoittimen osoittaman paikan sisällöstä (sormen kohdalla olevan kortin arvo tai ei korttia). Indeksejä käsitellessämme tutkimme monesti myös itse indeksin arvoa
tutki=3 -> kortit[tutki]==P2.Osoitin voi tarvittaessa osoittaa myös itse taulukon ulkopuolelle. Mikäli kirjoittaisimme pöydälle numeroita, voisimme osoittaa sormella yhtä hyvin pöydälle kirjoitettuja numeroita (älkää hyvät ihmiset nyt töhrätkö pöytää!) kuin pöydälle levitettyjä kortteja (taulukon alkioita).
Siis indeksit liittyvät kiinteästi taulukoihin ja osoittimet voivat liittyä mihin tahansa tietorakenteisiin alkaen yksinkertaisesta muuttujasta päätyen monimutkaisen lista- tai puurakenteen alkioon.
Javassa tällä tavalla käyttäytyviä osoittimia vastaavat iteraattorit. Itse asiassa Javan kaikki "oliomuuttujat" ovat osoittimia, niitä sanotaan vaan viitteiksi. Erona esimerkiksi C++:n osoittimiin on se, että Javan viitteitä ei voi muuttaa muuta kuin osoittamaan toista alkiota. Eli Javan viitteillä käsky "siirry yksi alkio eteenpäin" on mahdotonta. Javan iteraattoreilla tämä sen sijaan onnistuu. C++:ssa on aidot osoittimet - joiden kanssa voi helposti myös möhliä laittamalla osoittimen osoittamaan paikkaan johon se ei saisi osoittaa). C++:ssa on myös viitteet (reference), joita tosin ei voi siirtää mihinkään luomisen jälkeen. C++:n iteraattorit muistuttavat jopa syntaksiltaan C++:n osoittimia ja itse asiassa C++:n osoitin käy algoritmissa paikkaan, johon tarvitaan iteraattori.
Tehtävä 4.11 Korttien poisto osoittimia käyttäen
Kirjoita algoritmi kuvakorttien poistamiseksi taulukosta käyttäen osoittimia.
Pöytätestaa algoritmi.
4.4.5 Moniulotteiset taulukot
Yksiulotteista taulukkoa voidaan verrata rivitaloon tai ruutupaperin yhteen riviin. Kaksiulotteinen taulukko on vastaavasti kuten kapea kerrostalo tai koko ruutupaperin yksi sivu. Tarvitsemme vastaavasti useampia osoitteita (indeksejä) osoittamaan millä rivillä ja missä sarakkeessa liikumme.
Alla on esimerkki 5x7 taulukosta (♠=pata, ♣=Risti, ♦=ruutu, ♥=hertta):
0 1 2 3 4 5 6
┌────┬────┬────┬────┬────┬────┬────┐
0 │ ♠ │ │ │ │ ♠ │ │ │
│ 7 │ │ │ │ A │ │ │
├────┼────┼────┼────┼────┼────┼────┤
1 │ │ ♣ │ │ ♥ │ │ │ │
│ │ K │ │ 5 │ │ │ │
├────┼────┼────┼────┼────┼────┼────┤
2 │ │ │ ♦ │ │ │ │ │
│ │ │ A │ │ │ │ │
├────┼────┼────┼────┼────┼────┼────┤
3 │ ♥ │ ♠ │ ♦ │ ♠ │ ♥ │ ♥ │ ♦ │
│ 7 │ 2 │ 2 │ 9 │ 6 │ 3 │ 7 │
├────┼────┼────┼────┼────┼────┼────┤
4 │ │ │ ♥ │ │ │ │ ♥ │
│ │ │ 2 │ │ │ │ J │
└────┴────┴────┴────┴────┴────┴────┘Jos taulukon nimi on peli, niin paikassa 3,1 on kortti pata 2:
peli[3][1] == ♠2Tehtävä 4.12 Kaksiulotteisen taulukon indeksit
Kirjoita kaikkien esimerkissä olevien korttien osoitteet em. muodossa.
Kaksiulotteista taulukkoa nimitetään usein matriisiksi.
Usein taulukoiden indeksit ilmoitetaan eri järjestyksessä kuin koordinaatiston (x,y)-koordinaatit. Tämä johtuu siitä ajattelutavasta, että taulukon rivi sinänsä voidaan kuvitella yhdeksi alkioksi (rivityypiksi) ja tällöin ilmaisu
peli[3]tarkoittaa koko riviä (♥7, ♠2, ♦2, ♠9, ♥6, ♥3, ♦7), jonka indeksi on kolme. Mikäli tämän perään laitetaan vielä [1], niin tarkoitetaan ko. tietorakenteen alkiota jonka indeksi on yksi (♠2).
Matematiikan (x,y)-koordinaattiin erona on myös se, että matematiikassa y kasvaa ylöspäin ja taulukon rivi-indeksit alaspäin.
Tarvittaessa moniulotteiset taulukot voidaan muodostaa yksiulotteisenkin taulukon avulla. Esimerkin taulukko voitaisiin muodostaa yksiulotteisesta taulukosta siten, että yksiulotteisen taulukon 7 ensimmäistä alkiota kuvaisivat matriisin 0:ta riviä, 7 seuraavaa matriisin ensimmäistä riviä jne.
Siis mikäli yksiulotteisen taulukon nimi olisi pakka, niin voisimme käyttää samaistuksia:
peli[3][1] = pakka[7*3+1]
peli[j][i] = pakka[7*j+i]Olemme siis numeroineet kaksiulotteisen taulukon alkiot juoksevasti. Voimmehan tehdä näin myös kerrostalon huoneistoille tai teatterin istumapaikoille.
Taulukot voivat olla myös useampiulotteisia, esimerkiksi 3x4x5 taulukko:
0 1 2 3 4
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐2
0 │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐1
└─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐└─┤ ┌┴─┐0
└─┤ │ └─┤PJ│ └─┤ │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐
1 │ ┌┴─┐ │ ┌┴─┐ │R5┴─┐ │ ┌┴─┐ │ ┌┴─┐
└─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤HA┴─┐ └─┤ ┌┴─┐
└─┤ │ └─┤ │ └─┤ │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐
2 │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐
└─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐
└─┤ │ └─┤ │ └─┤ │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐
3 │P7┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐
└─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐
└─┤ │ └─┤ │ └─┤ │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘isopeli[0][0][1]=PJ
isopeli[2][1][2]=R5
isopeli[1][1][3]=HA
isopeli[2][3][0]=P7Kun lisätään dimensioita, tulee uusi ulottuvuus "vasemmalle":
t1[3] (yksiulotteisen taulukon sarake 3)
t2[1][3] (kaksiulotteisen taulukon rivi 1 ja sarake 3)
t3[2][1][3] (kolmeulotteisen taulukon syvyys 2, rivi 1 ja sarake 3)Tämä mahdollistaa sen, että "leikkaamalla" yksi dimensio pois, saadaan alemman dimension "siivu":
t3[2] (kolmeulotteisen taulukon t3 syvyyssuunnassa 2 oleva 2-ulotteinen taulukko)
t3[2][1] (kolmeulotteisen taulukon t3 syvyyssuunnassa 2 olevan 2-ulotteisen
taulukon rivi 1 kokonaan)
Tehtävä 4.13 Sijoitus 3-ulotteiseen taulukkoon
Esitä 5 muuta sijoitusta taulukkoon.
Tehtävä 4.14 3-ulotteinen taulukko 1-ulotteiseksi
Esitä kaava miten edellä oleva 3-ulotteinen taulukko voitaisiin esittää yksiulotteisella taulukolla.
Aikaisempi satunnaisen matkaajan sanastomme on oikeastaan myös kolmiulotteinen taulukko:
0 1 2
0 minä jag i
1 sinä du you
2 hän han heSe on kaksiulotteinen taulukko sanoista. Mitä sitten yksi sana on? Se on yksiulotteinen taulukko kirjaimista!
0 1 2 3 4
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐2
0 │h┌┴─┐ │ä┌┴─┐ │n┌┴─┐ │ ┌┴─┐ │ ┌┴─┐1
└─┤s┌┴─┐ └─┤i┌┴─┐ └─┤n┌┴─┐ └─┤ä┌┴─┐└─┤ ┌┴─┐0
└─┤m │ └─┤i │ └─┤n │ └─┤ä │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐2
1 │h┌┴─┐ │a┌┴─┐ │n┌┴─┐ │ ┌┴─┐ │ ┌┴─┐1
└─┤d┌┴─┐ └─┤u┌┴─┐ └─┤ ┌┴─┐ └─┤ ┌┴─┐└─┤ ┌┴─┐0
└─┤j │ └─┤a │ └─┤g │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘
┌──┐ ┌──┐ ┌──┐ ┌──┐ ┌──┐2
2 │h┌┴─┐ │e┌┴─┐ │ ┌┴─┐ │ ┌┴─┐ │ ┌┴─┐1
└─┤y┌┴─┐ └─┤o┌┴─┐ └─┤u┌┴─┐ └─┤ ┌┴─┐└─┤ ┌┴─┐0
└─┤i │ └─┤ │ └─┤ │ └─┤ │ └─┤ │
└──┘ └──┘ └──┘ └──┘ └──┘Siis "you" sanan indeksi on [1][2] ja sen kirjaimen "y" indeksi on [0]. Siis kaiken kaikkiaan "you"-sanan "y"-kirjaimen indeksi olisi [1][2][0].
Taulukko voitaisiin järjestää 3-ulotteiseksi myös toisinkin. Esimerkiksi yhdessä "tasossa" olisi yksi kieli jne.
Tehtävä 4.15 Kolmiulotteinen taulukko
Esitä edellisessä esimerkissä kaikkien kirjainten indeksit.
Millaisella yhden kirjaimen sijoituksella muuttaisit sanan "han" sanaksi "hon"?
Tehtävä 4.16 Neliulotteinen taulukko
Mitenkä tavallinen kirja voitaisiin kuvitella 3-ulotteiseksi taulukoksi?
Miten kirja voitaisiin kuvitella 4-ulotteiseksi taulukoksi?
Piirrä edellisiin perustuen esimerkki 4-ulotteisesta taulukosta ja anna muutama esimerkkisijoitus.
Osoitinmuuttuja osoittaisi myös moniulotteisessa taulukossa yhteen alkioon kerrallaan. Esimerkiksi osoittamalla "you"-sanan "y"-kirjaimeen.
Moniulotteisen ja yksiulotteisen taulukon väliset muunnokset ovat tärkeitä, koska tietokoneen muisti (1997) on lähes aina yksiulotteinen. Siis loogisesti moniulotteiset taulukot joudutaan lopulta aina toteuttamaan yksiulotteisina. Onneksi useat kielet sisältävät moniulotteiset taulukot tietotyyppinä ja kääntäjät tekevät sitten muunnoksen. Tästä huolimatta esimerkiksi C-kielessä joudutaan usein muuttamaan moniulotteisia taulukoita yksiulotteisiksi.
4.4.6 Sekarakenteet
Taulukko voi olla myös taulukko osoittimista. Esimerkiksi sanastomme tapauksessa kaikki sanat voisivat olla yhdessä "möykyssä":
0 1 2 3
0123456789012345678901234567890123
minä jag i sinä du you hän han heItse sanasto voisi sitten olla taulukko osoittimia sanojen alkupaikkoihin:
| 0 | 1 | 2 | |
| 0 | 00 | 05 | 09 |
| 1 | 11 | 16 | 19 |
| 2 | 23 | 27 | 31 |
Siis taulukon paikasta sanasto[1][0] löytyy osoitin. Tämän osoittimen arvo on tässä esimerkissä 11. Siis osoitin viittaa sanan "sinä" alkuun. Tässä 2-ulotteinen taulukko osoittimista 1-ulotteiseen merkkitaulukkoon
// C++:lla
char *sanasto[3][3];
// Javalla
string[][];Tehtävä 4.17 Sanojen muuttaminen
Mitä ongelmia edellä olisi, mikäli yhdenkin sanan pituutta kasvatettaisiin?
Voitaisiinko edellä käyttää samoja sanoja uudestaan ja jos niin miten?
4.5 Osoittimista ja indekseistä
Osoitinmuuttujaa voitaisiin kuvitella myös seuraavasti: Olkoon meillä osoitekirja (osoitteet) jossa on sivuja:
sivu 0: sivu 1: sivu 2:
┌────────────────┐ ┌────────────────┐ ┌────────────────┐
│ Kassinen Katto │ │ Susi Sepe │ │ Ankka Aku │
│ │ │ │ │ │
│ Katto │ │ Takametsä │ │ Ankkalinna │
│ │ │ │ │ │
│ 3452 │ │ ─ │ │ 1234 │
└────────────────┘ └────────────────┘ └────────────────┘Meidän osoitekirjamme on tavallaan taulukko osoittimista (tässä tapauksessa osoitteita, älä sotke termejä!). Taulukon osoitteet paikassa 1 (sivu 1) on osoite "Sepe Sudelle". Mitä tapahtuu mikäli kirjoitamme kokonaan uuden henkilön osoitteen sivulla 1 olevan osoitteen päälle (sijoitetaan uusi arvo osoitinmuuttujalle sivu[1])?
sivu 0: C++:lla:
┌────────────────┐ sivu[1] = &Batman
│ Batman │ Javalla:
│ │ sivu[1] = Batman
│ Gotham City │
│ │
│ 9999 │
└────────────────┘Mitä tapahtuu "Sepe Sudelle"? Tuskinpa sijoitus osoitekirjassamme siirtää "Sepe Sutta" yhtään mihinkään "Perämetsästä", tai tekee edes häntä murheelliseksi! Tämä on eräs tyypillinen virhekäsitys osoitinmuuttujia käytettäessä. Osoitinmuuttujaan sijoittaminen ei muuta tietenkään itse tiedon sisältöä. Mutta sijoittaminen siihen paikkaan johon osoitinmuuttuja osoittaa (esimerkissämme "Sepe Suden" asuntoon) muuttaa tietenkin myös itse tiedon sisältöä.
// C++:lla
sivu[1] = uusi_osoite; // ei vaikuta Sepe Suteen
*sivu[1] = uusi_henkilo; // laittaa uuden henkilön Sepen osoitteeseen
// = "tähdätään osoitetta pitkin"
// Javalla
sivu[1] = uusi_osoite; // ei vaikuta Sepe Suteen
sivu[1].setNimi("Batman") // tämän lähemmäksi Javalla ei pääseVastaavasti jos meillä on indeksimuuttuja nimeltä snro, niin sijoitus muuttujalle
snro=2ei muuta mitenkään itse sivun sisältöä. Vasta sijoitus
sivu[snro]=muuttaisi sivun 2 sisältöä.
4.6 Aliohjelmat avuksi
Aliohjelma on tarkempi kuvaus tietylle asialle. Tämä kuvaus esitetään jossakin toisessa kohdassa ja sitä ei suinkaan tarvitse joka kerta lukea uudelleen.
Keittokirjassa lukee:
pyöritä lihapullataikinasta pyöreitä pullia
paista pullat kauniin ruskeiksiMiten pullat paistetaan kauniin ruskeiksi. Tämä olisi edellisen algoritmin aliohjelma. Kokenut kokki ei välitä aina (eikä edes suostuisi) joka reseptin kanssa lukea itse paistamisohjetta.
Aloittelija tätä saattaisi tarvita, jottei naapuri hälyttäisi palokuntaa paikalle liian savunmuodostuksen takia. Siis toivottavasti keittokirjasta jostakin kohti löytyisi myös itse paistamisohje.
Aliohjelmille on tyypillistä, että ne saattavat suoriutua vastaavista tehtävistä eri muuttujillekin. Näitä kutsukerroista riippuvia muuttujia sanotaan parametreiksi.
Esim. lihapullan paisto-ohje saattaa semmoisenaan kelvata myös tavalliselle pullalle:
paista("paistettava","c")
Korvaa seuraavassa sana "paistettava" sillä mitä olet
paistamassa ja "c" sillä lämpötilalla, joka keittokirjan
ohjeessa ko. paistettavan kohdalla on:
0. laita "paistettavat" pellille
1. lämmitä uuni "c"-asteeseen
2. laita pelti uuniin
...
9. mikäli "paistettavat" ovat mustia mene ostamaan
kaupasta valmiita
...Tehtävä 4.18 Lihapullan paistaminen
Täydennä edellinen paistamisalgoritmi. Onko parametreja tarpeeksi?
4.7 Vaihtoehtojen tutkiminen totuustaulun avulla
Usein helpostakin tehtävästä seuraa monia eri vaihtoehtoja, joiden täydellinen hallitseminen pelkästään päässä saattaa olla ylivoimaista. Tällöin avuksi tulee totuus- ja päätöstaulut. Päätöstaulu on totuustaulun pidemmälle viety versio.
Tutkikaamme aluksi muutamaa esimerkkiä jotka eivät suoranaisesti liity ohjelmointiin, mutta joissa esiintyy täsmälleen vastaava tilanne:
4.7.1 Kaikkien vaihtoehtojen kirjaaminen
Uusien opiskelijoiden lähtötasotesti 1991 (n. 20% oli osannut vastata oikein tähän tehtävään):
Tehtävä 3.4: Seisot tienhaarassa tuntemattomassa maassa. Toinen teistä vie pääkaupunkiin. Maan asukkaat joko valehtelevat aina tai puhuvat aina totta. Toisen tien alussa seisoskelee yksi heistä. Esität hänelle kyllä vai ei -kysymyksen ja saat vastauksen. Mitä kahta seuraavista neljästä kysymyksestä olisit voinut käyttää ollaksesi varma siitä, kumpi tie vie pääkaupunkiin - riippumatta siitä valehteleeko asukas vai ei?
- Viekö tämä tie pääkaupunkiin?
- Olisitko sanonut, että tämä tie vie pääkaupunkiin, jos olisin kysynyt sinulta sitä?
- Onko niin, että tämä joko on tie pääkaupunkiin, tai sitten sinä puhut totta (mutta ei molemmin tavoin)?
- Onko totta, että tämä tie vie pääkaupunkiin ja sen lisäksi sinä puhut totta?
Erotelkaamme eri kysymykset:
| nro | apukysymys | kysymys |
|---|---|---|
| 1 = | A | Viekö pääkaupunkiin? |
| B | Puhutko totta? (mielenkiinnon vuoksi) | |
| 2 = | C | Olisitko sanonut että vie jos A? |
| 3 <- | D | Tie pääk. XOR puhut totta? |
| 4 <- | E | Tie pääk. AND puhut totta? |
Nyt voimme kirjoittaa eri vaihtoehtojen mukaan seuraavan totuustaulun (v=vastaus kun valehteleminen otetaan huomioon):

Siis 2 ja 3 vastauksissa on järkevä korrelaatio siihen viekö tie pääkaupunkiin vai ei.
4.7.2 Vaihtoehtojen lukumäärä
Mistä tiedämme milloin kaikki vaihtoehdot on kirjoitettu? Mikäli systeemiin vaikuttavia asioita on n kappaletta ja kukin on kyllä/ei tyyppinen (0/1), niin vaihtoehdot on helpointa saada aikaan kirjoittamalla kaikki n-bittiset binääriluvut järjestyksessä (esimerkissämme n=2) ja suorittamalla sitten tarvittavat samaistukset (esim. E=0 ja K=1). Vaihtoehtoja on tällöin 2n.
00 -> E E
01 -> E K
10 -> K E
11 -> K KTehtävä 4.19 Kombinaatioiden lukumäärä
Olkoon meillä tehtävä, jossa yksi muuttuja voi saada arvot K,E,tyhjä ja toinen muuttuja arvot 5 ja 10. Kirjoita kaikki ko. muuttujien kombinaatiot.
Mikäli meillä on vaihtoehtoja n kappaletta ja kukin voi saada ki eri arvoa, niin montako eri kombinaatiota saamme aikaiseksi?
4.7.3 Useita vaihtoehtoja samalla muuttujalla
Ottakaamme toinen vastaava tehtävä:
Tehtävä 4.3: Pekka valehtelee maanantaisin, tiistaisin ja keskiviikkoisin; muina viikonpäivinä hän puhuu totta. Paavo valehtelee torstaisin, perjantaisin ja lauantaisin; muina viikonpäivinä hän puhuu totta. Eräänä päivänä Pekka sanoi: "Eilen valehtelin!" Paavo vastasi: "Niin minäkin!" Mikä viikonpäivä oli?
Minä päivinä kaverukset saattaisivat sanoa ko. lausuman? Näitä päiviä on tietysti ne, jolloin joko eilen valehdeltiin ja tänään puhutaan totta TAI eilen puhuttiin totta ja tänään valehdellaan. (XOR)
Seuraavaan taulukkoon on merkitty minä päivänä kukakin valehteli (V), milloin valehteli eilen (ve) ja milloin voisi sanoa että valehteli eilen (sanoo) kun otetaan valehtelu huomioon.
| päivä | Pekka | valehteli eilen |
sanoo | Paavo | valehteli eilen |
sanoo | |
|---|---|---|---|---|---|---|---|
| sunnuntai | ve | sanoo | |||||
| maanantai | V | sanoo | |||||
| tiistai | V | ve | |||||
| keskiviikko | V | ve | |||||
| torstai | ve | sanoo | V | sanoo | <== | ||
| perjantai | V | ve | |||||
| lauantai | V | ve | |||||
| sunnuntai | ve | sanoo |
Totuustaulun tavoitteena on siis kerätä kaikki mahdolliset vaihtoehdot ohjelmoijan silmien eteen, ja näin kaikki mahdollisuudet voidaan analysoida ja käsitellä.
Tehtävä 4.20 BAL=kyllä?
Eräällä saarella asuu luonnonkansa. Puolet kansan asukkaista aina valehtelevat ja toinen puoli puhuu aina totta. Lisäksi heidän kielensä on tuntematon. On saatu selville, että "BAL" ja "DA" tarkoittavat "kyllä" ja "ei", muttei sitä kumpiko tarkoittaa kumpaa. He ymmärtävät suomea mutta vastaavat aina omalla kielellään. Vastaasi tulee yksi saaren asukas.
- Mitä saat selville kysymyksellä "Tarkoittaako BAL KYLLÄ"?
- Millä kysymyksellä saat selville mikä sana on kyllä?
Tehtävä 4.21 Kuka valehtelee?
Jälleen maahan jossa asukkaat joko valehtelevat tai puhuvat aina totta. Tapaat kolme asukasta A:n, B:n ja C:n. He sanovat sinulla
A: Me kaikki kolme valehtelemme! B: Tasan yksi
meistä puhuu totta!Mitä ovat A, B ja C?
Entä jos asukkaat sanovat:
A: Me kaikki kolme valehtelemme! B: Tasan yksi
meistä valehtelee!Entä jos:
A: Minä valehtelen mutta B ei!Entä jos:
A: B valehtelee!
B: A ja C ovat samaa tyyppiä!Vielä yksi:
A sanoo: B ja C ovat samaa tyyppiä.
C:ltä kysytään: Ovatko A ja B samaa tyyppiä?Mitä C vastaa?
4.7.4 Loogiset operaatiot
Ehtoja usein yhdistellään loogisten operaatioiden avulla:
Mikäli kello 7-20 ja et halua ulkoilla
- mene bussilla
...
Mikäli sinulla on rahaa tai saat kimpan
- ota taksiYksittäinen ehto antaa tulokseksi tosi (T=true) tai epätosi (F=false). Ehtojen tulosta voidaan usein myös kuvata 1 tai 0. Ehtojen yhdistämistä loogisilla operaatioilla kuvaa seuraava totuustaulu (myös C++:n loogiset operaattorit merkitty):
┌──────┬──────┬────────┬────────┬────────┬───────┐
│ │ │ ja │ tai │ehd.tai │ ei │
│ │ │ │ │ │ │
│ │ │ AND │ OR │ XOR │ NOT │
│ p │ q │ p && q │ p || q │ p ^ q │ !p │
├──────┼──────┼────────┼────────┼────────┼───────┤
│ F 0 │ F 0 │ F 0 │ F 0 │ F 0 │ T 1 │
│ F 0 │ T 1 │ F 0 │ T 1 │ T 1 │ T 1 │
│ T 1 │ F 0 │ F 0 │ T 1 │ T 1 │ F 0 │
│ T 1 │ T 1 │ T 1 │ T 1 │ F 0 │ F 0 │
└──────┴──────┴────────┴────────┴────────┴───────┘
Huomattakoon edellä, että AND operaatio toimii kuten kertolasku ja OR operaatio kuten yhteenlasku (mikäli määritellään 1+1=1). Siis loogisia operaattoreita voidaan käyttää kuten normaaleja algebrallisia operaattoreita ja niillä operoiminen vastaa tavallista algebraa. Loogisten operaatioiden algebraa nimitetään Boolen -algebraksi.
Ehtojen sieventämisessä käytettäviä kaavoja voidaan todistaa oikeaksi totuustaulujen avulla. Todistetaan esimerkiksi de Morganin kaava (vrt. joukko-oppi, 1=true, 0=false):
NOT (p AND q) = (NOT p) OR (NOT q)Jaetaan ensin väittämä pienempiin osiin:
NOT e1 = e2 OR e3
┌───┬────╥────────┬───────┬───────┬────────┬────────┐
│ │ ║ e1 │ e2 │ e3 │ │ │
│ p │ q ║ p AND q│ NOT p │ NOT q │ NOT e1 │e2 OR e3│
├───┼────╫────────┼───────┼───────┼────────┼────────┤
│ 0 │ 0 ║ 0 │ 1 │ 1 │ 1 │ 1 │
│ 0 │ 1 ║ 0 │ 1 │ 0 │ 1 │ 1 │
│ 1 │ 0 ║ 0 │ 0 │ 1 │ 1 │ 1 │
│ 1 │ 1 ║ 1 │ 0 │ 0 │ 0 │ 0 │
└───┴────╨────────┴───────┴───────┴────────┴────────┘Koska kaksi viimeistä saraketta ovat samat ja kaikki muuttujien p ja q arvot on käsitelty, on laki todistettu!
Tehtävä 4.22 de Morganin kaava
Todista oikeaksi myös toinen de Morganin kaava:
NOT (p OR q) = (NOT p) AND (NOT q)Tehtävä 4.23 Osittelulaki
Yhteenlaskun ja kertolaskun välillähän pätee osittelulaki:
p * (q + r) = (p * q) + (p * r)Samaistamalla * <=> AND ja + <=> OR todetaan loogisille operaatioillekin osittelulaki:
p AND (q OR r) = (p AND q) OR (p AND r)Todista oikeaksi toinen osittelulaki (toimiiko vast. yhteenlaskulla ja kertolaskulla):
p OR (q AND r) = (p OR q) AND (p OR r)Huomaa, että totuustauluun tulee nyt 8 riviä (koska kolme muuttujaa)!
Tehtävä 4.24 Ehtojen sieventäminen
Käytä de Morganin kaavoja tai osittelulakia seuraavien ehtojen sieventämiseen:
- ei ole totta että hinta alle 5 mk ja paino yli 10 kg
- NOT (kello<=7 OR rahaa>50 mk)
- (hinta < 5) tai (rahaa>10)) ja ((hinta < 5) tai (kello>9))
4.8 Muistele tätä
Mikäli edellä esitetyt asiat tuntuvat ymmärrettäviltä, niin ohjelmoinnissa ei tule olemaan mitään vaikeuksia. Jos vastaavat asiat tuntuvat vaikeilta ohjelmoinnin kohdalla, kannattaa palata takaisin tähän lukuun ja yrittää samaistaa asioita ohjelmointikieleen.
Taulukoiden samaistaminen ruutupaperiin, korttipakkaan tai muuhun tuttuun asiaan auttaa asian käsittelyä. Osoitinmuuttuja on yksinkertaisesti jokin (vaikkapa sormi) joka osoittaa johonkin (vaikkapa yhteen kirjaimeen).
Silmukat ja ehtolauseet ovat hyvin luonnollisia asioita.
Aliohjelmat ovat vain tietyn asian tarkempi kuvaus. Tarvittaessa tiettyä asiaa ei ongelmaa tarvitse heti ratkaista, vaan voidaan määritellä aliohjelma, joka hoitaa homman ja kirjoitetaan itse aliohjelman määrittely joskus myöhemmin.
Tehtävä 4.25 Merkkijonot
C-kielessä merkkijonot tullaan esittämään taulukoina kirjaimista. Merkkijonon loppu ilmaistaan kirjaimella NUL. Siis esimerkiksi Kissa olisi seuraavan näköinen
0 1 2 3 4 5
┌───┬───┬───┬───┬───┬───┬───┐
│ K │ i │ s │ s │ a │NUL│ │
└───┴───┴───┴───┴───┴───┴───┘Kirjoita seuraavat algoritmit. Erityisesti kirjoita ensin algoritmin sanallinen versio
- Välilyöntien poistaminen jonon alusta.
- Välilyöntien poistaminen jonon lopusta.
- Ylimääräisten (2 tai useampia) välilyöntien poistaminen jonosta.
- Kaikkien ylimääräisten (alku-, loppu- ja monikertaiset) välilyöntien poistaminen.
- Jonon muuttaminen siten, että kunkin sanan 1. kirjain on iso kirjain.
- Tietyn merkin esiintymien laskeminen jonosta.
- Esiintyykö merkkijono toisessa merkkijonossa (kissatarha, sata -> esiintyy; kissatarha, satu -> ei esiinny).
Tehtävä 4.26 Päivämäärät
Kirjoita seuraavat algoritmit:
- Onko vuosi karkausvuosi vai ei. (Huom! 1900 ei, 2000 on)
- Montako karkausvuotta on kahden vuosiluvun välillä.
- Jos 1.1 vuonna 1 oli maanantai, niin mikä viikonpäivä on 1.1 vuonna x? (Oletetaan että kalenteri olisi ollut aina samanlainen kuin nytkin. Vihje! Tutki almanakkaa peräkkäisiltä vuosilta.)
- Onko päivämäärä pp.kk.vvvv oikeata muotoa?
5. Esimerkkejä eri kielistä
Ompi Jaavaa ompi Ceetä,
Adaa ompi Pascalia.
Kieltä vanhaa, kieltä uutta
ne kaukaa sekä läheltä.
Monta kieltä monta mieltä,
kummajaisilla ku noilla,
voi koodia väänneskellä,
kaikellailla keikistellä.
Mitä tässä luvussa käsitellään?
- katsotaan mitä syntaktista eroa on eri ohjelmointikielillä yksinkertaisessa esimerkissä
Jossakin vaiheessa ohjelmoinnin opiskelua tullaan siihen, että ohjelma pitäisi toteuttaa jollakin olemassa olevalla ohjelmointikielellä (on tosin ohjelmointikursseja, joilla käytetään keksittyä ohjelmointikieltä).
Luvun ohjelmaesimerkeissä esitämme ohjelmia, joiden ainoa tehtävä on tulostaa teksti:
Terve! Olen ??-kielellä kirjoitettu ohjelma.Tällainen pikkuesimerkki ei millään tavalla tuo esille eri kielten hyviä ja huonoja ominaisuuksia.
Itse ohjelman suunnittelu on tällä kertaa varsin triviaali ja tehtävä ei tarvitse varsinaista tarkennustakaan, kaikki on sanottu tehtävän määrityksessä. Siis valitaan vain käytetyn kielen tulostuslause.
5.1 Käännettävä vai tulkittava
Yhden jakoperustan ohjelmointikielille voisi antaa sillä perusteella, että ovatko ne tulkittavia vaiko käännettäviä. Tosin käytännössä tuohon välimaastoon tulee vielä useita vaihtoehtoja.
Tulkitseminen tarkoittaa sitä, että ohjelmaa ajetaan suoraan sen lähdekoodista tulkitsemalla sen sisältöä ajon aikana. Tällaisten kielten käyttäminen on sikäli helppoa, että riittää kirjoittaa ohjelma ja ruveta ajamaan sitä saman tien. Basic tai Python alkuperäisessä muodossaan on yksi hyvä esimerkki tulkittavasta kielestä. Tulkittava kieli tarvitse aina ohjelman joka kieltä lähtee tulkitsemaan. Pythonin tapauksessa se on Python-niminen ohjelma. Jokaiselle eri prosessorityypille pitää olla oma tulkkiohjelma.
Kääntäminen tarkoittaa sitä, että ohjelmakoodin kirjoittamisen jälkeen se annetaan kääntäjäohjelmalle, joka tuottaa siitä konekielisen version. Usein tämän jälkeen vielä käytetään linkittäjäohjelmaa, joka linkittää konekieliseen koodiin mukaan ohjelman tarvitsemat kirjastofunktiot. Näiden jälkeen on syntynyt valmis ajettava exe-tiedosto (executable), joka on täysin konekieltä. Käännettävien kielten etuna pidetään yleensä niiden ajonaikaista nopeutta verrattuna tulkittaviin kieliin. Tämä johtuu siitä, että ohjelmaa suoritettaessa ei enää tarvitse tehdä muuta kuin suorittaa lauseita suoraa prosessorilla. Tyypillisiä käännettäviä kieliä ovat mm. Fortran, Pascal, C ja C++. Jokaiselle eri prosessorityypille pitää olla oma kääntäjäohjelma.
Tulkittavien ja käännettävien kielten välimaastoon sijoittuu vielä kielet, joita kirjoitetaan tekstinä, mutta jotka käännetään välikielelle, virtuaalikoneelle, joka sitten suorittaa näitä välikielen käskyjä. Etuna edellisiin verrattuna on se, että kääntäjä voi olla sama kaikille prosessorityypeille ja ”vain” virtuaalikone pitää kirjoittaa prosessorikohtaisesti. Toki käytännössä esimerkiksi C-kääntäjän koodista suuri osa on samaa eri prosessoreille ja vain ”loppupää”, joka tuottaa itse konekieltä, on eri koodia. Tällaisissa välikieli-kielissä tarvitaan siis erikseen kääntäjä ja ”virtuaalikone”, eli tulkki, joka tulkitsee välikieltä. Välikieli on kuitenkin niin yksinkertaista ja yksikäsitteistä, että sen tulkitseminen on merkittävästi nopeampaa kuin alkuperäisen tekstuaalisen muodon tulkitseminen. Lisäksi välikoodi ei enää voi sisältää syntaksivirheitä, koska ne on havaittu jo käännösvaiheessa. Tyypillisiä tämän kieliperheen jäseniä ovat C# ja Java. Esimerkiksi käännetyn Java-ohjelma ajamiseen tarvitaan Java-virtuaalikone (JVM, Java Virtual Machine) joka yleensä käynnistetään komennolla java. Tämän välikielen käyttämisen takia usein näitä kieliä pidetään nopeudeltaan tulkittavien ja käännettävien välimaastoon sijaitsevina. Esimerkiksi Javan yksi alkuperäisistä tarkoituksista oli, että voitaisiin tehdä suoraa tätä välikieltä suorittavia prosessoreita ja näin saavuttaa täydellisesti käännettävien kielten suoritusnopeus. Käytännössä näitä prosessoreita ei juurikaan ole ilmestynyt.
Monia välikielelle käännettäviä ohjelmia voidaan kääntää myös suoraan konekielelle. Lisäksi on käsite JIT (Just In Time compiling), jossa välikieltä suoritettaessa sitä käännetään samanaikaisesti konekielelle ja kun samaan ohjelman osaan tullaan uudelleen, on siitä jo valmis konekielinen käännös ja suoritus on nopeaa. Lisäksi osin rajoitetusti voidaan Python koodiakin kääntää suoraan konekielelle. Lisäksi Java-versiosta 11 alkaen pienet Java-ohjelmat voidaan ajaa suoraan java-komennolla ilman erillistä kääntämistä, vaan kääntäminen tehdään Java-virtuaalikoneen sisällä. Eli rajat ovat todella häilyviä.
Suoraan ohjelman suoritusnopeutta ei siis voi julistaa sen perusteella, mitä kieltä on käytetty. Usein sisäisesti käytetyt kirjastot voivat noista merkittävämpään asemaan nopeuden suhteen. Ja huonosti tehty algoritmi toimii huonosti kielestä riippumatta. Jos käytetään sisäkkäisiä silmukoita tilanteessa, jossa lineaarinen läpikäynti riittäisi, on tulos hidas oli kyse mistä kielestä tahansa. Mutta esimerkiksi hidaskin kieli O(n) algoritmilla on paljon nopeampi kuin nopea kieli O(n2) -algortimilla.
5.2 Esimerkkiohjelmat
Jotta lukija ymmärtäisi, ettei eri kielten välillä ole kuin pieni ero, esitämme ohjelman useilla eri kielillä. Ohjelman lopun jälkeen olevan poikkiviivan alapuolella on mahdollisesti esitetty miten ohjelmaa voitaisiin kokeilla:
5.2.1 C
Ajaminen:
- käynnistä vaikkapa Linuxin komentorivi
nano olen.c
- kirjoita ohjelma
- paina [Ctrl-X]
- käännä kirjoittamalla: gcc olen.c
- aja ohjelma kirjoittamalla:
./a.out5.2.2 C++
Ajaminen:
- käynnistä vaikkapa Linuxin komentorivi
nano olen.cpp
- kirjoita ohjelma
- paina [Ctrl-X]
- käännä kirjoittamalla: g++ olen.cpp
- aja ohjelma kirjoittamalla:
./a.out- huomattakoon, että myös
olen.ckelpaisi sellaisenaan C++ ohjelmaksi
5.2.3 Java
Ajaminen:
- Kirjoita esimerkki/Olen.java jollakin editorilla
- siis nykyhakemiston alihakemistoon koska package esimerkki
- käännä: javac esimerkki/Olen.java
- aja: java esimerkki.Olen5.2.4 C#
Ajaminen:
- Kirjoita HelloWorld.cs jollakin editorilla
- käännä: csc HelloWorld.cs
- aja: HelloWord5.2.5 Pascal
- käynnistä vaikkapa Turbo Pascal
TP OLEN.PAS
- kirjoita ohjelma
- paina [Ctrl-F9]5.2.6 Fortran 77
5.2.7 Fortran 95
5.2.8 ADA
-- ADA-kieli
with TEXT_IO; use TEXT_IO;
procedure ADA_MALLI is
pragma MAIN;
begin
PUT("Terve! Olen ADA-kielellä kirjoitettu ohjelma."); NEW_LINE;
end ADA_MALLI;5.2.9 BASIC
REM BASIC-kieli
PRINT "Terve! Olen BASIC-kielellä kirjoitettu ohjelma."
END
-------------------------------------------------------------------
- käynnistä vaikkapa Quick Basic
QBASIC OLEN.BAS
- kirjoita ohjelma
- paina [Alt-R][Return]5.2.10 APL
⍝ APL-kieli
⎕ ←'Terve! Olen APL-kielellä kirjoitettu ohjelma.'
Katso APL syntax and symbols.
5.2.11 Modula-2
(* Modula-2 -kieli *)
MODULE olen;
FROM InOut IMPORT WriteString, WriteLn;
BEGIN
WriteString("Terve! Olen Modula-2 -kielellä kirjoitettu ohjelma.");
WriteLn;
END olen.5.2.12 Common Lisp
Ajaminen:
- Käynnistä jokin Common Lisp -toteus, kuten SBCL
- kirjoita koodi kehoitteeseen, rivinvaihto ajaa sen
- editorilla voi tehdä myös tiedoston, joka sisältää halutun ohjelman
- Common Lisp -toteutukselle annetaan ko. tiedosto argumenttina:
esim. sbcl ohjelmani.lisp5.2.13 FORTH
( FORTH-kieli )
: OLEN ( -- )
." Terve! Olen FORTH-kielellä kirjoitettu ohjelma." CR
;
OLEN5.2.14 Python 3
5.2.15 JavaScript
5.2.16 Scala
5.2.17 Swift
5.2.18 Rust
5.2.19 Go
5.2.20 Assembler
; 8086 assembler
DOSSEG
.MODEL TINY
.STACK
.DATA
viesti DB 'Terve! Olen 8086-assemblerilla kirjoitettu ohjelma.',0DH,0AH,'$'
.code
olen PROC NEAR
MOV AX,@@DATA
MOV DS,AX ; Viestin segmentti DS:ään
MOV DX,OFFSET viesti ; Viestin offset osoite DX:ään
MOV AH,09H ; Funktiokutsu 9 = tulosta merkkijono DS:DX
INT 21H ; Käyttöjärjestelmän kutsu
MOV AX,4C00H ; Funktiokutsu 4C = ohjelman lopetus
INT 21H ; Käyttöjärjestelmän kutsu
olen ENDP
END olen
-------------------------------------------------------------------
- kirjoita ohjelma jollakin ASCII-editorilla nimelle OLEN.ASM
- anna käyttöjärjestelmässä komennot (oletetaan että TASM on polussa):
TASM OLEN
TLINK OLEN
OLENSiis erot eri kielten välillä ovat hyvin kosmeettisia (Pascalin BEGIN on C:ssä { jne.). Jollakin kielellä asia pystyttiin esittämään hyvin lyhyesti ja jossakin tarvitaan enemmän määrittelyjä. Ainoastaan assembler-versio on sellaisenaan epäselvä, suoritettavia lauseita on täytynyt kommentoida enemmän.
Lisää esimerkkejä voit kokeilla vaikkapa ideone.com-palvelussa.
5.3 Käytettävän kielen valinta
Kullakin ohjelmointikielellä on omat etunsa. Pascal on hyvin tyypitetty kieli ja sillä ei ole aloittelijankaan niin helppo tehdä eräitä tyypillisiä ohjelmointivirheitä kuin muilla kielillä. Standardi Pascal on kuitenkin hyvin suppea ja siitä puuttuu esim. merkkijonojen käsittely.
Turbo Pascalin laajennukset tekevät kielestä erinomaisen ja nopean kääntäjän ja UNIT-kirjastojen ansiosta se on todella miellyttävä käyttää. Nykyisin lisäksi Delphi-sovelluskehittimen kielenä on juuri Turbo Pascalista laajennettu Object Pascal. Delphi on eräs merkittävimmistä ja helppokäyttöisimmistä työkaluista Windows-ohjelmointiin.
BASIC-kieli on yleensä suppea kieli ja siksi helppo oppia. Lukuisten eri murteiden takia ohjelmien siirtäminen ympäristöstä toiseen on lähes mahdotonta. Microsoftin Visual Basic on kuitenkin Windows-ympäristössä nostanut Basicin jopa ohjelmankehittäjien työkaluksi. Alkuperäiset Basic-murteet olivat huonoja opiskelukieliä rajoittuneiden rakenteiden ja automaattisen muuttujanluomisen vuoksi. Visual Basicin uusimmissa versioissa on jo mukana yleisimmin tarvittavat rakenteet.
Fortran on luonnontieteellisissä sovelluksissa eniten käytetty kieli ja siihen on saatavissa laajat aliohjelmakirjastot useisiin numeriikan ongelmiin. Mikroissa kääntäjät ovat kuitenkin hitaita. Fortran-77 standardi on eräs parhaista standardeista, jota seuraamalla ohjelma toimii lähes koneessa kuin koneessa. Fortranin uusin standardi -90 tarjoaa ennen kielestä puuttuneet rakenteet.
ADA on Pascalin kaltainen vielä tarkemmin tyypitetty kieli, jossa on joitakin olio-ominaisuuksia. Se on Yhdysvaltain puolustusministeriön tukema kieli, joten se lienee tulevaisuuden kieliä. Sopii erityisesti raskaiden reaaliaikatoteutusten kirjoittamiseen (esim. ohjusjärjestelmät). GNU ADA tuo kääntäjän käyttämisen mahdolliseksi jokaiselle. Lisäksi ADA-95 tuo kieleen olio-ominaisuudet.
C-kieli on välimuoto Pascalista ja konekielestä. Ohjelmoijalle sallitaan hyvin suuria vapauksia, mutta toisaalta käytössä on hyvät tietotyypit ja rakenteet. Hyvä kieli osaavan ohjelmoijan käsissä, mutta aloittelija saattaa saada aikaan katastrofin. ANSI-C on suhteellisen hyvin standardoitu ja sitä seuraamalla on mahdollista saada ohjelma toimimaan pienin muutoksin myös toisessakin laiteympäristössä. Lisäksi ANSI-C:n tuoma funktioiden prototyypitys ja muutkin tyyppitarkistukset poistavat suuren osan ohjelmointivirheiden mahdollisuuksista, eivät kuitenkaan kaikkia. UNIX -käyttöjärjestelmän leviämisen myötä C on kohonnut erääksi kaikkein käytetyimmistä kielistä.
C++ on C-kielen päälle kehitetty oliopohjainen ohjelmointikieli. Aikaisemmin C-kielellä oli niin suuri merkitys, että se kannatti ehkä opetella aluksi. Nykyisin jokainen merkittävä C-kääntäjä on myös C++-kääntäjä. Oliopohjaisen ohjelmoinnin kannalta on parempi mitä aikaisemmin olio-ohjelmointi opetellaan. Valitettavasti C++ ei ole hybridikielenä (multi paradigm) paras mahdollinen ohjelmoinnin opetteluun. Kuitenkin paremmin opetteluun soveltuvat kielet ovat usein "leikkikieliä", kuten alkuperäinen Pascalkin oli. Delphi olisi mahtavan graafisen kirjastonsa ja kehitysympäristönsä ansiosta loistava opettelutyökalu, valitettavasti vaan lehti-ilmoituksissa harvoin haetaan Delphi-osaajia! Kohtuullisena kompromissina C++:kin voidaan valita opettelukieleksi, kunhan ei heti yritetä opetella kaikkia kielen kommervenkkeja.
Java on verkkoympäristössä tapahtuvaan ohjelmointiin kehitetty oliokieli. Javan erikoisuus on se, että se käännetään siirrettävään Java-tavukoodimuotoon. Tätä tavukoodia voidaan sitten suorittaa lähes missä tahansa ympäristössä Java-virtuaalikoneen avulla. Javaa on sanottu C++:aa yksinkertaisemmaksi, mutta kuitenkin Java kirjat ovat yhtä paksuja kuin C++ kirjatkin. Nykyisin onkin monesti niin, ettei itse kieli ole ongelma, vaan sille kehitettyjen aliohjelmakirjastojen opettelu ja käyttö. Javan suurimpana etuna on sen lähes kaikissa koneissa toimiva graafinen kirjasto. Java-työkalut kehittyvät kovaa vauhtia, valitettavasti käyttöliittymän graafiseen suunniteluun tarkoitetut työkalut eivät ole keskenään yhteensopivia.
C# on Microsoftin vuonna 2000 julkaisema olio-ohjelmointikieli. Syntaksiltaan se on muistuttaa paljon C:tä, mutta sen kehityksessä on otettu paljon inspiraatiota myös Javasta, Delphistä ja Visual Basicista. Javan ja C#:n samankaltaisuus on ollut jonkinlainen kiistelyn aihe jopa kielten kehittäjien kesken. Kielten viimeisimmät päivitykset ovat kuitenkin tuoneet kehittyneimpiin ominaisuuksiin huomattavia eroja. Hyvänä esimerkkinä C#:n 3.0:ssa esitelty Language Integrated Query (LINQ) laajennus toi kieleen monia funktionaalisen ohjelmoinnin ominaisuuksia. Javan tavoin myös C# ohjelmat ajetaan virtuaalikoneen päällä. Käytettävä virtuaalikone perustuu Microsoftin Common Language Infrastructure spesifikaatioon. Suosituin CLI toteutus on Microsoftin oma virtuaalikone, mutta myös muutama vapaan lähdekoodin vaihtoehto kuten Mono on saatavilla.
Tämän kurssin eri versioissa on käytetty esimerkkikielenä Pascalia, C:tä, C++:aa ja nyt tässä versiossa Javaa. Kielen valinta ei suuria merkitse, ohjelmointi on kuitenkin perusteiltaan samanlaista. Joitakin vivahde-eroja kuitenkin tulee valitun kielen mukana.
6. Java -kielen alkeita
Kommenttit jo käyttämäksi
muistiksipa merkit muille
selvennykseksi sepille
omaksikin ovat iloksi.
Vakioksi alkuun tiedot
kevenee koodin korjaaminen
mukavampi muutos aina
sulavampi säätäminen.
Koodi ensin käännettävä
syntaksikin syynättävä
tuo tulkilla tulkattava
siitä sitten suorittava.
Mitä tässä luvussa käsitellään?
- Java-kielisen ohjelman peruskäsitteet
- kääntämisen ja linkittämisen merkitys
- paketin käyttöönotto
- vakioarvot
Syntaksi:
kommentti: /* vapaata tekstiä, vaikka monta riviäkin */
kommentti: // loppurivi vapaata tekstiä
luokan ottaminen: import paketin_nimi.Luokka; import paketin_nimi.;
vakio: static final tyyppi nimi =arvo;
tulostus: System.out.println(merkijono);
merkkijono: "merkkejä"Luvun esimerkkikoodit:
Ohjelman toteuttamista varten täytyy valita jokin todellinen ohjelmointikieli. Lopullisesta ohjelmasta ei valintaa toivottavasti huomaa. Valitsemme käyttökielen tällä kurssilla puhtaasti "markkinaperustein": paljon käytetyn ja työelämässä kysytyn - Java.
6.1 C#:sta Javaan
Mikäli olet käynyt jo Ohjelmointi 1 kurssin C#:lla, niin ei turhaan kannata säikähtää kielen vaihtumista. Java ja C# ovat ominaisuuksiltaan hyvin samankaltaisia kieliä. Molemmat ovat staattisesti tyypitettyjä olio-ohjelmointikieliä, molempien suoritus tapahtuu virtuaalikoneessa ja lisäksi ne ovat hyvin samankaltaisia jopa syntaksiltaan.
Erot käsitellään tässä monisteessa sitä mukaan kun niitä tulee vastaan. Merkittävimmät niistä koskevat kuitenkin vasta kielten uudempia ja kehittyneempiä ominaisuuksia, eikä niitä ole edes Ohjelmointi 1 kurssin puitteissa tullut vastaan. Internetissä on monia eroista kielten eroa käsitteleviä artikkeleita, mutta yksi hyvä paikka on Ville Salosen kandinaatintutkielma:
Ville on myös pohtinut esseessään hieman edistyneempää asiaa ja syitä eroavaisuuksiin. Näkökulma on enemmänkin "konepellin alta", joten seuraava linkki voi olla hyvää luettavaa tämän kurssin jälkeen.
Tarpeen vaatiessa monisteen muutamaan ensimmäiseen lukuun Java-kielisten esimerkkien rinnalle on kirjoitettu myös C# versiot. Kurssin kannalta C#:n osaaminen ei kuitenkaan ole olennaista.
6.2 Hello World! Java ja C#-kielillä
Vaikka seuraavassa ensimmäisessä yksinkertaisessa Java-esimerkissä ei ole package-riviä, kannattaa käytännössä jokainen Java-luokka kirjoittaa johonkin packageen.
- C#-versio
Ohjelmat ovat selvästikin hyvin samankaltaiset. Ensimmäiseksi kannattaa kiinnittää huomio syntaksiin. Javan (yleisesti käytetty) tapa aloittaa lohko { -merkillä ilman rivinvaihtoa eroaa hieman C#:n vastaavasta. Molemmat ohjelmat kääntyisivät kummallakin tavalla, mutta koodin luettavuus helpottuu, kun käyttää virallista tyyliä. Lisäksi kehitysympäristöjen tarjoamien koodin formatointityökalujen käyttö on helpompaa jos oletusasetuksia ei tarvitse erikseen muuttaa. Vähän tärkeämpi koodin muotoiluun liittyvä asia on, että funktiot on tapana kirjoittaa Javassa pienellä, kun C#:n käytäntö on nimetä ne isolla. Jälleen kuitenkin kumpikin tyyli menee molempien kääntäjistä läpi.
On myös helppo huomata että käytettyjen kirjastojen ja funktioiden nimet ovat muutenkin erilaiset. Silti usein tulee vastaan tilanteita, joissa käytettyjen kirjastojen nimet ovat, jolleivät peräti samoja, niin ainakin hyvin samankaltaisia. Tähän liittyy kuitenkin se ansa, että samallakin tavalla nimettyjen funktioiden toiminta saattaa erota ratkaisevasti toisistaan! Esimerkiksi C#:issa usein viedään parametrina alku ja osavälin pituus, kun Javassa viedään parametrina alku ja loppu-indeksi, joka ei enää tule mukaan. Jos aloitetaan esimerkiksi jonon alusta, niin silloin samat parametrin arvot toimivat molemmilla, mutta muussa tapauksessa ei:
// 012345
String jono = "abcde";Javassa jälkimmäinen lause tuottaa bc, mutta C#:ssa bcd. Syy selviää metodien dokumentaatiota tutkimalla. Java-kutsu palauttaa merkkijonon, joka alkaa paikasta (kirjaimesta) yksi ja loppuu ennen kolmatta paikkaa (exclude) , kun taas C#-funktio palauttaa paikasta yksi alkaen kolme merkkiä.

Kannattaa siis aluksi varmistaa dokumentaatiosta mitä onkaan tekemässä. Ohjelmointikielien samankaltaisuuksista huolimatta jokaisella kielellä on omat tapansa toteuttaa asioita. Se minkä vuoksi Javan substring metodin viimeinen parametri 3 ei sisällytäkään vastaavaa merkkiään palautettavaan merkkijonoon, johtuu Javan käytännöstä jättää merkki pois (exclude), joka on tyypillistä toiminnallisuutta useille Java-funktioille. Valittu tapa säästää käytännössä usein turhia -1 laskuja.
Tehtävä 6.1 Nimi ja osoite
Kirjoita Java-ohjelma joka tulostaa:
Terve!
Olen Matti Meikäläinen 25 vuotta.
Asun Kortepohjassa.
Puhelinnumeroni on 603333.6.3 Tekstitiedostosta toimivaksi konekieliseksi versioksi
6.3.1 Kirjoittaminen
Ohjelmakoodi kirjoitetaan millä tahansa tekstieditorilla tekstitiedostoon vaikkapa nimelle Hello.java. Yleensä tiedoston tarkentimella annetaan sille tyyppi, jonka avulla käyttöjärjestelmä ja ohjelmat saavat lisätietoa minkälainen tiedosto on kyseessä.
Seuraavassa esimerkissä kirjoitetaan Java-ohjelma packageen example ja tallennetaan nimelle example/Hello.java
6.3.2 Kääntäminen
Valmis tekstitiedosto käännetään ko. kielen kääntäjällä. Käännöksestä muodostuu usein objektitiedosto, joka on jo lähellä lopullisen ohjelman konekielistä versiota. Objektitiedostosta puuttuu kuitenkin mm. kirjastorutiinit (eli aliohjelmat/funktiot yms). Kirjastorutiinien kutsujen kohdalla on "tyhjät" kutsut.
Java-kielen tapauksessa käännöksen tuloksena syntyy Java-virtuaalikoneen (JVM) ymmärtämää tavukoodia. Luvun alussa olevan esimerkin tiedosto kääntyy esimerkiksi komennolla:
javac Hello.javaKäännöksen tuloksena syntyvässä Hello.class-tiedossa on siis Java-tulkin ymmärtämää tavukoodia. Kuitenkin siitäkin puuttuu itse kirjastorutiinit. Erona muihin kieliin on se, että käännetty tiedosto toimii niissä ympäristöissä, joissa on JVM ja nuo puuttuvat rutiinit.
Varsinaisissa käännettävissä kielissä käännös pitää suorittaa uudelleen jos ohjelma halutaan siirtää toiseen ympäristöön.
Jos edellisessä kohdassa ollut example/Hello.java halutaan kääntää, niin komennossa pitää muistaa antaa hakemiston nimi:
Mikäli kääntäminen onnistuu, ei tule minkäänlaista ilmoitusta. Mikäli ei onnistu (kokeile vaikka vaihtaa tiedoston nimeä), niin silloin tulee virheilmoitus.
Voit katsoa example-hakemiston sisällön ls -la -komennolla (Windowsissa dir -komennolla). Hakemistoon pitäisi olla tullut Hello.classniminen tiedosto.
6.3.3 Linkittäminen
Linkittäjällä (kielestä riippumaton ohjelma) liitetään kirjastorutiinit käännettyyn objektitiedostoon. Linkittäjä korvaa tyhjät kutsut varsinaisilla kirjastorutiinien osoitteilla, kunhan se saa selville mihin kohti muistia kirjastorutiinit sijoittuvat. Näin saadaan valmis ajokelpoinen konekielinen versio alkuperäisestä ohjelmasta.
Javan tapauksessa varsinaista linkittämistä ei tarvita, vaan ohjelman suorituksen aikana etsitään tarpeellisia luokkia. Luokkien etsiminen voi tapahtua heti kun ensimmäistä luokkaa ladataan muistiin ("static" resolution) tai vasta kun luokkaan viitataan ("laziest" resolution).
6.3.4 Ohjelman ajaminen
Käännetty ohjelma ajetaan käyttöjärjestelmästä riippuen yleensä kirjoittamalla ohjelman alkuperäinen nimi. Tällöin käyttöjärjestelmän lataaja-ohjelma lataa ohjelman konekielisen version muistiin ja siirtää prosessorin ohjelmalaskurin ohjelman ensimmäisenä suoritettavaksi tarkoitettuun käskyyn. Vielä tässäkin vaiheessa osa aliohjelmakutsujen osoitteista voidaan muuttaa vastaamaan sitä todellista osoitetta, johon aliohjelma muistiin ladattaessa sijoittui. Tämän jälkeen vastuu koneen käyttäytymisestä on ohjelmalla. Onnistunut ohjelma päättyy aina ennemmin tai myöhemmin käyttöjärjestelmän kutsuun, jossa ohjelma pyydetään poistamaan muistista.
Javan tapauksessa ajaminen suoritetaan antamalla .class tai .jar tiedosto Java-virtuaalikoneelle (Java Virtual Machine, JVM). Esimerkkimme tapauksessa komennolla
java HelloJos luokasta Hello löytyy julkinen luokkametodi (staattinen metodi) nimeltä main, niin ohjelman suoritus aloitetaan siitä. Mikäli metodia ei löydy, tulee virheilmoitus:
Exception in thread "main" java.lang.NoSuchMethodError: main
Jos haluamme ajaa aikaisemman pakettiin example kirjoitetun Hello-luokan pääohjelman, sanotaan paketti ajokomennon yhteydessä:
Jos muutat ohjelmaa, pitää muutoksen jälkeen tiedosto tallentaa, kääntää ja sitten ajaa.
Kokeile muuttaa ohjelma example/Hello.java tulostamaan oma nimesi.
6.3.5 Varoitus
Alkuperäisellä editorilla kirjoitetulla ohjelmakoodilla ei ole tavallista kirjettä kummempaa virkaa ennen kuin teksti annetaan kääntäjäohjelman tutkittavaksi. Käännöksen jälkeen alkuperäinen teksti voitaisiin periaatteessa vaikka hävittää - käytännössä se tietysti säilytetään mm. ylläpidon takia. Siis me kirjoitamme tekstiä, joka ehkä (toivottavasti) muistuttaa Java-kielen syntaksin mukaista ohjelmaa. Vasta käännös ja linkkaus tekevät todella toimivan ohjelman.
6.3.6 Integroitu ympäristö
On olemassa ohjelmankehitysympäristöjä, joissa editori, kääntäjä ja linkkeri (sekä mahdollisesti debuggeri, virheenjäljitin) on yhdistetty käyttäjän kannalta yhdeksi toimivaksi kokonaisuudeksi. Esimerkkeinä Eclipse, NetBeans, Microsoftin Visual Studio ja Borland-C++ Builder. Kaikissa listassa mainituissa kehittimissä on myös tuki käyttöliittymän suunnittelulle.
Esimerkiksi Eclipse ympäristöissä ohjelma kirjoitetaan tekstinä ja kun ohjelmakoodi on valmis, saadaan koodi käännettyä, linkitettyä ja ladattua ajoa varten vain painamalla [F11] (tai [Ctrl-F11] jos ei haluta debugata). Pikanäppäimiä voi useimmissa ympäristöissä säätää ja saada ne siten toimimaan samalla tavalla eri keskenään. Eclipsen tapauksessa yleensä lähdekoodit kirjoitetaan src-hakmeiston (source=lähdekoodi) alle ja käännetyt luokkatiedostot tulevat bin-hakemiston (binaries =binäärikoodi) alle.
Mahdollisia muita integroitujen ympäristöjen ominaisuuksia ovat mm: UML-kaavioiden ja muiden dokumenttien automaattinen tuottaminen (esim. Delphin ModelMaker, JavaDoc-yhteistoiminta Java-kehittimissä), jotka perinteisesti ovat olleet CASE-suunnitteluohjelmien aluetta. Lisäksi myös koodin generointi kaavioista onnistuu rajoitetusti.
6.4 Ohjelman yksityiskohtainen tarkastelu
Seuraavaksi tutkimme ohjelmaa lause kerrallaan:
6.4.1 Kommentointi
// Ohjelma tulostaa tekstin Hello world!tai
/* Ohjelma tulostaa tekstin Hello world! */Ohjelman alussa on kommentoitu mitä ohjelman tekee. Yleensä ohjelmakoodit on hyvä varustaa kuvauksella siitä, mitä ohjelma tekee, kuka ohjelman on tehnyt, milloin ja miksi. Milloin ohjelmaa on viimeksi muutettu, kuka ja miten.
Lisäksi jokainen vähänkin ei-triviaali lause tai lauseryhmä kommentoidaan. Kommenttien tarkoituksena on kuvata ohjelmakoodia lukevalle lukijalle se mistä on kyse.
Lohkokommentti alkaa /* -merkkiyhdistelmällä ja päättyy */ -merkkiyhdistelmään. Lohkokommentteja voidaan sijoittaa Java-koodissa mihin tahansa mihin voitaisiin pistää myös välilyönti. Rivin loppuminen ei sinänsä lopeta lohkokommenttia. Kommentin sisällä SAA esiintyä / ja *-merkkejä yhdessä tai erikseen, muttei lopettavaa yhdistelmää */.
Yleinen virhe on unohtaa lohkokommentin loppusulku pois. Mikäli esimerkissämme puuttuisi kommentin loppusulku, olisi koko loppuohjelma kommenttia ja mitään ohjelmaa ei siis olisikaan. Mikäli kääntäjä antaa vyöryn ihmeellisiä virheilmoituksia, kannattaa aina ensin tarkistaa kommenttisulkujen täsmäävyys. Tosin tähän auttaa nykyisten ohjelmointiympäristöjen värikoodien käyttö eri ohjelman osille, eli esimerkiksi kommentit näkyvät eri värisinä ja puuttuva komenttisulku paljastuu välittömästi.
Javassa yhden rivin kommentti voidaan ilmaista myös // -merkkiyhdistelmällä, jolloin rivinloppu lopettaa kommentin.
6.4.2 Miten kommentoida
Itse ohjelmakoodi kommentoidaan seuraavasti:
selviä kielen rakenteita ei saa kommentoida. Ei siis
i=5; // sijoitetaan i on 5 /* TURHA! */kuitenkin mikäli lauseella on selvä merkitys algoritmin kannalta, kommentoidaan tämä
i=5; // aloitetaan puolivälistäryhmitellään lauseet tyhjien rivien avulla loogisiksi kokonaisuuksiksi. Tällaisen kokonaisuuden alkuun voidaan laittaa kommenttirivi, joka kuvaa kaikkien seuraavien lauseiden merkitystä.
mikäli tekee mieli kommentoida lauseryhmä, kannattaa miettiä voitaisiinko koko ryhmä kirjoittaa aliohjelmaksi. Aliohjelman nimi sitten kuvaisi toimintaa niin hyvin, ettei kommenttia enää tarvittaisikaan. Kuitenkin jos näin suunnitellulle aliohjelmalle tulee iso kasa (liki 10) parametreja, täytyy asiaa ajatella uudestaan.
muuttujien nimet valitaan kuvaaviksi. Kuitenkin mitä lokaalimpi muuttujan käyttö, sitä lyhyemmäksi nimi voidaan jättää. i ja j sopivat aivan hyvin silmukkamuuttujien nimiksi ja p yms. osoittimen nimeksi (lokaalisti).
globaaleja muuttujia vältetään 'kaikin keinoin'
olioiden ansiosta globaalit muuttujat voidaan yleensä välttää kokonaan!
vakiotyyliset (alustetaan esittelyn yhteydessä eikä ole tarkoitus ikinä muuttaa) globaalit muuttujat on sallittu sellaisenaan ja niiden nimet kannattaa ehkä kirjoittaa isolla.
funktioiden paluuarvolle valitaan tietty tyyli, joka pyritään säilyttämään koko ohjelman ajan. Esimerkiksi true = onnistui ja false epäonnistui.
6.4.3 JavaDoc
/**
* Ohjelma tulostaa tekstin Hello world!
* @author Vesa Lappalainen
* @version 1.0, 03.01.2003
*/Jos tiedot annetaan Javan dokumentoinnin standardimuodossa, niin tiedostoista saadaan sitten koostettua helposti HTML-muotoinen dokumentti. JavaDocin mukainen kommentti alkaa "sululla" /** ja päättyy normaaliin kommentin loppumerkkiin.
Dokumentaatiokommenttien käyttö helpottaa dokumentaation hallitsemista. Muuttaessaan funktion toiminnallisuutta ohjelmoijan on helppo muuttaa myös dokumentaatiota, koska se on saatavilla samasta paikasta. Lisäksi kehittyneet ohjelmointiympäristöt osaavat lukea ja näyttää oikein muodostetun dokumentaation automaattisesti koodia kirjoittaessa.
Kommentointi kannattaa käytännössä tehdä yksittäisten metodien tarkkuudella. Myös tämän monisteen esimerkeistä on pyritty tekemään JavaDocin mukaisia
Lisäinformaatiota dokumentaatioon annetaan tagien muodossa @-merkillä ja sen jälkeen tulevalla avainsanalla. Esimerkistä löytyvät koodin tekijän ja version ilmoittavat @author ja @version -tagien käyttäminen on hyödyllistä vaikkapa tiimeissä tapahtuvissa ohjelmointiprojekteissa. Kaksi muuta tärkeää merkintää ovat aliohjelmatasolla käytettävät @param ja @return, joilla kuvaillaan halutut parametrit ja palautettava arvo.
Katso lisää ohjeita JavaDocin ja tagien käytöstä osoitteessa
6.4.4 package
Käytännössä jokainen Java luokka kannattaa kirjoittaa johonkin pakettiin. Tavallisimmissa käyttöjärjestelmissä paketti toteutetaan hakemistona. Kun luokka on kirjoitettu johonkin pakettiin, voidaan siihen viitata paketin nimellä import-lauseessa.
Usein paketin nimi koostuu organisaation nimestä ja jostakin tarkentimesta, esimerkiksi
package fi.jyu.mit.ohj2;Esimerkissä olevaan summa funktioon voitaisiin viitata toisessa ohjelmassa kirjoittamalla
import example.Laskuja;
...
int tulos = Laskuja.summa(1,2);
tai
import example.*;
...
int tulos = Laskuja.summa(1,2);
tai staattisiin funktoihin uudemman Javan myötä:
import static example.Laskuja.*;
...
int tulos = summa(1,2);Testaamisen kannalta packagen käyttäminen on lähes välttämätöntä, jotta erilliseen tiedostoon syntyvistä testifunktioista voidaan käyttää testattavia funktioita.
6.4.5 Valmiin kommenttilohkon lukeminen
Mikäli käytetty editori ei tue automaattisesti kommentointia, kannattaa kirjoittaa aina tarvittavat kommenttipohjat vaikka tiedostoihin a.t (alku) ja m.t (metodi) ja opetella käyttämään editorin "lisää tiedosto" toimintoa.
6.4.6 Tarvittavien luokkien esittely
Harvoin voi tehdä ohjelman joka tulee täysin toimeen ilman muiden apua. Javan tapauksessa ilman muiden luokkien apua. Jotta kääntäjä tietäisi mistä puhutaan, pitää kertoa mistä paketista luokka löytyy. Paketista java.lang löytyy System-niminen luokka, josta löytyy tarvitsemamme out-olio. Eli pitäisi oikeastaan kirjoittaa:
java.lang.System.out.println("Hello world!");Olioihin ja luokkiin paneudumme tarkemmin luvussa 9.
Jos kuitenkin samaan luokkaa tarvitaan useasti ja halutaan lyhentää kirjoittamista, voidaan import-lauseella kertoa ennen varsinaista koodin aloittamista apuna tarvittavat luokat.
import java.lang.System;Jos haluttaisiin ottaa kaikki tietyn paketin luokat käyttöön, tämä voitaisiin tehdä rivillä:
import java.lang.*;Poikkeuksen muodostaa paketti java.lang jota ei tarvitse välttämättä erikseen esitellä lainkaan. Näinhän oli tehty ensimmäisessä esimerkissämme.
C# osaajille tiedoksi, että using sanalla on vastaava toiminnallisuus on C#:ssa kuin importilla. C# ei kuitenkaan tue jokerimerkin käyttöä, joten kaikki kirjastot määritellään siinä täsmällisesti.
6.4.7 Luokan esittely
public class Hello2 {Jokainen Java-ohjelma sisältää vähintään yhden julkisen luokan. Kunkin tiedoston nimi on oltava sama kuin tiedostossa olevan julkisen luokan nimi + '.java'. Palaamme luokkiin ja olioihin tarkemmin hieman myöhemmin. Usein olio-ohjelmoinnissa on tapana että luokkien nimet aloitetaan isolla kirjaimella.
Luokan esittely ja toteutus alkaa aaltosululla { ja päättyy toiseen lopettavaan aaltosulkuun }.
6.4.8 Pääohjelman esittely
public static void main(String[] args) {Kun Java-tavukoodi ladataan muistiin, etsitään ensin ladatusta luokasta (tai muuten erikseen ilmoitetusta luokasta) pääohjelmaa, josta koodin suoritus aloitetaan. Pääohjelman nimi on aina oltava main. Oikeassa ohjelmassa on pääohjelman lisäksi useita luokkia ja metodeita (luokkien sisällä olevia aliohjelmia).
main-metodi voi olla myös useammassa luokassa, jolloin kullakin main-metodilla voidaan testata kyseisen luokan toiminta. Näin helpotetaan yksikkötestausta (modulitestausta). Tästä lisää kun pääsemme tarkemmin olioiden ja luokkien kimppuun. Huom! Javassa vain luokkien nimet aloitetaan isolla kirjaimella.
Seuraavaksi esitellään ohjelman pääohjelma ("oikea" ohjelma koostuu isosta kasasta aliohjelmia ja yhdestä pääohjelmasta, jonka nimi on main).
Käynnistettävälle ohjelmalle voidaan antaa parametrejä käynistyksen yhteydessä. Annetut parametrit voidaan "lukea" pääohjelman parametrina olevasta args taulukosta:
Vastaava ohjelma C#:illa:
Java ohjelmaa kutsuttaisiin komentoriviltä antamalla parametrit ja silloin se tulostaisi seuraavalla tavalla:
E:\kurssit\ohj2\moniste\esim\java-alk>java example.Hello3 eka toka kolmas
Argumenttejä on 3 kappaletta:
Parametri 0: eka
Parametri 1: toka
Parametri 2: kolmasMikäli parametrin halutaan sisältävän välilyöntejä, se pitää sulkea lainausmerkkeihin:
Kokeile poistaa em. ajokomennosta lainausmerkit ja kokeile niitä myös johonkin toiseen paikkaan.
6.4.9 Lausesulut
{ } |
Javassa isompi joukko lauseita kootaan yhdeksi lauseeksi sulkemalla lauseet aaltosulkuihin. Metodin täytyy aina sisältää aaltosulkupari, vaikka siinä olisi vain 0 tai 1 suoritettavaa lausetta. |
6.4.10 Tulostuslause
System.out.println("Hello world!")| System | on paketista java.lang löytyvä luokka, jossa on joukko hyödyllisiä oliota ja metodeja. |
| out | on Systemluokan olio, joka sisältää mm. tulostukseen tarvittavia metodeja. |
| println("?") | tulostaa ajonaikana sen tekstin, joka on lainausmerkkien välissä. Tulostuksen jälkeen vaihdetaan uudelle riville. Jos tarvitsee tulostaa useita eri tekstejä tai muuttujia välissä, voidaan niistä muodostaa + -operaatiolla uusi merkkijono, esimerkiksi: System.out.println("Parametri " + i + ": " + args[i]); |
6.4.11 Lauseen loppumerkki ;
; |
puolipiste lopettaa lauseen. Puolipiste voidaan sijoittaa mihin tahansa lopetettavaan lauseeseen nähden. Sen eteen voidaan jättää välilyöntejä tai jopa tyhjiä rivejä. Sen pitää kuitenkin esiintyä ennen uuden lauseen alkua. Näin Java-kieli ei ole rivisidonnainen, vaan Java-kielinen lause voi jakaantua usealle eri riville tai samalla rivillä voi olla useita Java-kielisiä lauseita. Puolipisteen unohtaminen on tyypillinen syntaksivirhe. Ylimääräiset puolipisteet aiheuttavat tyhjiä lauseita, joista tosin ei ole mitään haittaa: "Tyhjän tekemiseen ei kauan mene" - sanoo tyhjän toimittaja. |
6.4.12 Isot ja pienet kirjaimet
Isoilla ja pienillä kirjaimilla on Java-kielessä eri merkitys. Siis EI VOIDA KIRJOITTAA:
6.4.13 White spaces, tyhjä
Välilyöntejä, tabulointimerkkejä, rivinvaihtoja ja sivunvaihtoja nimitetään yleisesti yhteisellä nimellä "white space". Käännettäessä kommentit muutetaan yhdeksi välilyönniksi, joten myös kommenteista voitaisiin käyttää nimitystä "white space". Jatkossa käytämme nimitystä tyhjä tai tyhjä merkki, kun tarkoitamme "white space".
Java-koodi voi sisältää tyhjiä merkkejä missä tahansa, kunhan niitä ei kirjoiteta keskelle sanaa tai tekstiä määrittelevän ""-parin ollessa auki. ""-parin sisällä tyhjätkin merkit ovat merkityksellisiä.
Siis kääntäjän kannalta malliohjelmamme voitaisiin kirjoittaa myös seuraavillakin tavoilla:
Yleinen tyyli on kuitenkin jakaa koodia riveihin ja sisentää lohkoja muutamalla pykälällä. Kunnes lukija on varma omasta tyylistään, kannattaa matkia tässä monisteessa (ei kuitenkaan edellisiä esimerkkejä) esitettyä kirjoitustapaa ohjelmille.
6.4.14 Vakiomerkkijonot
Voimme määritellä ohjelmaamme vakioita; eli arvoja jotka esiintyvät ohjelmassa täsmälleen yhden kerran. Näin ohjelmastamme saadaan helpommin muuteltava. Esimerkiksi seuraava ohjelma tulostaisi myös tekstin "Hello world!": . Vakioiden nimet on tapana kirjoittaa isoilla kirjaimilla.
- alkeet.hello.Hello7.java - tervehdys vakioksi
6.4.15 Vakiolukuarvot
Vakiomäärittelyä voitaisiin käyttää esimerkiksi kokonaislukuvakioiden määrittelemiseen:
- alkeet.kuutio.Kuutio.java - monikulmion tiedot vakioksi
- C#-versio Kuutio-ohjelmasta.
7. Java-kielen muuttujista ja aliohjelmista
Turha koodi muuttujitta,
ompi onneton ohjelmaksi.
Parametri kutsuun pistä
aliohjelmalle argumentti.
Tarjoappa käyttöön tuota
metodia mielekästä
rutiinia riittävätä
itse tarkoin testattua.
Mitä tässä luvussa käsitellään?
- muuttujat
- malliohjelma jossa tarvitaan välttämättä muuttujia
- oliomuuttujat eli viitemuuttujat
- aliohjelmat, eli funktiot (metodit)
- aliohjelman testaaminen
- erilaiset aliohjelmien kutsumekanismit
- parametrin välitys
- lokaalit muuttujat
- pöytätesti
- yksikkötestit
Syntaksi:
Seuraavassa muut = muuttujan nimi, koostuu kirjaimista,0-9,_, ei ala 0-9
muut.esittely: tyyppi muut =alkuarvo; // 0-1 x =alkuarvo
sijoitus: muut = lauseke;
merkkijonon lukeminen, ks. Syotto-luokka
aliohj.esittely: tyyppi aliohj_nimi(tyypi muut, tyyppi muut); // 0-n x muut
aliohj.kutsu: muut = aliohj_nimi(lauseke,lauseke); // 0-1 x muut=, 0-n x lauseke
olion luonti: Tyyppi olion_nimi = new Tyyppi(parametrit);Luvun esimerkkikoodit:
7.1 Mittakaavaohjelman suunnittelu
Satunnainen matkaaja ajelee tällä kertaa kotimaassa. Autoillessa hänellä on käytössä Suomen tiekartan GT -karttalehtiä, joiden mittakaava on 1:200000. Viivoittimella hän mittaa kartalta milleinä matkan, jonka hän aikoo ajaa. Ilman matikkapäätä laskut eivät kuitenkaan suju. Siis hän tarvitsee ohjelman, jolla matkat saadaan muutettua kilometreiksi.
Millainen ohjelman toiminta voisi olla? Vaikkapa seuraavanlainen:
C:OMAMATKAAJA>matka[RET]
Lasken 1:200000 kartalta millimetreinä mitatun matkan
kilometreinä luonnossa.
Anna matka millimetreinä>35[RET]
Matka on luonnossa 7.0 km.
C:OMAMATKAAJA>matka[RET]
Lasken 1:200000 kartalta millimetreinä mitatun matkan
kilometreinä luonnossa.
Anna matka millimetreinä>352[RET]
Matka on luonnossa 70.4 km.
C:OMAMATKAAJA>Edellisessä toteutuksessa on vielä runsaasti huonoja puolia. Mikäli samalla haluttaisiin laskea useita matkoja, niin olisi kätevämpää kysellä matkoja kunnes kyllästytään laskemaan. Lisäksi olisi ehkä kiva käyttää muitakin mittakaavoja kuin 1:200000. Muutettava matka voitaisiin tarvittaessa antaa jopa ohjelman kutsussa. Voimme lisätä nämä asiat ohjelmaan myöhemmin, kunhan kykymme siihen riittävät. Toteutamme nyt kuitenkin ensin mainitun ohjelman.
7.2 Muuttujat
Ohjelmamme poikkeaa aikaisemmista esimerkeistä siinä, että nyt ohjelman sisällä tarvitaan muuttuvaa tietoa: matka millimetreinä. Tällaiset muuttuvat tiedot tallennetaan ohjelmointikielissä muuttujiin. Muuttuja on koneen muistialueesta varattu tarvittavan kokoinen "muistimöhkäle", johon viitataan käytännössä muuttujan nimellä.
Kone viittaa muistipaikkaan muistipaikan osoitteella. Kääntäjäohjelman tehtävä on muuttaa muuttujien nimiä muistipaikkojen osoitteiksi. Kääntäjälle täytyy kuitenkin kertoa aluksi, minkä kokoisia 'möhkäleitä' halutaan käyttää. Esimerkiksi kokonaisluku voidaan tallentaa pienempään tilaan kuin reaaliluku. Mikäli haluaisimme varata vaikkapa muuttujan, jonka nimi olisi matka_mm kokonaisluvuksi, kirjoittaisimme seuraavan Java-kielisen lauseen (muuttujan esittely):
int matka_mm; // yksinkertaisen tarkkuuden kokonaislukuPascal -kielen osaajille huomautettakoon, että Pascalissahan esittely oli päinvastoin:
var matka_mm: integer;Tulos, eli matka kilometreinä voitaisiin laskea muuttujaan matka_km. Tämän muuttujan on kuitenkin oltava reaalilukutyyppinen (ks. esimerkkiajo), koska tulos voi sisältää myös desimaaliosan:
double matka_km; // kaksinkertaisen tarkkuuden reaalilukuOn olemassa myös yksinkertaisen tarkkuuden reaaliluku float, mutta emme tarvitse sitä tällä kurssilla. Samoin kokonaisluvusta voidaan tehdä "tosi lyhyt", "lyhyt" tai "kaksi kertaa isompi":
int matka_km;
short sormia; // max 32767
byte varpaita; // max 127
long valtion_velka_Mmk; // Tarvitaan ISO arvoalueMuuttujan määritys voisi olla myös
volatile static long sadasosia;7.2.1 Javan alkeistietotyypit
Javan tietotyypit voidaan jakaa alkeistietotyyppeihin (primitive types) ja oliotietotyyppeihin. Oliotyyppejä käsitellään myöhemmin luvussa 8 Kohti olio-ohjelmointia. Oliotietotyyppeihin kuuluu muun muassa merkkijonojen tallennukseen tarkoitettu String-olio.
Eri tietotyypit vievät eri määrän tilaa. Nykyajan koneissa on niin paljon muistia, että ainakin Ohjelmointi 2-kurssilla kannattaa valita tietotyyppi johon varmasti mahtuu haluamamme tieto.
| Java-tyyppi | Koko | Selitys | Arvoalue |
|---|---|---|---|
| boolean | ?-bittiä | kaksiarvoinen tietotyyppi | true tai false |
| byte | 8 bittiä | yksi tavu | -128 - 127 |
| char | 16 bittiä | yksi merkki | kaikki merkit |
| short | 16 bittiä | pieni kokonaisluku | -32768 - 32767 |
| int | 32 bittiä | keskikokoinen kokonaisluku | -2147483648 - 2147483647 |
| long | 64 bittiä | iso kokonaisluku | -263 - 263-1 |
| float | 32 bittiä | liukuluku, noin 7 desimaalin tarkkuus | ±1.5 × 10-45.. ±3.4 × 1038 |
| double | 64 bittiä | tarkka liukuluku, noin 15 desim tarkkuus | ±5.0 × 10-324.. ±1.7 × 10308 |
Tulemme kuitenkin aluksi varsin pitkään toimeen pelkästään seuraavilla perustyypeillä:
short - kokonaisluvut -32 768 - 32 767, 16-bit
int - kokonaisluvut -2 147 483 648 - 2 147 483 647, 32-bit
double - reaaliluvut n. 15 desim. -> 1.7e308
char - kirjaimet 16 bit Unicode
boolean - true tai falsePrimitiivimuuttujiin liittyvät myös C#:n ja Javan suurimmat erot. Ensimmäiseksi ainoastaan positiivisille luvuille tarkoitettua unsigned tietotyyppiä ei Javasta löydy, vaan primitiivityypit voivat olla aina sekä positiivisia, että negatiivisia. Lisäksi C# on eräässä mielessä Javaa puhtaampi oliokieli, koska ohjelmoijalle päin kaikki sen tietotyypit käyttäytyvät kuin oliot (periytyvät object-kantaluokasta).
Käytännössä C#:ssa kuitenkin primitiivit muunnetaan olioiksi vasta kun se on tarpeellista (boxing), tai vastaavasti arvo voidaan muuttaa takaisin primitiivityypiksi (unboxing). Tämä siksi että malli mahdollistaa myös tehokkaan tiedonkäsittelyn ja laskennan. Olioiden käsittely on huomattavasti raskaampaa kuin primitiivimuuttujien.
Katso lisää Javan tietotyypeistä linkistä:
7.2.2 Matkan laskeminen
Ohjelman käyttämä mittakaava kannattaa sijoittaa ehkä vakioksi, tällöin ainakin ohjelman muuttaminen on helpompaa. Samoin vakioksi kannattaa sijoittaa tieto siitä, paljonko yksi km on millimetreinä (1 km = 1000 m, 1 m = 1000 mm). Ohjelmastamme tulee tällöin esimerkiksi seuraavan näköinen:
Lukija huomatkoon, että muuttujien ja vakioiden nimet on pyritty valitsemaan siten, ettei niitä tarvitse paljoa selitellä. Tästä huolimatta isommissa ohjelmissa on tapana kommentoida muuttujan esittelyn viereen muuttujan käyttötarkoitus. Mekin pyrimme tähän myöhemmin.
Syötteen lukeminen onnistui aika kivuttomasti java.util-paketista löytyvän Scanner-luokan avulla (luokista lisää myöhemmissä luvuissa). Kuten ohjelmoinnissa yleensäkin, niin saman asian voi toteuttaa kuitenkin monella tavalla. Java oli esimerkiksi vuosia ilman helppokäyttöistä tähän työhön soveltuvaa työkalua, jolloin lukemisen toteuttaminen oli huomattavasti monimutkaisempaa.
muuttujat.matka.Matka.java - mittakaavamuunnos 1:200000 kartalta
…
// Syöttöpyyntö ja vastauksen lukeminen
System.out.print("Anna matka millimetreinä>");
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String s = "";
try {
s = in.readLine();
} catch (IOException ex) {
}
if ( s == null ) return;
if ( s.equals("") ) return;
matka_mm = Integer.parseInt(s);
…
}7.2.3 Muuttujan nimeäminen
Muuttujien nimissä on sallittuja kaikki kirjaimet (myös skandit, itse asiassa kaikki Unicode-kirjaimet) sekä numerot (0-9) sekä alleviivausviiva (_). Muuttujan nimi ei kuitenkaan saa alkaa numerolla. Muuttujia saa esitellä (declare) useita samalla kertaa, kunhan muuttujien nimet erotetaan toisistaan pilkulla. Yleinen Java-tapa on että muuttujan nimi alkaa pienellä kirjaimella ja sen jälkeen jokainen muuttujan nimessä oleva alkava sana alkaa isolla kirjaimella (parasTulos).
Muuttujan nimi ei myöskään saa olla mikään vakioista (literal):
truefalsenull
eikä mikään seuraavista avainsanoista (keyword):
| abstract | double | int | strictfp * |
| assert | else | interface | super |
| boolean | extends | long | switch |
| break | final | native | synchronized |
| byte | finally | new | this |
| case | float | package | throw |
| catch | for | private | throws |
| char | goto * | protected | transient |
| class | if | public | try |
| const * | implements | return | while |
| continue | import | short | void |
| default | instanceof | static | volatile |
| do |
Tähdellä (*) merkityt sanat on Javassa varattu mahdollista myöhempää (= tulevia Javan versioita) käyttöä varten.
Vaikka muuttujan nimi saakin sisältää skandeja, kannattaa niiden käytöstä pidättäytyä toistaiseksi ainakin luokkien nimissä, koska luokan nimi on samalla tiedoston nimi ja skandit tiedostojen nimissä aiheuttavat edelleen ongelmia.
Javan nimeämiskäytännöistä katso lisää linkeistä:
http://www.oracle.com/technetwork/java/codeconventions-150003.pdf https://www.securecoding.cert.org/confluence/display/java/SEI+CERT+Oracle+Coding+Standard+for+Java
7.2.4 Muuttujalle sijoittaminen =
Muuttujalle voidaan antaa ohjelman aikana uusia arvoja käyttäen sijoitusoperaattoria = tai ++, --, +=, -=, *= jne. -operaattoreilla.
Sijoitusmerkin = vasemmalle puolelle tulee muuttujan nimi ja oikealle puolelle mikä tahansa lauseke, joka tuottaa halutun tyyppisen tuloksen (arvon). Lausekkeessa voidaan käyttää mm. operaattoreita +, -, *, / ja funktiokutsuja. Lausekkeen suoritusjärjestykseen voidaan vaikuttaa suluilla ( ja ):
kenganKoko = 42;
pi = 3.14159265358979323846;
// usein käytetään Math-luokan PI vakiota
pi = Math.PI;
pinta_ala = leveys * pituus;
ympyranAla = pi*r*r;
hypotenuusa = vastainen_kateetti / Math.sin(kulma);
matka_km = matka_mm * MITTAKAAVA/MM_KM;Seuraava sijoitus on tietenkin mieletön:
r*r = 5.0; /* MIELETÖN USEIMMISSA OHJELMOINTIKIELISSA! */Eli sijoituksessa tulee vasemmalla olla sen muistipaikan nimi, johon sijoitetaan ja oikealla arvo joka sijoitetaan.
Huom! Java-kielessä = merkki EI ole yhtäsuuruusmerkki, vaan nimenomaan sijoitusoperaattori. Yhtäsuuruusmerkki on ==.
7.2.5 Muuttujan esittely ja alkuarvon sijoittaminen
Muuttujan esittelyn (declaration) yhteydessä muuttujalle voidaan antaa myös alkuarvo (alustus, definition). Muuttujien alustaminen tietyllä arvolla on tärkeää, koska alustamattoman muuttujan arvo saattaa olla hyvinkin satunnainen. Alustamattoman muuttujan käyttö onkin jälleen eräs tyypillinen ohjelmointivirhe. Java-kääntäjä tosin ilmoittaa virheenä jos muuttujaa yritetään käyttää ennen kuin sille on annettu alkuarvo.
7.3 Muuttujan arvon lukeminen päätteeltä
Javassa tosiaan on tehty melkoisen vaikeaksi tietojen lukeminen päätteeltä. Monissa muissa kielissä esimerkiksi kokonaisluvun lukemista varten on huomattavasti yksinkertaisemmat rakenteet tarjolla:
scanf("%d",&matka_mm); /* C-kieli */
cin >> matka_mm; // C++ -kieli
readln(matka_mm); // Pascal-kieliRehellisyyden nimissä on kyllä sanottava, ettei oikeassa elämässä mikään noistakaan ole hyvä käytännön ratkaisu. Jos käyttäjä syöttää muuta kuin kokonaisluvun, on virheestä toipuminen kaikissa esitetyissä kielissä varsin työlästä.
Usein helpoin ratkaisu onkin lukea tieto ensin merkkijonoon ja sitten "kaivaa" merkkijonosta tarvittava informaatio. Tästä saadaan lisäetuna samalla se, että voidaan käsitellä myös muita kuin numeerisia arvoja eikä ohjelmasta tarvitse tehdä sellaista että jokin tietty luku tarkoittaa ohjelman lopettamista:
Anna lukuja (-99 lopettaa) > // VÄÄRIN7.3.1 Lukeminen merkkijonoon
Javassa on jonkin aikaa ollut scanner-luokka joka hieman helpottaa tätä. Tästä ei ole vielä lisätty tähän lukuun.
Javan IO-systeemi on varsin monimutkainen. Sitä ei olekaan suunniteltu aloittelevaa käyttäjää silmällä pitäen, vaan mahdollisimman laajennettavaksi. Sellaiseksi että samoilla luokilla voitaisiin hoitaa tiedon lukeminen tiedostosta ja verkosta.
// Syöttöpyyntö ja vastauksen lukeminen
System.out.print("Anna matka millimetreinä>");
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));
String s = "";
try {
s = in.readLine();
} catch (IOException ex) {
}Alkuun tarvitsemme olion, joka pystyy lukemaan kokonaisen rivin ja tunnistaa meidän puolestamme rivin lopun. Tämä saadaan aikaiseksi yhdistämällä System-luokan olio in lukijaan (InputStreamReader) ja yhdistämällä se puskuroituun lukijaan (BufferedReader):
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));Sama voitaisiin tehdä useammallakin lauseella:
InputStreamReader instream = new InputStreamReader(System.in);
BufferedReader in = new BufferedReader(instream);Tässä tapauksessa emme kuitenkaan tarvitse itse käyttää apuluokkaa instream, joten tyydymme yhden rivin versioon.
Saatu uusi olio in pystyy lukemaan päätteeltä tietoa. Esimerkiksi metodi readLine lukee kokonaisen rivin. Eli käyttäjä syöttää merkkejä päätteelle ja painaa Enter. Jos tulee jokin ongelma syöttövirran kanssa olio heittää poikkeuksen IOException. Tässä tapauksessa emme välitä poikkeuksista muuta kuin, että se on otettava vastaan (catch).
Nyt lohkon
String s = "";
try {
s = in.readLine();
} catch (IOException ex) {
}jälkeen merkkijono-oliossa s on joko päätteeltä luettu arvo tai mikäli jokin meni vikaan, niin tyhjä merkkijono. Vielä on mahdollista että syöttövirta katkaistiin kesken kaiken. Windows-konsolilla tämä tapahtuu jos painetaan Ctrl-Z ja Unix/Linux-konsolilla Ctrl-C. Tällöin olioviite s ei viittaa mihinkään (sen arvo on null).
Siksipä tutkimmekin seuraavaksi mistä on kyse ja lopetamme ohjelman ilman sen suurempia mukinoita:
if ( s == null ) return;
if ( s.equals("") ) return;Tuon voi kirjoittaa myös yhdelle riville, koska Javan ||-operaattori (tai) suorittaa totuusarvoista lauseketta vain siihen saakka kunnes totuusarvo selviää:
if ( ( s == null ) || ( s.equals("") ) ) return;Huomattakoon että myös muoto
if ( ( s == null ) | ( s.equals("") ) ) return;on syntaktisesti oikein, mutta tarkoittaa hieman eri asiaa. Looginen lopputulos molemmissa on ehdon lausekkeelle sama. Mutta | -operaattorilla molemmat lausekkeet suoritetaan aina. Ja tässä tapauksessa tämä olisi virhe jos s olisi null.
7.3.2 Lukuarvon selvittäminen merkkijonosta
Kaiken edellä mainitun jälkeen meillä on käytössä oliossa s käyttäjän syöttämä merkkijono. Seuraava ongelma on saada tämä merkkijono muutettua numeroksi, jolla voidaan jopa jotakin laskeakin. Kokonaisluvun tapauksessa tämä onnistuu käyttämällä luokkaa Integer ja pyytämällä tätä selvittämään luvun arvon:
matka_mm = Integer.parseInt(s);Mikäli käyttäjä on kiltisti syöttänyt kokonaisluvun, niin kaikki menee hienosti. Mutta jos käyttäjä antaa merkkijonon, joka on jotakin muuta kuin kokonaisluku, niin silloin parseInt heittää poikkeuksen:
bash-2.05a$ java Matka
Lasken 1:200000.0 kartalta millimetreinä mitatun matkan
kilometreinä luonnossa.
Anna matka millimetreinä>kolme
Exception in thread "main" java.lang.NumberFormatException: For input string: "kolme"
at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.lang.Integer.parseInt(Integer.java:580)
at java.lang.Integer.parseInt(Integer.java:615)
at muuttujat.matka.MatkaScan.main(MatkaScan.java:24)
bash-2.05a$Jos haluamme tästäkin siististi selvitä ja vielä ystävällisesti huomauttaa käyttäjälle, tarvitsee muunnoksen ympärille laittaa myös poikkeuskäsittely ja vielä koko lukeminen silmukkaan. Kaikkien näiden muutosten jälkeen pelkkä yhden kokonaisluvun lukeminen viekin jo likemmäksi 20 riviä ja "sotkee" muuten yksinkertaisen ohjelmamme rakenteen lähes täysin.
7.3.3 Apumetodit
Tämän takia onkin ilman muuta järkevää eristää lukemiskoodi omaksi metodikseen:
Nyt omassa ohjelmassamme voidaan korvata "koko hirveä sotku" vain yhdellä rivillä:
Lisäsimme aliohjelmaamme vielä kutsuun yhden parametrin: oletus. Näin voidaan käyttäjälle antaa mahdollisuus painaa pelkästään Enter ja silti saadaan järkevä vastaus.
Tehtävä 7.5 Oletuksen tulostaminen
Lisää apumetodiin kysyInt vielä oletusarvon tulostaminen sulkuihin ennen väkäsen tulostamista. Eli tulostus olisi:
Anna matka millimeterinä (0) >7.3.4 Apuluokat
Seuraava kysymys sitten onkin että mihin tuo apumetodi kysyInt kirjoitetaan? Yksinkertainen vaihtoehto on kirjoittaa se joko ennen tai jälkeen main-metodia. Tässä ratkaisussa olisi se huono puoli, että tuo metodi voisi olla käyttökelpoinen vaikka missä ohjelmassa. Siksipä se kannattaa kirjoittaa omaan luokkaansa. Mutta mihin tämä luokka kirjoitetaan? Yleiskäyttöisyyden nimissä tuo luokka kannattaa kirjoittaa omaan tiedostoonsa.
Kirjoitammekin koodin vaikkapa tiedostoon Syotto.java:
muuttujat.syotto.Syotto.java - kokonaisluvun lukeminen päätteeltä
import java.io.*;
/**
* Aliohjelmia tietojen lukemiseen päätteeltä
* @author Vesa Lappalainen
* @version 1.0/08.01.2003
*/
public class Syotto {
/**
* Kysytään kokonaisluku. Jos annetaan ei-luku, kysytään uudelleen.
* @param kysymys näytölle tulostettava kysymys
* @param oletus arvo jota käytetään jos painetaanpelkkä Ret
* @return käyttäjän kirjoittama kokonaisluku
*/
public static int kysyInt(String kysymys, int oletus)
{
...
}
public static void main(String[] args) {
int i;
i = kysyInt("Anna kokonaisluku",12);
System.out.println("Luku oli: " + i);
}
}7.3.5 Luokan testaaminen
Olio-ohjelmoinnin - samoin kun minkä tahansa muun ohjelmoinnin - yksi tavoite on modulaarinen testaus. Eli jokainen palanen testataan - jos suinkin vain mahdollista - omana kokonaisuutenaan. Näin lopullinen ohjelma voidaan koostaa toimiviksi todetuista palikoista.
Syotto-luokkaan on myös kirjoitettu pääohjelma ja nyt testaus voidaan tehdä ensin pelkälle Syotto-luokalle ennen sen liittämistä muuhun ohjelmaan. Komentoriviltä tämä tapahtuisi nyt vaikkapa:
bash-2.05a$ javac Syotto.java
bash-2.05a$ java Syotto
Anna kokonaisluku >
Luku oli: 12
bash-2.05a$ java Syotto
Anna kokonaisluku >392
Luku oli: 392
bash-2.05a$ java Syotto
Anna kokonaisluku >kolme
Ei numero: kolme
Anna kokonaisluku >0
Luku oli: 0
bash-2.05a$Vaikka tässä tapauksessa luokka testattiinkin lukemalla tieto päätteeltä, ei missään tapauksessa pidä tätä yleistää. Yleensä paras testiohjelma on sellainen, joka automaattisesti kokeilee testattavaa yksikköä (oliota, metodia) niillä arvoilla joilla sitä tulee kuormittaa. Hyvä testiohjelma sitten kertoo millä arvoilla yksikkö toimi kuten pitikin ja millä ei toiminut. Ihminen testaajana on kaikista testaajista huonoin, koska ihminen väsyy ja muutoksen jälkeen helposti laiskuuksissaan jättää testaamatta niillä arvoilla, jotka jo ennen muutosta oli testattu. Kuitenkin muutos saattaa tuottaa virheitä jo testattuun osaan ja siksi testi pitää aina aloittaa aivan alusta jokaisen muutoksen jälkeen.
7.3.6 Luokan käyttäminen
Nyt kun uusi luokka, tai oikeastaan tässä tapauksessa uusi apumetodi, on huolellisesti testattu, se voidaan ottaa käyttöön. Muutos ohjelmakoodiin on kertoa mistä luokasta metodi kysyInt löytyy:
import muuttujat.syotto.Syotto;
...
matka_mm = Syotto.kysyInt("Anna matka millimetreinä",0);Tehtävä 7.6 Muiden tyyppien lukeminen
Tee vastaavasti luokkaan Syotto metodit kysyDouble ja kysyString. Tuleeko paljon samanlaista koodia? Kannattaisiko käyttää jotakin hyväksi? Lisää luokan testiohjelmaan testi uusillekin metodeille.
Tehtävä 7.7 Mittakaavan kysyminen
Muuta matka-ohjelmaa siten, että myös mittakaava kysytään käyttäjältä. Mikäli mittakaavaan vastataan pelkkä [RET] pitää mittakaavaksi tulla 1:200000.
7.4 Viitteet
7.4.1 Miksi viitteet?
C-kielessä osoittimet piti opetella heti ohjelmoinnin alussa, jos halusi tehdä minkäänlaisia järkeviä aliohjelmia. C++:ssa ongelmaa voidaan kiertää viitemuuttujien (references) avulla. Javassa on myös vastaava käsite, eli kaikki Javan olio-muuttujat ovat tosiasiassa viitemuuttujia. Ne ovat kuitenkin tietyssä mielessä perinteisen C:n osoittimen ja C++:n viitteen välimuoto. Javan viitemuuttujan voi laittaa osoittamaan toistakin oliota kesken koodin. C++:n viitemuuttuja osoittaa aina samaan olioon, mihin se luotiin osoittamaan.
Tutkimme seuraavaksi Javan viitemuuttujien käyttäytymistä. Tehdään ohjelma, jossa päällisin puolin näyttäisi olevan kaksi samanlaista merkkijonoa ja kaksi samanlaista kokonaislukuoliota. Merkkijonot ovat Javassa olioita ja merkkijonomuuttujat viitteitä noihin olioihin.
- muuttujat.jono.Jonotesti.java - merkkijonoviitteet
Koodiin on rivien viereen kommentoitu mitä mikäkin rivi tulostaisi.
Javassa on kahden tyyppisiä muuttujia, aikaisemmin lueteltuja perustyyppisiä (boolean, char, byte, short, int, long, float, double) muuttujia ja sitten oliomuuttujia. Oliomuuttujat Javassa ovat aina vain viitteitä todellisiin olioihin. Edellisessä esimerkissä muuttujat s1,s2,io1,io2 ovat olioviitteitä. Silti olioviitteistä puhekielessä käytetään helposti nimitystä olio.
7.4.2 Lokaalit muuttujat
Ohjelman kaikki muuttujat ovat lokaaleja muuttujia. Eli ne on esitelty lokaalisti main-metodin sisällä eivätkä "näy" näin ollen main-metodin ulkopuolelle. Tällaisille muuttujille varataan tilaa yleensä kutsupinosta. Kun kaikki muuttujat on esitelty ja alustettu, pino voisi hieman yksinkertaistettuna olla näiden lokaalien muuttujien kohdalta suurin piirtein seuraavan näköinen:
7.4.3 Dynaaminen muisti
Javassa itse olioiden tila varataan muualta dynaamisen muistinhallinnan hoitamalta alueelta. Usein tätä muistia nimitetään keko- tai kasamuistiksi (heap). Kun ohjelmoija pyytää new-operaattorilla uuden olion, muistinhallinta etsii sopivan vapaan muistipaikan ja palauttaa viitteen tähän muistipaikkaan. Todellisuudessa olioviitteet ovat hieman monimutkaisempia. Asiasta voi lukea lisää sivuilta:
Asian ymmärtämiseksi meille kuitenkin riittää yllä piirretty yksinkertaistettu malli.
7.4.4 Viitteiden vertaaminen
Vaikka molemmat viitteet s1 ja s2 osoittavat sisällöltään samanlaiseen olioon, palauttaa vertailu
( s1 == s2 ) // onko s1 sama kuin s2, => true tai false*epätoden arvon. Miksikö? Koska vertailussa verrataan muuttujien arvoja, eli tässä tapauksessa olioviitteitä, ei itse olioita. Esimerkissä on kuviteltu että ensimmäinen "eka"-merkkijono olisi sijoittunut muistissa osoitteeseen 8010 ja toinen osoitteeseen 8040. Siis itse asiassa kysytäänkin:
( 8010 == 8040 )mikä ei ole totta. Javan primitiivityypit sen sijaan sijoittuvat suoraan arvoina pinomuistiin (tai myöhemmin olioiden attribuuttien tapauksessa oliolle varattuun muistialueeseen). Siksi vertailu
( i1 == i2 )on totta. Merkkijonoja vastaavasti myös kokonaislukuoliot io1 ja io2 käyttäytyvät samalla tavalla. Javassa on kokonaislukuoliot sitä varten, että primitiivityyppejä ei voi tallentaa Javan tietorakenneluokkiin. Piilottamalla primitiivityyppejä "kääreeseen", voidaan näitä "kääreitä" sitten tallentaa tietorakenteisiin.
7.4.5 Viitteeseen sijoittaminen
Jos sijoitetaan "olio" toiseen "olioon", niin tosiasiassa sijoitetaan viitemuuttujien arvoja, eli sijoituksen s2 = s1 jälkeen molemmat merkkijono-olioviitteet "osoittavat" samaan olioon.
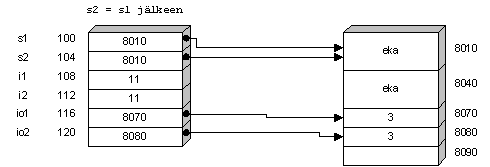
Sijoituksen jälkeen kuvassa muistipaikkaan 8040 ei osoita (viittaa) enää kukaan ja tuo muistipaikka muuttuu "roskaksi". Kun Javan roskienkeruu (garbage-collection, gc) seuraavan kerran käynnistyy, "vapautetaan" tällaiset käyttämättömät muistialueet. Tätä automaattista roskienkeruuta on pidetty yhtenä syynä Javan menestykseen. Samalla täytyy kuitenkin varoittaa että muisti on vain yksi resurssi ja Javassa on automatiikka vain muistin hoitamiseksi. Muut resurssit kuten esimerkiksi tiedostot ja tietokannat pitää edelleen hoitaa samalla huolellisuudella kuin muissakin kielissä. Jopa C++:aa huolellisemmin, koska Javassa ei ole C++:n tapaan automaattisia olioita.
- Lue lisää muistin siivouksesta Antti-Juhani Kaijanahon kandityöstä.
Javan viitemuuttuja voidaan siis laittaa "osoittamaan" milloin tahansa toista oliota. Tämä tapahtuu sijoittamalla viitemuuttujaan joko olemassa olevan olion viite
s2 = s1; // laitetaan s2 viittaamaan samaan paikkaan kuin s1tai luomalla uusi olio,
String s2 = new String("eka"); // laitetaan s2 viittaamaan uuteen olioonjolloin new-operaattorin palauttama viite sijoitetaan. Käytännössä Javan viitteet ovat siis oikeastaan osoittimia. Javan viitteillä ei kuitenkaan voi "edetä" C++:n osoittimien tapaan (esim. s1++). Tämä osoitinaritmetiikan puute on toinen Javan hyväksi puoleksi usein mainostettu ominaisuus (tosin ääneen tämä sanotaan "Javassa ei ole osoittimia", lisäksi on tosin totta että Javassa ei todellakaan ole viitteitä tai osoittimia primitiivityyppeihin).
7.4.6 null-viite
Viitemuuttujan arvo voi olla myös null. Tämä tarkoittaa sitä, ettei oliomuuttuja viittaa mihinkään todelliseen olioon ja tällaista viitemuuttujaa ei saa käyttää ennen kuin siihen on sijoitettu jonkin todellisen olion viite. Yksi Java-ohjelmien yleisimmistä virheistä onkin "null pointer reference" kun ohjelmoija ei ole huolellinen viitteiden kanssa.
Hyvin usein pitää siis testata
if ( s1 != null ) { // nyt voi käyttää s1 viitettä huoletta7.5 Aliohjelmat (metodit, funktiot)
Eräs ohjelmoinnin tärkeimmistä rakenteista on aliohjelma. C-kielessä kaikkia erityyppisiä aliohjelmia nimitetään funktioiksi; joissakin muissa kielissä eri tyyppejä erotetaan eri nimille. Javassa oikeastaan aliohjelmia nimitetään metodeiksi. Kuitenkin kaikkia tähän asti käytettyjä (staattisia) metodeja voidaan suhteellisen hyvällä omallatunnolla nimittää aliohjelmiksi tai C:n tapaan funktioiksi. Aikaisempien esimerkkien metodit nimittäin kaikki ovat olleet static-määreellä varustettuja metodeja ja tällaisten metodien virallinen nimi on luokkametodi. Lisäksi kun esimerkkiemme luokkametodit eivät ole koskeneet mihinkään luokan ominaisuuteen, ei metodeilla ole oikeastaan ollut luokan kanssa muuta tekemistä kuin se, että ne ovat olleet luokan sisällä. Tällöin niitä voi aivan hyvin kutsua aliohjelmiksi. Luokan merkitys on toistaiseksi ollut vain pitää joukkoa metodeja omassa "nimiavaruudessaan". C++:ssa vastaava rakenne hoidetaankin yleensä käyttäen nimiavaruuksia.
Aliohjelmaa käytetään seuraavissa tapauksissa:
- Haluttu tehtävä on valmiiksi jonkun toisen kirjoittamana aliohjelmana esimerkiksi standardikirjastossa (
y=Math.sin(x)) - Haluttua tehtävää suoritetaan usein liki samanlaisena joko samassa ohjelmassa tai jossain toisessa ohjelmassa.
- Haluttu tehtävä muodostaa selvän kokonaisuuden, jonka toiminta on ilmaistavissa muutamalla sanalla riittävän selkeästi (= aliohjelman nimi).
- Haluttua tehtävää ei juuri sillä hetkellä osata tai viitsitä ohjelmoida. Tällöin määritellään millainen aliohjelma tarvitaan ja kirjoitetaan tarvittavaan kohtaan pelkkä aliohjelman kutsu. Itse aliohjelma voidaan aluksi toteuttaa varsin yksinkertaisena ja korjata myöhemmin tekemään sen varsinainen tehtävä.
- Rakenne saadaan selkeämmän näköiseksi.
7.5.1 Parametriton aliohjelma
Aliohjelma esitellään vastaavasti kuin "pääohjelmakin", eli Javan main-metodi. Esimerkiksi satunnaisen matkaajan mittakaavaohjelmassa voisimme kirjoittaa käyttöohjeet omaksi aliohjelmakseen:
- muuttujat.matka.Matka_a1.java - ohjeet aliohjelmaksi
Tämän etu on siinä, että saimme pääohjelman selkeämmän näköiseksi.
7.5.2 Funktiot ja parametrit
Voisimme jatkaa pääohjelman selkeyttämistä. Tavoite voisi olla aluksi vaikkapa kirjoittaa pääohjelma muotoon:
ohjeet();
matka_mm = Syotto.kysyInt("Anna matka millimetreinä",0);
matka_km = mittakaava_muunnos(matka_mm);
tulosta_matka(matka_km);Tällainen pääohjelma tuskin tarvitsisi paljoakaan kommentteja.
Edellä on käytetty kolmen eri tyypin aliohjelmia (funktioita)
ohjeet();- parametriton aliohjelmamittakaava_muunnos(matka_mm);- funktio, joka palauttaa tuloksen nimessääntulosta_matka(matka_km);- aliohjelma, jolle vain viedään arvo, mutta mitään arvoa ei palauteta
Valmis ohjelma, jossa myös aliohjelmat on esitelty, näyttäisi seuraavalta (rivien numerointi on myöhemmin esitettävää pöytätestiä varten):
- muuttujat.matka.Matka_a3.java - erilaisia funktioita
Edellä olevasta huomataan, että aliohjelmat jotka eivät palauta mitään arvoa nimessään, esitellään void-tyyppisiksi.
mittakaava_muunnos on reaaliluvun palauttava funktio, joten se esitellään double -tyyppiseksi.
Seuraavaksi pöytätestaamme ohjelmamme toiminnan:
|----------------------------------------------------------------------------------|
| | main | mi..muunnos | tulosta | |
|-------------|-------------------|-----------------|-----------|------------------|
| lause |matka_mm| matka_km | matka_mm| tulos | matka_km | tulostus |
|-------------|--------|----------|---------|-------|-----------|------------------|
|46 ohjeet() | ?? | ?? | | | | |
|13-17 System | | | | | | Lasken 1:2000000 |
|47 matka_mm= | 352 | | | | | Anna matka ... |
|48 matka_km | | | 352 | | | |
|26 return | | | | 70.4 | | |
|48 matka_km | | 70.4 | | | | |
|49 tulosta | | | | | 70.4 | |
|33-36 System | | | | | | Matka on luo.... |
|50 } | | | | | | |
|----------------------------------------------------------------------------------|Emme enää käyneet läpi sitä, mitä Syotto.kysyInt tekee, koska se oli testattu erikseen ja sen jälkeen aliohjelma voidaan käsittää "valmiina kieleen kuuluvana käskynä".
Mikäli kukin "omatekoinen" aliohjelmakin olisi testattu erikseen, riittäisi meille pelkkä pääohjelman testi:
|----------------------------------------------------|
| | main | |
|-------------|-------------------|------------------|
| lause |matka_mm| matka_km | tulostus |
|-------------|--------|----------|------------------|
|46 ohjeet() | ?? | ?? | |
|47 matka_mm= | 352 | | Anna matka ... |
|48 matka_km | | 70.4 | |
|49 tulosta | | | Matka on luo.... |
|50 } | | | |
|----------------------------------------------------|Tämä on testaustapa, johon tulisi pyrkiä. Isossa ohjelmassa ei ole enää mitään järkeä testata sitä jokainen aliohjelma kerrallaan. Koodiin liitettyjen aliohjelmien tulee olla testattuja kukin erillisinä ja lopullinen testi on vain viimeisimmän mallin mukainen!
7.5.3 Parametrin nimi kutsussa ja esittelyssä
Huomattakoon, ettei parametrien nimillä aliohjelmien esittelyissä ja kutsuissa ole mitään tekemistä keskenään. Nimi voi olla joko sama tai eri nimi. Parametrien idea on nimenomaan siinä, että samaa aliohjelmaa voidaan kutsua eri muuttujien tai mahdollisesti vakioiden tai lausekkeiden arvoilla. Esimerkiksi nyt kirjoitettua tulosta_matka aliohjelmaa voitaisiin kutsua myös seuraavasti:
- muuttujat.matka.Matka_a4.java - erilaisia tapoja kutsua funktiota
Edellä aliohjelman kutsut voidaan tulkita seuraaviksi sijoituksiksi aliohjelman tulosta_matka lokaaliin parametrimuuttujaan matka_km:
matka_km = d;
matka_km = 30.7;
matka_km = d+20.8;
matka_km = 2*d-30.0Aliohjelma jouduttiin edellä vielä kirjoittamaan uudestaan (käytännössä kopioimaan edellisestä ohjelmasta), mutta myöhemmin opimme miten aliohjelmia voidaan kirjastoida standardikirjastojen tapaan (ks. moduuleihin jako), jolloin kerran kirjoitettua aliohjelmaa ei enää koskaan tarvitse kirjoittaa uudestaan (eikä kopioida).
7.5.4 Funktiot
Funktion arvo palautetaan return -lauseessa. Jokaisessa ei-void -tyyppiseksi esitellyssä funktiossa tulee olla vähintään yksi return -lause jonka perässä on funktion tyyppiä oleva lauseke. void-tyyppisessäkin voi olla return-lause, mutta silloin siinä ei ole lauseketta perässä. Tarvittaessa return-lauseita voi olla useampiakin:
Kun return -lause tulee vastaan, lopetetaan HETI funktion suoritus. Tällöin myöhemmin olevilla lauseilla ei ole mitään merkitystä. Näin ollen useat return-lauseet ovat mielekkäitä vain ehdollisissa rakenteissa. Siis seuraavassa ei olisi mitään mieltä:
return-lausetta ei saa sotkea siihen, että parametrina vietyjä olioita voidaan pyytää muuttamaan sisältöään funktion aikana:
- muuttujat.funktio.FunJaOlio.java - sivuvaikutuksellinen funktio
Edellä ei kutsusta näe millään tavalla, että kutsun jälkeen jono on muuttunut. Yhtenä Java-kielen miinuksena voidaankin pitää sitä, että siitä puuttuu C++-kielessä oleva mekanismi suojata oliot muutoksilta aliohjelman suorituksen aikana (const).
Näin paljon jääkin ohjelmoijan vastuulle, eli ohjelmoijan pitää nimetä aliohjelmat siten, että niiden nimi jo paljastaa jos jotakin parametria muutetaan ohjelman suorituksen aikana. Ja sitten aliohjelmat on tehtävä huolellisesti, etteivät ne todellakaan muuta kutsuparametrejaan jollei se ole aliohjelmien tarkoitus.
7.5.5 Ketjutettu kutsu
Koska funktio-aliohjelma palauttaa valmiiksi arvon, voitaisiin Matka_a3.java:n pääohjelma kirjoittaa myös muodossa:
Funktioita käytetään silloin, kun aliohjelman tehtävänä on palauttaa vain yksi täsmällinen arvo. Math-luokan funktioita ovat:
abs, acos, asin, atan, atan2, ceil, cos, exp, floor, IEEEremainder, log,
max, min, pow, random, rint, round, sin, sqrt, tan, toDegrees,
toRadiansFunktioita käytetään, kuten matematiikassa on totuttu:
kysy_matka ja kysy_mittakaava voitaisiin kirjoittaa myös funktioiksi, ja tällöin niitä voitaisiin kutsua esim. seuraavasti:
matka_km = kysy_matka()*kysy_mittakaava()/MM_KM;Vaarana olisi kuitenkin se, ettei voida olla aivan varmoja kumpi funktiosta kysy_matka vai kysy_mittakaava suoritettaisiin ensin ja tämä saattaisi aiheuttaa joissakin tilanteissa yllätyksiä.
Tämän vuoksi pyrimmekin kirjoittamaan funktioiksi vain sellaiset aliohjelmat, jotka palauttavat täsmälleen yhden arvon ja jotka eivät ota muuta informaatiota ympäristöstä kuin sen mitä niille parametrina välitetään. Eli tavoitteena on se, että funktioiden kutsuminen lausekkeen osana olisi turvallista. Tämä ei valitettavasti ole aina Javassa mahdollista, koska Javan aliohjelmakutsuista puuttuu muissa kielissä oleva muuttujaparametrin välitys (Pascal: var, C: osoitin *, C++ referenssi &).
Muissa kielissä aliohjelmat kirjoitamme siten, että arvot palautetaan osoitteen avulla. Hyvin yleinen C-tapa on kuitenkin palauttaa tällaisenkin aliohjelman onnistumista kuvaava arvo funktion nimessä (vrt. esim. scanf C-kielessä).
Tehtävä 7.10 Math-luokka
Katso SDK:n dokumenteista kunkin Math-luokan funktion parametrien määrä ja tyyppi sekä se mitä kukin todella tekee.
Tehtävä 7.11 Funktiot
Kirjoita edellä mainitut kysy_matka ja kysy_mittakaava nimessään arvon palauttavina funktioina.
Tehtävä 7.13 Pääohjelma yhtenä funktiokutsuna
Jatka edellä mainittua ketjuttamista siten, että koko pääohjelma on vain yksi lauseke (ohjeet-kutsu saa olla oma rivinsä jos haluat). Tosin tämä on C-hakkerismia, eikä mikään tavoite helposti luettavalta ohjelmalta. Itse asiassa hyvä kääntäjä tekee automaattisesti tämän kaltaista optimointia (mitä muka voitiin säästää?).
7.5.6 Yksinkertaisen aliohjelman kutsuminen
Valmiin aliohjelman kutsuminen on helppoa: etsitään aliohjelman esittely ja kirjoitetaan kutsu, jossa on vastaavan tyyppiset parametrit vastaavissa paikoissa.
Esimerkiksi funktion Math.sin esittely saattaa olla muotoa:
sin
public static double sin(double a)
Returns the trigonometric sine of an angle. Special cases:
- If the argument is NaN or an infinity, then the result is NaN.
- If the argument is zero, then the result is a zero with the same
sign as the argument.
A result must be within 1 ulp of the correctly rounded result.
Results must be semi-monotonic.
Parameters:
a - an angle, in radians.
Returns:
the sine of the argument.Funktion tyyppi on double ja sille viedään double-tyyppinen parametri. Funktio ei muuta mitään parametrilistassa esiteltyä parametriaan (mistä tietää?). Siis funktiota ei ole mitään mieltä kutsua muuten kuin sijoittamalla sen palauttama arvo johonkin muuttujaan tai käyttämällä funktiota osana jotakin lauseketta. x:ää vastaava parametri voi olla mikä tahansa double tyyppisen arvon palauttava lauseke (tietysti mielellään sellainen joka tarkoittaa kulmaa radiaaneissa):
Funktiota voitaisiin tietysti kutsua myös muodossa:
mutta kutsussa olisi yhtä vähän järkeä kuin kutsussa
tai jopa
3.0; // TYHMÄÄMihin lausekkeiden arvot menisivät? Eivät minnekään! Tosin Javassa kääntäjäkään ei päästä lävitse kahta viimeksi mainittua vaihtoehtoa, eli pelkää vakioita tai muuttujia sisältävää lauseketta, jota ei sijoiteta mihinkään.
Usein aloittelijan näkee yrittävän kutsua muodoissa
mutta näissäkään ei ole järkeä, koska parametrin tyypin esittely kuuluu vain aliohjelman otsikon puoleiseen päähän, ei kutsupäähän.
7.5.7 Aliohjelmat tulostavat harvoin
Yksi yleinen aloittelijan virhe on tehdä paljon aliohjelmia, jotka tulostavat. Pikemminkin pitää toimia päinvastoin, eli aliohjelmien on tehtävä oma työnsä ja annettava sitten tulokset muille tulostettavaksi.
Jos halutaan että aliohjelma kuitenkin tulostaa, niin useimmiten sille kannattaa siinä tapauksessa viedä parametrina tietovirta johon tulostetaan. Samoin tulostavien aliohjelmien nimessä kannattaa tavalla tai toisella ilmaista että aliohjelma aikoo tulostaa. Palaamme tähän esimerkin kanssa seuraavissa luvuissa. Alla kuitenkin pikainen esimerkki:
- muuttujat.tulostus.Tulostustesti.java - tulostus näytölle ja tiedostoon
7.5.8 Jäsenten tulostaminen
Tietovirtojen ansiosta samoja aliohjelmia voidaan käyttää myös järjestelmässä, jossa varsinaista konsolitulostusta ei voi tehdä. Tällaisia ovat mm. graafiset käyttöliittymät.
Myös kerho-ohjelman on tarkoitus tulostaa jäsenten tietoja. Kun ongelmaa miettii tarkemmin, niin ei ole juuri mitään mieltä tehdä tulostusikkunaa pelkästään yhteen tarkoitukseen. Kannattaa siis luoda tietovirtojen avulla yleiskäyttöinen ikkuna.
- HT5.1 KerhoGUIController.java - tulostamisikkunan avaaminen
@FXML private void handleTulosta() {
TulostusController tulostusCtrl = TulostusController.tulosta(null);
tulostaValitut(tulostusCtrl.getTextArea());
}Ensimmäisellä rivillä luodaan uusi ikkuna, sitten kutsutaan tulostaValitut()-metodia, jolle viedään parametrina juuri luodun ikkunan tekstikenttä.
Seuraavassa luodaan oma tietovirta TextAreaOutputStream, jolle viedään edelleen parametrina tulostusikkunan tekstikenttä. Nyt viimeisellä rivillä tulostaa kenttään, samalla tavoin kun tulostaisimme esimerkiksi System.out -tietovirtaan.
/**
* Tulostaa listassa olevat jäsenet tekstialueeseen
* @param text alue johon tulostetaan
*/
public void tulostaValitut(TextArea text) {
try (PrintStream os = TextAreaOutputStream.getTextPrintStream(text)) {
os.println("Tulostetaan kaikki jäsenet");
os.println("Tähän tulostuisi jäsenten tiedot");
}
}Toisaalta viimeisin vaihe on ehkä hieman turha. Nykyaikaisessa käyttöliittymäohjelmoinnissa tietovirrat eivät useinkaan ole käytännöllisin tapa siirtää tekstiä. Nyt kuitenkin Kerhon vanha versio on toiminut komentorivin päällä, joten siellä löytyy valmiit metodit tietovirtojen käyttöön. Olisi myös ollut mahdollista käyttää tekstikenttää suoraan.
tulostusCtrl.getTextArea().setText("Tähän tulostuisi jäsenten tiedot");Itse tulostusikkunaan riittää yksinkertainen rakenne yhdellä tekstikentällä ja muutamalla napilla. Tekstikenttä kannattaa jättää käyttäjän editoitavaksi.
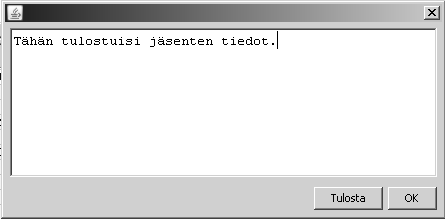
Nyt rakennettuna on yleiskäyttöinen tulostusikkuna. Jäljellä on vielä painikkeiden toiminnallisuuden ohjelmointi. Ok-napin painaminen sulkee ikkunan.
@FXML private void handleOK() {
ModalController.closeStage(tulostusAlue);
}Itse tulostamiseen Swing-kirjasto tarjoaa helposti käytettävät työkalut.
@FXML private void handleTulosta() {
JTextArea jtext = new JTextArea(getTextArea().getText());
try {
jtext.print();
} catch (PrinterException e) {
System.err.println("Tulostaminen ei onnistunut");
}
}Suoraan JavaFX:ssä tulostaminen voitaisiin hoitaa PrinterJob ja WebEngine-luokkien avulla.
@FXML private void handleTulosta() {
// Dialogs.showMessageDialog("Ei osata vielä tulostaa");
PrinterJob job = PrinterJob.createPrinterJob();
if ( job != null && job.showPrintDialog(null) ) {
WebEngine webEngine = new WebEngine();
webEngine.loadContent("<pre>" + tulostusAlue.getText() + "</pre>");
webEngine.print(job);
job.endJob();
}
}7.6 Parametrinvälitys
7.6.1 Useita parametreja
Suuressa osassa edellisissä esimerkeissämme meillä on ollut vain 0 tai yksi parametria välitettävänä aliohjelmaan. Käytännössä usein tarvitsemme useampia parametreja. Esimerkiksi edellisessä paamenu-aliohjelmassa pitäisi oikeastaan tulostaa myös kerhon nimi.
Ottakaamme esimerkiksi mittakaava_muunnos -funktio. Mikäli ohjelma haluttaisiin muuttaa siten, että myös mittakaavaa olisi mahdollista muuttaa, pitäisi myös mittakaava voida välittää muunnos-aliohjelmalle parametrina. Kutsussa tämä voisi näyttää esim. tältä:
matka_km = mittakaava_muunnos(32,10000.0);Vastaavasti funktio-esittelyssä täytyisi olla kaksi parametria:
Kun kutsu suoritetaan, välitetään aliohjelmalle parametrit siinä järjestyksessä, missä ne on esitelty. Voitaisiin siis kuvitella aliohjelmakutsun aiheuttavan sijoitukset aliohjelman parametrimuuttujiin (tosin sijoitusjärjestystä ei taata, eli ei tiedetä kumpi sijoitus suoritetaan ensin):
mittakaava = 10000.0;
matka_mm = 32;Jos kutsu on muotoa
matka_km = mittakaava_muunnos(matka_mm, MITTAKAAVA);kuvitellaan sijoitukset:
matka_mm = matka_mm; // Pääohjelman muuttuja matka_mm sijoitetaan aliohjelman
// vastinpaikassa olevaan muuttujaan
mittakaava = MITTAKAAVA; // Ohjelman vakio toiseeen aliohjelman muuttujaanSiis vaikka kutsussa ja esittelyssä esiintyykin sama nimi, ei nimien samuudella ole muuta tekemistä kuin mahdollisesti se, että turha on väkisinkään keksiä lyhennettyjä huonoja nimiä, jos kerran on hyvä nimi keksitty kuvaamaan jotakin asiaa.
Parametreista osa, ei yhtään tai kaikki voivat olla myös oliota.
Huom! Vaikka kaikilla aliohjelman parametreille olisikin sama tyyppi, täytyy jokaisen parametrin tyyppi mainita silti erikseen:
public static double nelion_ala(double korkeus, double leveys)Tehtävä 7.14 Päämenuun kerhon nimi
Lisää Paamenu.java:n aliohjelmaan paamenu parametriksi myös kerhon nimi.
7.6.2 Parametrin paikka ratkaisee, ei nimi
Aloitteleva ohjelmoija sotkee yleensä aliohjelmakutsua tehdessään kutsuvan ja kutsuttavan parametrien nimiä keskenään. Parametrien nimillä ei ole Java-kielessä mitään merkitystä. Aliohjelmakutsussa ratkaisee vain parametrien paikka. Kunkin kutsussa oleva arvo "sijoitetaan" vastinparametrilleen kun aliohjelmaan mennään. Seuraava esimerkki havainnollistaa tätä:
- muuttujat.funktio.Parampaikka.java - parametrin paikka kutsussa ratkaisee
On olemassa myös kieliä, joissa parametrit ovat nimettyjä. Tällainen on tarpeen jos parametreja on niin paljon, ettei niitä kaikkia välitetä joka kutsussa. Esimerkki tällaisesta kielestä on vaikkapa Microsoft Visual Basic for Application (VBA) ja C#.
7.6.3 Metodin nimen kuormittaminen
Javassa - samoin kuin monessa muussakin nykykielessä - on mahdollista kuormittaa (overload) aliohjelman nimeä. Eli samassa näkyvyysalueessa saa esiintyä samannimisiä aliohjelmia kunhan niiden parametrit eroavat toisistaan määrältään ja/tai tyypiltään.
Kääntäjä pystyy kutsussa päättelemään oikean aliohjelman parametrien määrän ja tyypin mukaan.
7.6.4 Muuttujien lokaalisuus
Kukin aliohjelma muodostaa oman kokonaisuutensa. Edellä olleissa esimerkeissä aliohjelmat eivät tiedä ulkomaailmasta mitään muuta, kuin sen, mitä niille tuodaan parametreina kutsun yhteydessä.
Vastaavasti ulkomaailma ei tiedä mitään aliohjelman omista muuttujista. Näitä aliohjelman lokaaleja muuttujia on esim. seuraavassa:
Yleensäkin Java-kielessä lausesulut { ja } muodostavat lohkon, jonka ulkopuolelle mikään lohkon sisällä määritelty muuttuja tai tyyppimääritys ei näy. Näkyvyysalueesta käytetään englanninkielisessä kirjallisuudessa nimitystä scope. Lokaaleilla muuttujilla voi olla vastaava nimi, joka on jo aiemmin esiintynyt jossakin toisessa yhteydessä. Lohkon sisällä käytetään sitä määrittelyä, joka esiintyy lohkossa:
- muuttujat.nakyvyys.Lokaali.java - lokaalien muuttujien näkyvyys
Ohjelma tulostaa:
Kirjain A
Kokonaisluku 5
Reaaliluku 4.5
Kirjain ASaman tunnuksen käyttäminen eri tarkoituksissa on kuitenkin kaikkea muuta kuin hyvää ohjelmointia.
7.6.5 Parametrinvälitysmekanismi
Ainoa Java-kielen tuntema parametrinvälitysmekanismi on parametrien välittäminen arvoina. Tämä tarkoittaa sitä, että aliohjelma saa käyttöönsä vain (luku)arvoja, ei muuta. Olkoon meillä esimerkiksi ongelmana tehdä aliohjelma, jolle viedään parametreina tunnit ja minuutit sekä niihin lisättävä minuuttimäärä. Jos ensimmäinen yritys olisi seuraava:
- muuttujat.funktio.Aikalisa.java - yritys lisätä arvoja
Tämä ei tietenkään toimisi! Hyvä (C-) - kääntäjä jopa varoittaisi että:
Warn : aikalisa.cpp(8,2):'m' is assigned a value that is never used
Warn : aikalisa.cpp(7,2):'h' is assigned a value that is never usedMutta miksi ohjelma ei toimisi? Seuraavan selityksen voi ehkä ohittaa ensimmäisellä lukukerralla. Tutkitaanpa tarkemmin mitä aliohjelmakutsussa oikein tapahtuu. Oikaisemme seuraavassa hieman joissakin kohdissa liian tekniikan kiertämiseksi, mutta emme kovin paljoa. Esimerkki on kirjoitettu vastaavasta C++-ohjelmasta. Javassa periaatteessa tapahtuu samalla tavalla. Katsotaanpa ensin miten kääntäjä kääntäisi aliohjelmakutsun (Borland C++ 5.1, 32-bittinen käännös, rekisterimuuttujat kielletty jottei optimointi tekisi konekielisestä ohjelmasta liian monimutkaista):
lisaa(h,m,55);
muistiosoite assembler selitys
-------------------------------------------------------------------------
004010F9 push 0x37 pinoon 55
004010FB push [ebp-0x08] pinoon m:n arvo
004010FE push [ebp-0x04] pinoon h:n arvo
00401101 call lisaa mennään aliohjelmaan lisää
00401106 add esp,0x0c poistetaan pinosta 12 tavua (3 x int)Kun saavutaan aliohjelmaan lisaa, on pino siis seuraavan näköinen:
muistiosoite sisältö selitys
------------------------------------------------------------------------
064FDEC 00401106 <-ESP paluuosoite kun aliohjelma on suoritettu
064FDF0 0000000C h:n arvo, eli 12
064FDF4 0000000F m:n arvo, eli 15
064FDF8 00000037 lisa_min, eli 55Eli aliohjelmaan saavuttaessa aliohjelmalla on käytössään vain arvot 12,15 ja 55. Näitä se käyttää tässä järjestyksessä omien parametriensa arvoina, eli m, h, lisa_min.
Esimerkiksi Pascal ja C/C++ sekä C# -kielissä olisi tarjota tähän sellainen ratkaisu, että aliohjelman parametrit olisivatkin viitteitä (tai osoittimia) kutsuvan ohjelman muuttujiin ja niihin tehty muutos muuttaisi suoraan kutsuvan ohjelman muuttujia. Javassa tämä on mahdollista vain olioille, koska oliot välitettiin viitteinä.
C++: void lisaa(int &h, int &m, int lisamin); kutsu: lisaa(h,m,55);
Pascal: procedure lisaa(var h,m:integer; lisamin:integer); kutsu: lisaa(h,m,55);
C: void lisaa(int *h, int *m, int lisamin); kutsu: lisaa(&h,&m,55);
C#: void Lisaa(ref int h, ref int m, int lisamin); kutsu: Lisaa(ref h,ref m,55);7.6.6 Aliohjelmien kirjoittaminen
Uuden aliohjelmien kirjoittaminen kannattaa aina aloittaa aliohjelmakutsun kirjoittamisesta vähintään testiohjelmaan. Näin voidaan suunnitella mitä parametreja ja missä järjestyksessä aliohjelmalle viedään. Näinhän teimme mittakaava-ohjelmassakin.
7.6.7 Luokkamuuttujat ja suhde lokaaleihin muuttujiin
Muuttujat voidaan esitellä myös luokan kaikissa metodeissa näkyväksi. Mikäli muuttujat esitellään kaikkien ohjelman aliohjelmalausesulkujen ulkopuolella, näkyvät muuttujat koko luokan alueella. Jos muuttujat vielä varustetaan vaikkapa public määreellä, niin luokan ulkopuolisetkin luokat voivat niitä käyttää. Tällaista on syytä välttää. Seuraava ohjelma on kaikkea muuta kuin hyvän ohjelmointitavan mukainen, mutta pöytätestaamme sen siitä huolimatta:
Käsittelemme (huonosti nimettyjä) metodeja i ja set "operaattoreina", eli oletamme niiden toiminnan tunnetuksi, eikä pöytätestissä askelleta niihin sisälle.
Pöytätestin tekeminen aloitetaan piirtämällä sarakkeet kutakin isompaa ohjelmassa olevaa kokonaisuutta varten. Esimerkissä näitä ovat
- suoritettava lause
- luokkamuuttujat
- main-metodi
- metodit ali_1 ja ali_2
- keko
- lisäksi kannattaa laskea välitulokset jonnekin auki
Sitten kukin sarake jaetaan vielä osiin siinä olevien muuttujien määrän mukaan. Kekoa varten tarvitaan karkeasti yhtä monta saraketta kuin ohjelmassa on suoritettavia new-operaattoreita (tai String a = "kissa"; tyyppisiä lauseita) .
Lyhyyden vuoksi olemme seuraavassa merkinneet N1 = ensimmäinen new:llä luotu olio ja N2 on toinen. Lisäksi on otettu c-mäinen merkintä &N1, eli viite olioon N1. Merkintä L.c tarkoittaa seuraavassa luokan muuttuja c (jos on vaara sekaantua muuhun). Merkintää := on käytetty välilaskutoimituksissa erottamaan sijoitusta = -merkistä. Merkintä * muuttujien yläpuolella on muistutuksena sitä, että kyseessä on viitemuuttujat ja niiden käsittely muuttaa aina jotakin muuta muistipaikkaa. Pöytätestissä siis sarakkeet ovat muistipaikkoja ja rivit muistipaikkojen arvo tiettynä ajanhetkenä. Muistipaikka on merkitty harmaalla jos se ei ole voimassa tiettynä ajanhetkenä.

TODO: Rivillä 15 lasku olisi nätimpi jos olisi 2+41 niin olisi oikeinpäin...
Luokkamuuttujat ovat rinnastettavissa globaaleihin muuttujiin. Samoin kun seuraavassa luvussa päästään käsiksi varsinaiseen olio-ohjelmointiin, niin myös julkiset attribuutit ovat rinnastettavissa globaaleihin muuttujiin. Globaaleiden muuttujien käyttöä tulee ohjelmoinnissa välttää. Tuskin mistään on tullut yhtä paljon ohjelmointivirheitä, kuin vahingossa muutetuista globaaleista muuttujista!
Käytännössä pöytätestiä voidaan monesti korvata hyvällä debuggerilla. Debuggerista valitettavasti ei useinkaan näe suorituksen historiaa. Ennen kun debuggerit eivät olleet niin yleisiä, korvattiin niitä sijoittamalla ohjelmakoodin sekaan muuttujien arvoja tulostavia lauseita. Joissakin tapauksissa tähänkin vielä joudutaan turvautumaan.
7.7 Testipääohjelmat
Tähän mennessä esimerkit on testattu vain testipääohjelmilla. Tapa on toimiva kun toteutettavan ohjelmiston koko on pieni ja kaikki sen moduulit voi käydä suhteellisen pienellä työllä läpi.
Monisteessa aiemmin esiteltiin Alkulukuohjelma. Kirjoitetaan aliohjelmalle vielä testiohjelma, joka kertoo saatiinko haluttu tulos ja pääohjelma jolla ajetaan useita testejä:
- muuttujat.testaus.Alkuluku.java
Ohjelmiston koon kasvaminen asettaa kuitenkin uusia haasteita testaukselle.
- Mitä tehdä tilanteessa, jossa tehdään muutos funktioon, jota jo useat ohjelman osat käyttävät? Testipääohjelmilla joudutaan käymään käsin läpi jokainen moduuli, jotta voimme varmistua siitä ettei mikään mennyt rikki.
- Ohjelmakoodin sekaan kirjoitetut testit jäävät rasittamaan ohjelman tuotantoversiota.
- Koodin luettavuus heikkenee, kun testausrutiinit paisuttavat yksinkertaistakin varsin suureksi.
7.8 Yksikkötestaus
Ratkaisuksi edellä esiteltyihin ongelmiin on kehitetty menetelmä nimeltä yksikkötestaus (Unit Testing). Testipääohjelmien käyttö on jo periaatteessa eräänlaista yksikkötestausta, mutta nykyään termillä viitataan lähinnä ympäristöihin ja työkaluihin joilla testausta voidaan helpottaa ja automatisoida mahdollisimman pitkälle. Varsinaisten testitapausten (test case) lisäksi voidaan rakentaa myös koko projektin laajuisia testisarjoja (test suite), jotka voi ajaa vaikkapa automaattisesti yön aikana.
Nykyisin suosittu ohjelmointitekniikka on testivetoinen kehitys (Test Driven Development, TDD). Sen idea on kehittää koodi valmiiksi testattavaksi ja tehdä testit etukäteen, jonka jälkeen vasta aloitetaan itse ohjelmointi. Suunnitteluvaiheessa tapahtuva testaus selkeyttää ohjelman rakennetta ja toimintaa, jolloin se on helppo toteuttaa suoriutumaan halutuista selkeistä vaatimuksista. Kyse ei siis ole niinkään testauksesta, vaan ohjelman suunnittelusta, jonka sivutuotteena syntyvät kaikki testitapaukset.
Alkuun testien tekeminen saattaa vaikuttaa ylimääräiseltä työltä. Käytännössä kokeneinkin ohjelmoija joutuu kuitenkin joka tapauksessa kokeilemaan ohjelmansa toiminnallisuuden tavalla tai toisella. Kattavien testitapauksen kirjoittaminen etukäteen minimoi tällaiset turhat häiriöt ja mahdollistaa keskittymisen itse asiaan. Yksikkötestaukseen käytettävät kirjastot sisältävät myös valmiita funktioita tavallisimpiin testausrutiineihin, kuten esimerkin merkkijonojen vertailuun.
7.9 JUnit
Javassa yksikkötestaus tapahtuu yleensä JUnit -kirjastolla, jota kehitysympäristöt kuten Eclipse ja NetBeans tukevat suoraan. Testit on mahdollista ohjelmoida hieman testipääohjelmien tapaan suoraan testattavan asian yhteyteen, mutta tavallisesti testit kuitenkin erotetaan erillisiin paketteihin. JUnit-testit erotetaan muusta koodista @test -tagilla. Edellisen ohjelman testaus lyhentyy muotoon.
Isommissa projekteissa JUnit testit toteutetaan vähintäänkin erilliseen pakettiin ja omiin luokkiinsa, jolloin niiden ylläpitäminen ja organisoiminen on helpompaa. Molemmat tavat ovat kuitenkin täysin oikein ja esimerkiksi kurssin demojen testaaminen onnistuukin varmasti helpoiten luokan yhteyteen kirjoittamalla. Isompia kuin yhden tai muutaman luokan ohjelmia testattaessa kannattaa kuitenkin eristää testaus itse ohjelmasta.
7.10 ComTest
Kurssilla on myös mahdollista käyttää yksikkötestaukseen ComTest-työkalua. ComTest on ohjelma, joka generoi oman makrokielensä pohjalta täysin validia Java/JUnit -koodia. Makrokieli kirjoitetaan suoraan testattavan metodin tai luokan kommentteihin. Hieman samanlainen menetelmä on käytössä mm. Python-ohjelmointikielen doctest -kirjastossa.
ComTest pyrkii tekemään testien kirjoittamisen tekeminen vähemmän työlääksi ja helpommin ylläpidettäväksi. Ajatuksena on että kun testejä ei piiloteta eri tiedostoon, niin ohjelmoijalla on yksi askel vähemmän päästä niihin käsiksi. Lisäksi kun tämän lähestymistavan yhdistää yksinkertaiseen makrokieleen, niin samalla saadaan myös käyttöesimerkit dokumentaatioon. Yhdellä kertaa ohjelmoija voi siis periaatteessa suunnitella, testata ja dokumentoida koodinsa!
Lisäksi voidaan asentaa Eclipse-liitännäinen, jolla testien kirjoittamista Eclipsessä voidaan vielä helpottaa.
7.10.1 ComTestin makrokieli
Nyt onkoAlkuluku-aliohjelman testaus muuttuu muotoon
Testi alkaa kommenttilohkoon kirjoitetulla @example -tagilla. Käytetyt <pre\> -tagit ovat normaalia html-koodia JavaDoc-dokumentaatiota varten. Niiden sisälle voi kirjoittaa ComTest-makrokieltä ja normaalia Javaa. Generoidusta JUnit-testistä poistuvat tietysti rivin aloittavat kommentit, joten jos sellaiselle on tarvetta, on kommentoitava "tuplasti".
Jos Eclipsen ComTest-plugin on asennettu, valmiin testirungon voi tehdä kirjoittamalla kommenttilohkoon comt ja painamalla näppäinyhdistelmää ctrl+välilyönti.
Jotta ComTestit toimisivat, pitää itse testattava luokka olla kirjoitettu johonkin pakettiin. Eli tiedoston alussa pitää olla esimerkiksi
package luvut;ja tällöin itse tiedosto pitää olla oletushakemistoon nähden vastaavassa alihakemistossa (esimerkissä alihakemistossa luvut). Eclipsen IDEä käytettäessä src -hakemiston alle pitää tehdä alihakemisto (eli package) jonne itse luokka kirjoitetaan.
7.10.2 ComTestin edistyneemmät ominaisuudet
Seuraava hieman monimutkaisempi ohjelma käyttää hyväkseen silmukoita ja taulukoita, joten jos ne ovat hyvässä muistissa Ohjelmointi 1 kurssilta, niin seuraava on hyvää luettavaa. Muussa tapauksessa kannattaa palata esimerkkiin myöhemmin.
Ohjelma sisältää algoritmin joka palauttaa indeksin ensimmäisen taulukon lukuun, jolla on eniten esiintymiä jälkimmäisessä taulukossa. Mikäli esiintymiä kahdella luvulla on sama määrä, niin palautetaan se joka esiintyi jonossa ensimmäisenä.
- muuttujat.testaus.Esiintymat.java
/**
* Ohjelma testauksen esittelyä varten
* @author Santtu Viitanen
* @version 1.0, 4.7.2011
*/
public class Esiintymat {
/**
* Palauttaa indeksin t1 taulun arvoon, jolla on eniten esiintymiä t2
* taulussa. Mikäli kahdella luvulla on saman verran esiintymiä palautetaan
* jonossa ensimmäinen arvo. Jos t1 on tyhjä palautetaan -1
*
* @param t1 taulukko, jonka indeksi palautetaan
* @param t2 taulukko, johon verrataan
* @return indeksi t1 taulun arvoon.
*/
public static int enitenEsiintymia(int[] t1, int[] t2) {
int paras = -1; // eniten esiintymiä omaavan luvun indeksi
int parhaanEsiintymat = -1; //esiintymien määrät
for (int i = 0; i < t1.length; i++) {
int ehdokkaanEsiintymat = 0;
for (int j = 0; j < t2.length; j++)
if (t1[i] == t2[j])
ehdokkaanEsiintymat++;
if (ehdokkaanEsiintymat > parhaanEsiintymat) {
paras = i;
parhaanEsiintymat = ehdokkaanEsiintymat;
}
}
return paras;
}
}Testipääohjelman käyttö on muuttunut jo huomattavan työlääksi
ComTestilla funktion testaaminen muuttuu muotoon
Testit sisältävät tyypillisesti paljon toistuvia rakenteita. Tämän vuoksi ComTest mahdollistaa myös taulukkomuotoisen testaamisen. Esimerkkimme oli varsin yksinkertainen, mutta monimutkaisemmissa toteutuksissa testejä voi olla kymmeniä, jolloin taulukkomuotoinen testaus vähentää kirjoittamista ja sillä saa aikaan havainnollisemman dokumentaation.
tai jopa datan suoran esittelyn testitaulukossa:
7.10.3 Reaalilukujen testaaminen
Koska reaalilukujen arvo ei juuri koskaan ole täsmälleen haluttu luku, pitää reaalilukujen testaamisessa muistaa käyttää yhtäsuuruutta "epämääräisempää" testiä. Reaalilukujen vertaamiseen käytetään aaltoviivoja (~~~) tarkoittamaan että tuloksen pitää olla "melkein" haluttu arvo:
Mikäli vertailun tarkkuutta ei anneta, niin se on n. 4 desimaalia.
Muita käytettäviä makroja ovat esimerkiksi
#CLASSIMPORT- Lisää luokkia import lauseeseen#STATICIMPORT- kääntäjä löytää staattisen metodin ilman viittausta luokkaan (oletuksena päällä)
Tarkemmat ohjeet ComTestin asennukseen ja käyttöön löytyvät osoitteesta
7.10.4 StringBuilderin testaaminen
StringBuilder luokan oliota ei voi verrata String-luokan olioon. Edes kahta StringBuilder-luokan olioita ei voi verrata keskenään koska StringBuilder-luokassa ei ole ylikirjoitettua equals-metodia.
7.11 Mittakaavaohjelma graafisena
Tehdään mittakaava-ohjelman graafinen versio käyttäen JavaFX-kehystä. Dokumentissa JavaFX/kaytto on tarkemmin kuvattu JavaFX:n eri yksityiskohtia.
7.11.1 Mittakaava JavaFX:llä
Tämän aliluvun esimerkkikoodit on ladattavissa hakemistosta:
ja sen kääntämiseksi Eclipsessä pitää mukaan ottaa vielä Ali.jar -kirjasto. Esimerkit voidaan ajaa myös TIMissä, kunhan ne tallennetaan ja ajetaan esitetyssä järjestyksessä.
Tehdään sama Matka-ohjelma graafisena versiona. Aloitetaan piirtämällä SceneBuilderillä käyttöliittymä MatkaView.fxml -tiedostoon. Usein graafisissa ohjelmissa on painikkeita, joilla laskenta tehdään, mutta yhtä hyvin tapahtumana voidaan käyttää kenttien muutosta tai sitä että kentässä vapautetaan näppäin. Tämän hyvä puoli on se, että näyttö on silloin aina ajantasalla.

Seuraavassa kuvassa on näytetty miten suunnitelman hierarkia näkyy SceneBuilderissä. Tarkkaan ottaen GridPane voisi suoraan olla pohjakomponenttina. Toisaalta se, että pohjana on BorderPane, mahdollistaa myöhemmin helpommin esimerkiksi menujen lisäämisen.

SceneBuilderillä tehty MatkaView.fxml-tiedosto näyttäisi seuraavalta. TextField johon tulee maastossa oleva matka, voisi olla myös Label, mutta jos tehdään vain luettavissa oleva tekstikenttä, voidaan siitä kopioida tuloksia muihin ohjelmiin.
Kontrolleriluokkaan MatkaController.java on esitelty ne komponentit, joita tarvitaan itse koodissa. Eli lähinnä kaikki TextField-komponentit. Annotaatio @FXML tekee attribuuteille (niistä myöhemmin tarkemmin) sen, että niitä vastaavat oliot luodaan ja alustetaan silloin kun pääohjelma lukee .fxml-tiedostoa. Samoin @FXML -merkityt metodit voidaan liittää tapahtumiksi .fxml -tiedostossa.
Itse koodi on koitettu jakaa kahteen osaan, eli siihen, joka riippuu .fxml tiedostosta ja siitä, joka ei riipu. Laskemisessa tarvittava metodi laske on kirjoitettu sen takia erikseen, että sitä tarvitaan useista eri paikoista. Metodissa laske haetaan käyttäjän mittakaavaan ja kartalla olevaan matkaan kirjoittamat tekstit ja muunnetaan ne vastaaviksi reaaliluvuiksi aliohjelmalla haeLuku. Sitten suoritetaan itse lasku kuten komentorivipohjaisessa ohjelmassa ja tulos sijoitetaan luonnossa olevaa matkaa esittävän tekstikentän sisällöksi.
Mikäli TextField-kentässä painetaan Enter, tulee siitä JavaFX:än onAction tapahtuma ja silloin valitaan vastaavan TextField-komponentin koko sisältö jotta seuraava merkki tyhjentää sisällön. Näin uusien matkojen syöttäminen on nopeaa, koska ei tarvitse itse pyyhkiä sisältöä. Riittää kirjoittaa luku ja painaa Enter ja heti jatkaa uudella luvulla.
Tässä tapauksessa itse pääohjelmasta on jätetty pois .css tiedoston lataaminen. Pääohjelman tehtävä on vain lukea .fxml-tiedosto ja sitten pistää syntynyt käyttöliittymä näkyville.
Seuraavassa vielä sama ohjelma uudelleen niin, että kaikki olioiden luonnit on kirjoitettu suoraan Javalla ja kaikki koodi on yhdessä tiedostossa. Tätä kannattaa verrata normaaliin JavaFX:n neljän tiedoston (tai kolmen jos .css unohdetaan) malliin.
Oikeastaan siis .fxml-tiedoton lukemisen tehtävä on tehdä sama kuin alla tekee metodi luoNaytto. Eli se luo pohjakomponentin ja latoo sen päälle halutulla tavalla muut käyttöliittymäkomponentit ja asettaa niiden tapahtumankäsittelijät. Sen jälkeen vastuu ohjelman toiminnasta jää tapahtumien varaan.
Huomattakoon että koodi MITTAKAAVA -valion esittelystä eteenpäin on molemmissa versioissa täsmälleen sama. Eli suuri osa koodista voidaan kirjoittaa niin, että se on riippumaton käytetyistä käyttöliittymän muodostamistyökaluista.
Vaikka SceneBuilderillä on havainnollista piirtää käyttöliittymää, kannattaa opetella tekemään myös jälkimmäisen mallin mukaan, sillä usein ohjelmissa pitää luoda dynaamisesti uusia käyttöliittymäkomponentteja ohjelman ajon aikana. Ja tämä onnistuu juuri yllä olevan koodin kaltaisella tekniikalla.
7.11.2 Mittakaava Swing-kirjastolla
Tämä aliluku ei ole niin ajankohtainen vuoden 2016 kurssilla.
Seuraavaksi on aika sitoa opittuja asioita yhteen. Nyt osataan jo toteuttaa yksinkertaisia graafisia ohjelmia joilla on toiminnallisuutta. Otetaan pohjaksi tässä luvussa esitelty komentoriviltä toimiva Matka.java ja toteutetaan se graafisena versiona (Swing).
Uuden JFrame-ikkunan voi luoda esimerkiksi Eclipsellä. Graafisessa editorissa kuvaa vastaavan käyttöliittymän saa suurin piirtein seuraavilla toimenpiteillä
- Properties-ikkunasta pääikkunalle layout GridBagLayout
- Label- ja TextField -komponentit oikeisiin paikkoihinsa ja niille kuvaava nimeäminen (Variable). Esimerkissä kentille on käytetty textMittakaava, textKartalta ja textMaastossa.
- Labelien tekstit kuvaa vastaaviksi ja textMittakaava kentälle oletusteksti 200000
- Käyttöliittymä on tarkoitus toimia ilman erillistä Laske-nappia, joten graafisesta näkymästä asetetaan textMittakaava ja textKartalla kentille tapahtumaksi KeyReleased.
Koska kahdella tekstikentällä on sama toiminnallisuus, niin laitetaan molemmista kutsu samaan laske()-metodiin.
muuttujat.graafinen.Mittakaava.java
/**
*
* @author Vesa Lappalainen @version 1.0, 27.1.2011
* @author Santtu Viitanen @version 1.1, 03.08.2011
*/
public class Mittakaava extends JFrame {
public static void main(String[] args) { ... }
/**
* Create the frame.
*/
public Mittakaava() {
addWindowListener(new WindowAdapter() {
...
getTextKartalta().addKeyListener(new KeyAdapter() {
@Override
public void keyReleased(KeyEvent arg0) {
laske();
}
});
textMittakaava.addKeyListener(new KeyAdapter() {
@Override
public void keyReleased(KeyEvent arg0) {
laske();
}
});
//Metodin loppuosa on suurimmaksi osaksi graafisessa
editorissa generoitua koodia
...
}Tarvitsemme ohjelmassa vakiot oletusmittakaavalle, sekä kertoimelle jolla teemme muutokset.
public static final double MITTAKAAVA = 200000.0;
public static final double MM_KM = 1000.0 * 1000.0;Mittakaavamuunnoksia olemme laskeneet jo aiemminkin. Tähän ei liity mitään graafista. Muunnetaan kartalta millimetreinä mitattu matka kilometreiksi maastossa.
public static double mittakaavamuunnos(double matka_mm, double mittakaava) {
return mittakaava*matka_mm / MM_KM;
}Luvun hakemiseen tekstikentästä on myös hyvä olla yleiskäyttöinen metodi. Malliohjelmassa on käytetty Ali.jar-kirjastoa, josta löytyy valmis funktio reaalilukujen parsimiseen.
public static double haeLuku(JTextField text,double oletus) {
double luku = Mjonot.erotaDouble(text.getText(), oletus);
return luku;
}Jäljellä onkin enää tekemiemme aliohjelmien ja graafisen käyttöliittymän komponenttien yhdistäminen toimivaksi kokonaisuudeksi.
public static void laitaTulos(JTextField text, double luku) {
String tulos = String.format("%5.2f",luku);
tulos = tulos.replace(',', '.');
text.setText(tulos);
}
private void laske() {
double mittakaava = haeLuku(textMittakaava,MITTAKAAVA);
double matka_mm = haeLuku(textKartalta, 0);
double matka_km = mittakaavamuunnos(matka_mm,mittakaava);
laitaTulos(textMaastossa,matka_km);
}
}Tehtävä 7.24 Lisää toiminnallisuutta ohjelmaan
Lisää ohjelmaan seuraava toiminnallisuus selectAll()-metodin avulla.
Enter textMittakaava ja textKartalla kentissä valitsee kyseisen kartan tekstit.
Enter textMaastossa kentässä valitsee kaikkien kenttien tekstit.
8. Kohti olio-ohjelmointia
Ohjat ottaako oliot?
Luokista luodut ilmentymät
kantaemosta perityt
rajapinnalla rajatut.
Itsestäänkö ilmaantuvat,
sanomatta siunaantuvat?
Viestejä hyö viskoviksi
kaiken koodin korvaajiksi.
Nyt on virhe pienen pieni
ei valta noin suuren suuri.
Taas työ itse tehtäväksi
oliot olkoonkin avuksi.
Luokat luotava lujiksi
vakaan vastuun kantajiksi
ylläpidon ystäviksi
tehtävien taitajiksi.
Oman homman hoitajaksi
tuodun tiedon taattajaksi
sisältö sen suojaamaksi
paljon piiloon pistäväksi.
Perintääkin pohdittava
katsottava koostamista
muodostajaa muotoiltava
rajapintoja raakattava.
Metodeja mietittävä
attribuutteja aateltava
viestejäkin viskeltävä
olioita ohjaillessa.
Mitä tässä luvussa käsitellään?
- yksinkertaiset luokat
- olioiden perusteet
- olioterminologia
- koostaminen
- perintä
- polymorfismi
Syntaksi:
luokan esittely:
public class Nimi extends Isa implements Rajapinta { // 0-1 x Isa*
// 0-n x Rajapinta , erot
private yksityinen_attribuutti // vain itse näkee, 0-n x
private yksityinen_metodi // 0-n x
protected suojattu_attribuutti // perillinen näkee, 0-n x
protected suojattu_metodi // 0-n x
public julkinen_attribuutti_paha // kaikki näkee 0-n x !HYIHYIHYI!
public julkinen_metodi // 0-n x
package paketin_attribuutti // paketissa näkee, 0-n x
package paketin_metodi // 0-n x, package on oletus
}
attr kuten muuttuja
attrib.esitt. tyyppi attr;
metodin esitt. kuten aliohjelman esittely
viittaus olion metodiin: olio.metodin_nimi(param,param) // 0-n x param
isäluokan metodiin viit: super.metodin_nimi(param,param)
muodostaja Nimi(param_lista) // voi olla monta eri param_listoillaLuvun esimerkkikoodit:
Tähän lukuun on kasattu suuri osa olioihin liittyvää asiaa yhden esimerkin valossa. Esimerkin yksinkertaisuuden takia se ei anna joka tilanteessa täyttä hyötyä esitetyistä ominaisuuksista. Lisäksi asiaa voi olla yhdelle lukukerralle liikaa ja esimerkiksi perintä, rajapinnat ja polymorfismi kannattaa ehkä jättää myöhemmälle lukukerralle.
Luvun Aika-esimerkki on tällaisenaan melkoisen yksinkertainen, mutta pitää muistaa, että oikeasti aikoihin ja päivämääriin liittyvät laskut ovat kaikkea muuta kuin yksinkertaisia kaikkine aikavyöhykkeineen, kesäaikoineen ja vieläpä eri maiden erilaisten kalenterien takia. Esimerkeissä ei siis pyritäkkään täydellisyyteen, vaan pyritään näyttämään olioissa tarvittavia rakenteita.
8.1 Miksi olioita tarvitaan
Emme tässä ryhdy pohtimaan kovin syvällisiä siitä, miten olio-ohjelmointiin on päädytty. Todettakoon kuitenkin että olio-ohjelmointi on hyvin luonnollinen jatke rakenteelliselle ohjelmoinnille heti, kun huomataan siirtää käsiteltävä data ja dataa käsittelevä koodi samaan ohjelman osaan. Tämä toimenpide voidaan tehdä tietenkin myös perinteisillä ohjelmointikielilläkin. Puhtaat oliokielet eivät vaan jätä edes muuta mahdollisuutta. Lähestymme asiaa evoluutiomaisesti - niin kuin kehitys on olioihin johtanut. Loput ylilaulut olioista kannattaa lukea jostakin hyvästä kirjasta.
Aloitetaanpa tutkimalla Aikalisa-esimerkkiämme. Pääohjelmassa esiteltiin muuttuja tunteja varten ja muuttuja minuutteja varten. Aluksi tämä saattaa tuntua hyvin luonnolliselta ja niin se onkin, niin kauan kuin ohjelman koko pysyy pienenä. Entäpä ohjelma jossa tarvitaan paljon kellonaikoja?
- oliot.muut.Aikalis4.java - useita aika "muuttujia"
Hyvinhän tuo vielä toimii? Tosin Javassa ei voitu tehdä aliohjelmaa, joka muuttaisi "kellonaikaa". Kiertotienä voisi tallentaa ajan taulukkoon, sillä taulukko välitetään Javassa viitteenä ja silloin taulukon arvoja voisi muuttaa aliohjelmassa. Mutta tämäkin kiertotie lakkaisi toimimasta, jos alkioiden pitäisi olla keskenään eri tyyppiä. Nykyversiossa on lisäksi ongelmana se, että jos joku tulee ja sanoo, että sekunnitkin mukaan! Tulee paljon työtä, jos on paljon aikoja.
Tehtävä 8.1 Tulostus
Mitä ohjelma Aikalis4.java tulostaa?
8.2 Hynttyyt yhteen, eli muututaan olioksi
Olio-ohjelmoinnin tärkeimpiä ideoita on kasata tiedot (muuttujat) ja niitä käsittelevät koodit yhteiseksi "paketiksi", olioksi, joka osaa tehdä tiedoille tarvittavat käsittelyt. Lisäksi suojataan tiedot niin, ettei niitä pääse kukaan muu muuttamaan kuin itse olio.
Itse asiassa vanhalla C-kielelläkin pystyi kirjoittamaan "olioita", kirjoittamalla tietuetyypin esittelyn ja sitä käyttävät aliohjelmat yhdeksi aliohjelmakirjastoksi. Näin data ja sitä käsittelevät aliohjelmat on kapseloitu yhdeksi paketiksi.
8.2.1 Terminologiaa
Nyt astuvat kuvaan mukaan olio-ohjelmoijat ja he nimittävät sitten näin syntyneitä aliohjelmia metodeiksi (method), tai C++-kirjallisuudessa jäsenfunktioiksi (member function). Olion alkioita, omia muuttujia tai kenttiä nimitetään sitten attribuuteiksi.
"Kokoelma" näitä metodeja ja attribuutteja on luokka ja siitä muodostettu vastaava muuttuja - luokan ilmentymä - on sitten se kuuluisa olio (object).
8.2.2 Ensimmäinen olio-esimerkki
Muutetaanpa Aikalisa kunnon luokaksi ja olioksi:
- oliot.aika.olio.Aika.java - kunnon olioksi
Siinäpä se! Ovatko muutokset edelliseen nähden suuria? Siis iso osa koko olio-ohjelmoinnista (ja tietotekniikasta muutenkin) on markkinahenkilöiden huuhaata ja yleistä hysteriaa "kaiken ratkaisevan" teknologian ympärillä. No, tosin olio-ohjelmoinnissa on puolia, joita emme vielä ole nähneetkään, joiden ansiosta olio-ohjelmointia voidaan pitää uutena ohjelmointia ja ylläpitoa helpottavana teknologiana. Näitä ovat mm. perintä ja polymorfismi (monimuotoisuus), joihin emme valitettavasti tässä vaiheessa ehdi perehtyä kovinkaan syvällisesti.
Takaisin esimerkkiimme. Uutta on lähinnä se, että metodien (no sanotaan tästä lähtien funktioita metodeiksi) parametrilistat ovat lyhentyneet. Itse olion tietoja ei tarvitse enää viedä parametrina, koska metodit ovat luokan sisäisiä ja tällöin luokkaa edustava olio kyllä tuntee itse itsensä.
Metodia kutsutaan ilmoittamalla olion nimi ja metodi, jota kutsutaan
//lisätään aikaan 55min
a1.lisaa(55);
//Merkkijonoon kello tallennettavaksi kutsutaan oliolta sen merkkijonoesitys
String kello = a1.toString();Tällekin on keksitty oma nimi: välitetään oliolle viesti "lisaa" (message passing). Tässä kuitenkin jatkossa voi vielä lipsahtaa ja vahingossa sanomme kuitenkin, että kutsutaan metodia lisaa, vaikka ehkä pitäisi puhua viestin välittämisestä.
Erityisesti pitää huomata että metodien nimien edessä ei nyt ole static-määrettä. Tällöin metodit ovat oliokohtaisia, eli ne voivat käyttää olion this-viitettä ja sitä kautta olion omia attribuutteja.
Suurin hyöty esimerkin toteuttamisesta olio-ohjelmoinnilla on sen tapa, millä se hoitaa tulostuksen.
8.2.3 toString()
Metodilla toString voidaan määritellä miltä olio näyttää merkkijonona. Olion voi tulostaa tietovirtaan, jolloin se kutsuu automaattisesti toString -metodia. Näin luokkaa ei sidota käytettäväksi missään tietyssä ympäristössä.
Huomattavaa on siis, että toString palauttaa vain merkkijonon. On vasta käyttöliittymävaiheen ohjelmointia tietää mitä sillä halutaan tehdä.
...
public String toString() {
return String.format("%02d:%02d",h, m);
}
...Komentoriviohjelma voisi käyttää Aikaa esimerkiksi seuraavasti tulostamalla sen System.out -tietovirtaan.
Aika aika = new Aika(13,37);
System.out.println""("Kello on " + aika);Ohjelma ei myöskään kaadu, vaikka toString() -metodia ei olisikaan erikseen määritelty. Tarkalleen ottaen tällöin tietovirtaan tulostuu olion hajautusarvo heksadesimaalijärjestelmän lukuna esim tyyliin:
aika.Aika@7f31245aKerrataanpa vielä termit edellisen esimerkin avulla:
Älä hämäänny termeistä!
| oliotermi | perinteinen termi | |
|---|---|---|
| Aika | aika-luokka | tietuetyyppi |
| h,m | aika-luokan attribuutteja | tietueen alkio |
| lisaa,tulosta | aika-luokan metodeja | funktio, aliohjelma. |
| a1,a2,a3 | olioviitteitä, jotka ovat aika-luokan ilmentymiä | muuttuja |
| a1.lisaa(55) | viesti olioille a1: lisää 55 minuuttia | aliohjelman kutsu |
8.2.4 Luokka (class) ja olio (object)
Luokka on tavallaan "piparkakkumuotti" kaikille samankaltaisille "olioille". Luokalla ei sinänsä tee mitään (jos siinä ei ole static-aliohjelmia), ellei siitä luo luokkaa edustavaa oliota.
Aika a1 = new Aika(12,15);Javan "olio-muuttujathan" eivät olleet mitään muuta kuin pelkkiä viitteitä keossa sijaitseviin varsinaisiin olioihin. new -operaattori luo kekoon uuden olion, "kutsuu" sen muodostajaa ja palauttaa sitten viitteen tähän olioon.
Pelkkä olion luominen ilman viitteen sijoittamista mihinkään on useimmiten hyödytöntä
new Aika(12,15); // Tähän olioon ei päästä käsiksi YHYYY!Kerran luodun olion viite voidaan luonnollisesti sijoittaa toiseen viitteeseen:
a2 = a1; // molemmat viitteet viittaavat samaan olioon.*Kun olioon ei ole enää yhtään viitettä, muuttuu olio Javassa roskaksi ja muistinsiivous (roskienkeruu, garbage collection, gc) vapauttaa ajallaan olion viemän muistitilan.
Aika a1 = new Aika(12,15);
...
a1 = null; // a1 ei viittaa enää olioon => olio muuttuu roskaksitai
{ // lohkon alku, jonka sisällä viite esitelty
Aika a1 = new Aika(12,15);
...
} // Viite a1 lakkaa olemasta => olio muuttuu roskaksi8.2.5 Suojaustasot ja kapselointi
Luokan attribuuteille ja metodeille on suojaustasot, jotka oletuksena ovat pakettikohtaisia, eli metodeja voi kutsua kuka tahansa samaan pakettiin kirjoitetun luokan metodi. Erityisesti kuka tahansa samassa paketissa oleva metodi voi muuttaa attribuuttien arvoja ilman että olio tätä itse huomaa.
Kuka voi käyttää metodia/attribuuttia:
| Suojaus | kaikki | aliluokan metodit | paketin metodit | luokan metodit |
|---|---|---|---|---|
| private | x | |||
| package | x | x | ||
| protected | x | x | x | |
| public | x | x | x | x |
Kirjoitamme testiluokan havainnollistamaan tätä toiminnallisuutta:
- oliot.aika.olio.Aikatesti.java - testiluokka Aika-luokalle (aja ensin Aika-luokan testi))
Jos esimerkkimme metodi lisaa esiteltäisiin:
private void lisaa(int lisa_min) {niin testiohjelma lakkaisi toimimasta, koska esimerkiksi pääohjelman kutsu
a1.lisaa(55)tulisi laittomaksi luokan jäsenen lisaa ollessa yksityinen (private).
Erityisen tärkeää on kuitenkin että ei voida kirjoittaa testiohjelmassa
a1.h = 28; // private-attribuuttiin ei saa viitata*Käytännössä attribuutit kannattaa lähes poikkeuksetta kirjoittaa yksityisiksi. Kaikista pahinta mitä olio-ohjelmoija voi tehdä, on kirjoittaa julkisia attribuutteja. Jos attribuutit eivät ole suojattuja, voi mikä tahansa ohjelmanosa muuttaa niitä ja menetetään kontrolli niiden tilasta, eli arvosta. Esimerkiksi meidän aikaluokan tapauksessa voisi joku luokkaa käyttävä sijoittaa sekunteihin 1000 ilman, että olio voisi itse varmistaa kaiken olevan kunnossa.
Nyt vasta alkavatkin olio-ohjelmoinnin hienoudet! Aloittelijasta saattaa tuntua, että mitä turhaan tehdään asiasta monimutkaisempaa kuin se onkaan! Väärinkäytetyt ja virheelliset arvot muuttujilla ovat olleet ohjelmoinnin kiusa alusta alkaen. Nyt meillä on mahdollisuus päästä niistä eroon kapseloinnin (jotkut sanovat kotelointi, encapsulation) ansiosta. Kaikki arvojen muutokset (eli olio-tapauksessa olion tilojen muutokset) voidaan suorittaa kontrolloidusti, vain olion itse siihen suostuessa. Mutta miten sitten alustuksen tapauksessa?
8.2.6 Muodostajat (constructor)
Javan (kuten myös C# ja C++) olioilla on yksi erityinen metodi: muodostaja (konstruktori, rakentaja, constructor), jota kutsutaan olion syntyessä. Muodostajan tehtävä on alustaa olion tila ja luoda mahdollisesti tarvittavat dynaamiset muistialueet. Näin voidaan järjestää se, että olion tila on aina tunnettu olion syntyessä.
Joissakin oliokielissä konstruktori ilmoitetaan omalla avainsanallaan. Javassa muodostaja on metodi, jolla on sama nimi kuin luokalla. Muodostajia voi olla useitakin kunhan niillä on keskenään erilainen parametrilista (function overloading). Muodostaja on aina tyypitön, siis ei edes void-tyyppiä.
public Aika(int h,int m) { // Muodostaja
this.h = h;
this.m = m;
}Esimerkissämme muodostaja on esitelty 2-parametriseksi ja sitä "kutsutaan" olion luonnin yhteydessä:
Aika a1 = new Aika(12,15);8.2.7 Oletusmuodostaja (default constructor)
Nyt ei kuitenkaan voida esitellä oliota ilman alkuarvoa
Aika aika = new Aika();Kääntäjä antaisi esimerkiksi virheilmoituksen:
"Aikatesti.java": Error #: 300 : constructor Aika() not found in
class Aika at line 16, column 21Parametritonta muodostajaa sanotaan oletusmuodostajaksi (default constructor). Sellainen on luokalla aina ilman muuta, jos luokalle ei ole esitelty yhtään muodostajaa. Jos luokalle esitellään jokin muu muodostaja, ei oletusmuodostaja enää tulekaan automaattisesti.
Meidän pitäisi päättää nyt paljonko kellomme on, jos sitä ei erikseen ilmoiteta. Olkoon kello vaikka 00:00, eli keskiyö. Esittelemme oletusmuodostajan
// oliot.aika.muodostaja.Aika.java - lisätään oletusmuodostaja
/** … */
public class Aika {
private int h=0, m=0;
/**
* Alustaa ajan muotoon 00:00
* @example
* <pre name="test">
* new Aika().toString() === "00:00";
* </pre>
*/
public Aika() { // Oletusmuodostaja
h = 0; m = 0;
}
/** … */
public Aika(int h,int m) { // Muodostaja
this.h = h;
this.m = m;
}
/** … */
public String toString() {
return String.format("%02d:%02d",h, m);
}
/** … */
public void lisaa(int lisaMin) {
int yht_min = h * 60 + m + lisaMin;
h = yht_min / 60;
m = yht_min % 60;
}
}Tässä tapauksessa oletusmuodostajaksi olisi kelvannut myös tyhjä lohko. Miksi?
public Aika() { }8.2.8 Sisäinen tilan valvonta
Emme edelleenkään ole ottaneet kantaa siihen, mitä tapahtuu, jos joku yrittää alustaa oliomme mielettömillä arvoilla, esimerkiksi:
Aika a1 = new Aika(42,175);Toisaalta, miten joku voisi muuttaa ajan arvoa muuten kuin lisaa-metodilla? Teemmekin aluksi metodin aseta, jota kutsuttaisiin
a1.aseta(12,15); a2.aseta(16,23);Koska aseta-metodi hoitaa sisäisen tilan valvonnan, sitä kannattaa hyödyntää myös muodostajissa. Näin olion tilaa muutetaan vain muutamassa metodissa, jotka voidaan ohjelmoida niin huolella, ettei mitään yllätyksiä pääse koskaan tapahtumaan.
public Aika() { aseta(0, 0);}
public Aika(int h) { aseta(h, 0);}
public Aika(int h, int m) { aseta(h, m); }Nyt pitää kuitenkin päättää mitä tarkoittaa laiton asetus! Mikäli barbaarimaisesti sovimme, että minuuteissa yli 59 arvot ovat aina 59 ja alle 0:n arvot ovat aina 0, voisi aseta-metodi olla kirjoitettu seuraavasti:
public final void aseta(int ih,int im) {
h = ih; m = im;
if ( m > 59 ) m = 59;
if ( m < 0 ) m = 0;
}Elegantimpi ratkaisu ongelmaan on siirtää ylimääräiset minuutit tunteihin ja ylimääräiset tunnit vuorokausiin. Vielä emme kuitenkaan ole selvillä vesillä, koska kokonaislukumuuttujiin voi tietysti syöttää myös negatiivisia lukuja. Ratkaisuna otamme puuttuvat minuutit tunneista ja tunnit vuorokausista.
/**
* Asettaa uuden ajan ja pitää huolen että aika on aina oikeaa muotoa.
* @param ih asetettava tuntimäärä
* @param im asetettava minuuttimäärä
* @return montako vuorokautta jäi yli
* <pre name="test">
* Aika a1 = new Aika();
* a1.aseta(12,15); a1.toString() === "12:15";
* a1.aseta(15,45); a1.toString() === "15:45";
* a1.aseta(-49,-125); a1.toString() === "20:55";
* </pre>
*/
public final int aseta(int ih, int im) {
int th = ih;
int tm = im;
th += tm / 60; // liiat minuutit tunteihin
tm %= 60; // minuutit väille -59 - 59
int vrk = th / 24; // liiat tunnit vuorokausiin
th %= 24; // tunnit välille 0-23
if (tm<0) { tm += 60; th--; } //negatiiviset arvot
if (th<0) { th += 24; vrk--; }
this.h = th; // asetetaan lasketut arvot attribuutteihin
this.m = tm;
return vrk; // motako vuorokautta jäi yli
}Algoritmi on jo huomattavan monimutkainen, joten kirjoittamalla kattavat testit etukäteen säästyy paljolta vaivalta.
/**
* Sisäinen tilanvalvonta Aikaan.
* @author Vesa Lappalainen @version 1.0, 01.02.2003
* @author Santtu Viitanen @version 1.1, 7.7.2011
* @example
* <pre name="test">
* Aika a1 = new Aika(12,15);
* a1.lisaa(55); a1.toString() === "13:10";
* a1.aseta(12,15); a1.toString() === "12:15";
* </pre>
*/
public class Aika {
private int h = 0, m = 0;
public Aika() { // Oletusmuodostaja aseta(0, 0); }
public Aika(int h) { aseta(h, 0); }
public Aika(int h, int m) { // Muodostaja
aseta(h, m);
}
public final int aseta(int ih, int im) { ... }
public void lisaa(int lisaMin) {
aseta(h, m + lisaMin);
}
public String toString() { … }
}Tarkkaavainen lukija luultavammin ihmettelee tässä vaiheessa final- määrettä aseta-metodin edellä. Koodi kääntyy myös ilman, mutta sen käyttö on suositeltavaa kutsuttaessa metodia suoraan muodostajalta. Tässä vaiheessa syytä on työlästä selittää, mutta siihen palataan perintää koskevassa luvussa.
Tehtävä 8.2 Negatiivinen minuuttiasetus
Mitä ohjelma Aika.java tulostaisi? Miksi ohjelma toimisi halutulla tavalla?
Tehtävä 8.3 Päivämääräluokka
Mieti miten päivämäärää kuvaava luokka kuuluisi toteuttaa ja mitä tulisi ottaa huomioon.
Tehtävä 8.4 Päivämääräluokan toteutus
Esittele luokka, jolla kuvataan päivämäärä. Kirjoita ainakin sopiva muodostaja ja metodi toString, joka palauttaa päivämäärän merkkijonona.
8.2.9 Metodien kuormittaminen (lisämäärittely, overloading)
Edellisessä esimerkissä oli kolme samannimistä metodia Aika. Kussakin oli eri määrä parametreja. Tätä sanotaan metodin kuormittamiseksi, eli mahdollisuudeksi määritellä lisää merkityksiä (eli kuormaa, eng. overloading) metodin nimelle. Varsinainen kutsuttava metodi tunnistetaan nimen ja parametrilistassa olevien lausekkeiden avulla. Metodin nimi koostuukin tavallaan nimen ja parametrilistan yhdisteestä. Siten esimerkiksi
String m = "kissa";
String s;
s = m.substring(1); // s === "issa"
s = m.substring(1,3); // s === "is"kumpikin substring-kutsu kutsuu eri metodia. Metodien kuormitus onkin varsin mukava lisä ohjelmointiin. Se ei kuitenkaan ole varsinaisia olio-ohjelmoinnin piirteitä.
Kuormitetussa metodissa ero on oltava parametreissa, pelkkä ero metodin paluuarvossa ei riitä erottelemaan mitä metodia tarkoitetaan. Huomattakoon, että kuormitus ei ole riippuvainen pelkästään parametrien määrästä, vaan myös tyypillä on merkitystä.
Tehtävä 8.5 Mitäs me tehtiin kun ei ollut kuormitusta?
Miten asiat on hoidettava C-kielessä, kun siellä funktioiden nimien kuormitus ei ole mahdollista, vaan kunkin funktion nimen tulee olla yksikäsitteinen.
Tehtävä 8.6 Lisäys yhdellä
Tee vielä uusi lisaa metodi, jota voidaan kutsua a1.lisaa(); jolloin metodi lisää aikaa yhdellä minuutilla.
Tehtävä 8.7 Vain tuntien asettaminen
Kirjoita vielä yksi aseta-metodi, jolla voidaan asettaa pelkät tunnit.
8.2.10 this-viite
Jos verrataan aliohjelmaa (staattista metodia)
// oliot.aika.metodi.Aika.java - aliohjelma vastaan metodi
/**
* Asettaa uuden ajan ja pitää huolen että aika on aina oikeaa muotoa.
* @param aika olio johon lisätään aikaa
* @param ih asetettava tuntimäärä
* @param im asetettava minuuttimäärä
* @return montako vuorokautta jäi yli
* <pre name="test">
* Aika a1 = new Aika();
* aseta(a1, 12,15); a1.toString() === "12:15";
* aseta(a1, 15,45); a1.toString() === "15:45";
* aseta(a1, -49,-125); a1.toString() === "20:55";
* </pre>
*/
public static int aseta(Aika aika, int ih, int im) {
int th = ih;
int tm = im;
th += tm / 60; // liiat minuutit tunteihin
tm %= 60; // minuutit väille 0-59
int vrk = th / 24; // liiat tunnit vuorokausiin
th %= 24; // tunnit välille 0-23
if (tm < 0) { tm += 60; th--; } // negatiiviset arvot
if (th < 0) { th += 24; vrk--; }
aika.h = th; // asetetaan lasketut arvot attribuutteeihin
aika.m = tm;
return vrk; // motako vuorokautta jäi yli
}ja metodia
/**
* …
* <pre name="test">
* Aika a1 = new Aika();
* a1.aseta(12,15); a1.toString() === "12:15";
* a1.aseta(15,45); a1.toString() === "15:45";
* a1.aseta(-49,-125); a1.toString() === "20:55";
* </pre>
*/
public final int aseta(int ih, int im) {
int th = ih;
int tm = im;
th += tm / 60; // liiat minuutit tunteihin
tm %= 60; // minuutit väille -59 - 59
int vrk = th / 24; // liiat tunnit vuorokausiin
th %= 24; // tunnit välille 0-23
if (tm<0) { tm += 60; th--; } //negatiiviset arvot
if (th<0) { th += 24; vrk--; }
this.h = th; // asetetaan lasketut arvot attribuutteihin
this.m = tm;
return vrk; // motako vuorokautta jäi yli
}
...niin helposti näyttää, että ensin mainitussa funktiossa on enemmän parametreja. Tosiasiassa kummassakin niitä on täsmälleen sama määrä. Nimittäin jokaisen ei-staattisen metodin ensimmäisenä näkymättömänä parametrina tulee aina itse luokan osoite, this. Voitaisiinkin kuvitella, että metodi on toteutettu:
"public final int aseta(Aika this, int ih, int im) {" // Näin EI SAA KIRJOITTAA!!!
{
...
"a1.aseta(a1,13,37)";Oikeasti this -viitettä ei saa esitellä, vaan se on ilman muuta mukana parametreissa sekä esittelyssä että kutsussa. Mutta voimme todellakin kirjoittaa:
public final int aseta(int ih, int im) {
{
…
this.h = th; // asetetaan lasketut arvot attribuutteihin
this.m = tm;
}Jonkun mielestä voi jopa olla selvempää käyttää aina this-viitettä luokan attribuutteihin viitattaessa, näinhän korostuu, että käsitellään nimenomaan tämän luokan attribuuttia h, eikä mitään muuta muuttujaa h. Joskus this-osoitinta tarvitaan välttämättä palautettaessa oliotyyppisellä metodilla olion koko tila (esim. viite olioon). Lisäksi joissakin kielissä this-osoittimen vastinetta (usein self) on aina käytettävä.
Usein this-osoitinta käytetään, jos ei haluta antaa metodin parametrilistan muuttujille eri nimiä kuin vastaavilla attribuuteilla. Jos näin olisi haluttu tehdä edellisessä esimerkissä, olisi voitu kirjoittaa
public final int aseta(int hours, int minutes) {
{
…
h = hours; // asetetaan lasketut arvot attribuutteihin
m = minutes;
}Yksi suositus on, että vain muodostajien esittelyissä käytetään samoja muuttujien nimiä kuin attribuuteilla.
On kuitenkin muistettava että AINA kun käytetään attribuuttia, viitataan siihen oikeasti this-viitteen kautta. Eli metodin joka käyttää attribuutteja tulee olla ei-static.
8.2.11 static vaiko ei static
Muita static-sanan käyttöön liittyviä lukuja:
Usein joutuu miettimään onko metodi (tai aliohjelma) staattinen vaiko ei. Tällöin voi yrittää seuraavaa:
- tarvitaanko metodissa olion attribuutteja (eli käytännössä tarvitaanko
this-viitettä)?- tarvitaan => ei-static
- ei tarvita => static (ehkä, ks seuraava)
- onko luokkaa tarkoitus periä ja metodia (joka ei tarvitse attribuutteja) mahdollisesti ylikirjoittaa (override) perityissä luokissa?
- ei => static
- en ymmärrä mistä on kyse => static
- ehkä => ei static
Edellä olevista "säännöistä" seuraa ilman muuta se, että main-aliohjelman on oltava staattinen, koska kun ohjelma käynistetään, ei ole vielä yhtään olioita käytettävissä.
Muita tyypillisiä staattisia aliohjelmia on kaikki perinteiset funktiot, joille viedään parametreina arvoja ja funktio palauttaa vain näiden perusteella tulosarvon, eli ei tarvitse mitään muuta muuttavaa tietoa parametrien lisäksi.
Attribuutit ovat lähes poikkeuksetta ei-static. Joskus harvoin voi olla sellainen tilanne, joissa samaa attribuutin arvoa tarvitaan kaikissa luokasta muodostetuissa olioissa. Malliharjoitustyössä tällainen on juoksevaa numeroa ylläpitävä laskuri:
public class Jasen {
private int tunnusNro;
private String nimi = "";
...
private static int seuraavaNro = 1;
...
}
Tällöin seuraavaNro on yhteinen kaikille Jasen-luokan olioille ja mikäli yksi muuttaa sitä, kaikilla on näkyvissä sama muuttunut arvo.
8.2.12 Sisäkkäiset luokat
Luokkia voi kirjoittaa myös sisäkkäin, eli luokan sisään voi esitellä toisen luokan. Mikäli sisäluokan esittelee staattiseksi, silloin sisäluokan olio ei voi käyttää ulkoluokan olion attribuutteja eikä metodeja (mutta voi käyttää ulkoluokan staattisia metodeja). Toisalta tällöin voi muodostaa sisäluokan olion ilman että ulkoluokan olioita on olemassa.
public class KouluLuokka {
public static class Oppilas {
private final String nimi; // Oppilas-luokan attribuutti
private final double keskiarvo;
...
}
private final String luokka; // KouluLuokka-luokan attribuutteja, joihin
private int oppilaita; // oppilas ei pääse käsiksi
...
}
Nyt kuka tahansa voi luoda koululuokan oppilaan tyyliin:
KouluLuokka.Oppilas kalle = new KouluLuokka.Oppilas("Kalle", 7.2);Edellä attribuutin edessä oleva final tarkoittaa sitä, että attribuutti voi saada arvon vain kerran (muodostajassa).
Mikäli KouluLuokka-luokasta tehdyssä oliossa olisi attribuutteja, ei kalle pääsisi niihin käsiksi.
Edellinen koodi olisi voitu kirjoittaa niinkin, että KouluLuokka olisi kirjoitettu omaan Java-tiedostoon ja Oppilas omaan Java-tiedostoon. Saatu hyöty on siis lähinnä vain se, että molemmat luokat on saatu "pakattua" samaan tiedostoon.
Vastaavasti ei-staattisen sisäluokan olio voi käyttää ulkoluokan olion attribuutteja ja metodeja mutta sisäluokan olion voi muodostaa vain ulkoluokan olio.
Edellisessä esimerkissä on huonoa se, että sisäluokan (Oppilas) olio voi myös muuttaa esimerkiksi oppilaita attribuutin arvoa. Tämän ongelman voisi poistaa vain niin, että tekisi sisäluokasta oman erillisen luokan ja veisi sen muodostajalle tiedon "ulkoluokasta". Tosin koska luokka on final sitä ei kukaan voi muuttaa muodostajan jälkeen. Aina final ei kuitenkaan ole vaihtoehto. Esimerkiksi jos haluttaisiin vaihtaa luokkaa, niin luokan nimi voisi muuttua. Tosin silloin ehkä parempi olisi jos olisi kaksi eri KouluLuokka-oliota, joiden välillä siirrettäisiin oppilaita. Edellisessä esimerkissä tämä ei onistuisi, sillä oppilaan ulkoluokan viitettä ei voi vaihtaa ja tämäkin siis puoltaisi erillisten luokkien tekemistä.
Auttavasti attribuutin muuttamisongelmaa saa korjattua niin, että tekee ulkoluokkaan KouluLuokka julkiset (public) tai suojatut (protected) metodit getOppilaita ja getLuokka ja sitten oppilas käyttää vain näitä. Tällöin voidaan poistaa varoituksen esto "synthetic-access" (ks. Näytä koko koodi) ja tällöin mm. Eclipse varoittaisi jos yritetään käyttää attribuutteja suoraan.
Tehtävä 8.3 Ei käytetä attribuutteja
Tee edellä mainitut muutokset luokkiin KouluLuokka ja Oppilas.
8.3 Perintä
8.3.1 Luokan ominaisuuksien laajentaminen
Pidimme jo aikaisemmin toiveena sitä, että voisimme laajentaa luokkaamme käsittelemään myös sekunteja. Miksi emme tehneet tätä heti? No tietysti olisi heti pitänyt älytä laittaa mukaan myös sekunnit, mutta tosielämässäkin käy usein näin, eli hyvästäkin suunnittelusta huolimatta toteutuksen loppuvaiheessa tulee vastaan tilanteita, joissa alkuperäiset luokat todetaan riittämättömiksi.
Tämän laajennuksen tekemiseen on olio-ohjelmoinnissa kolme mahdollisuutta: Joko muuttaa alkuperäistä luokkaa, periä alkuperäisestä luokasta laajempi versio tai tehdä uusi luokka, jossa on alkuperäinen luokka yhtenä attribuuttina.
8.3.2 Alkuperäisen luokan muuttaminen
Läheskään aina ei voi täysin välttää sitä, että alkuperäistä luokkaa joutuisi muuttamaan. Jos näin joudutaan tekemään, pitäisi tämä pystyä tekemään siten, että jo kirjoitettu luokkaa käyttävä koodi säilyisi täysin muuttumattomana (tai ainakin voitaisiin päivittää minimaalisilla muutoksilla), ja vasta uudessa koodissa käytettäisiin hyväksi luokan uusia ominaisuuksia.
Jos luokka on saatu joltakin kolmannelta osapuolelta, ei luokan päivittäminen edes ole aina mahdollista, vaan silloin täytyy turvautua muihin (parempiin) tapoihin.
Tehtävä 8.8 Luokan muuttaminen
Muuta ohjelmaa Aika.java siten, että ajassa on mukana myös sekunnit. Kuitenkin niin, että alkuperäinen testiohjelma säilyy sellaisenaan toimivana. Voit lisätä testiohjelmaan uusia rivejä sekuntien testaamiseksi.
Tehtävä 8.9 Sekuntien tulostus aina tai oletuksena
Muuta edellistä ohjelmaa siten, että sekunnit tulostetaan aina.
Muuta edellistä ohjelmaa siten, että sekunnit tulostetaan oletuksena jos ne ovat != 0.
8.3.3 Saantimetodit
Tulee tietysti tilanteita, joissa luokan ulkopuolinen haluaa päästä käsiksi sisäisiin tietoihin, kuten esimerkkiluokkiemme aikoihin. Onneksi tähän asti esimerkkiluokkien rakenne on tehty sen verran älykkäästi, ettei alemman tason komponentteihin ole sotkettu käyttöliittymän toimintoja.
Aika olisi mahdollista saada selville parsimalla toString -metodin palauttamsta jonosta halutut palat, mutta tämä on tietysti hyvin epäkäytännöllistä ja aiheuttaa ylimääräistä työtä. Oikea tapa on kirjoittaa saantimetodi kullekin attribuutille, joka perustellusti voidaan katsoa tarpeelliseksi julkaista jollekin ulkopuoliselle.
Esimerkeistä koostaminen ja perintä tulevat käyttämään paketista oliot.aika.metodi löytyvää Aika-luokkaa. Molempien tapojen kannalta on käytännöllistä, mikäli ne pystyvät lukemaan alkuperäisen luokan attribuutteja. Lisätään siis alkuperäiseen luokkaan seuraavat minuutit tai tunnit palauttavat metodit.
…
public int getH() { return h; }
public int getM() { return m; }
…Nyt voitaisiin esimerkiksi kutsua:
System.out.println("Tunnit = " + a1.getH());Näkyvyysmääreet public tai protected antaisivat toki perivälle luokalle oikeuden muuttaa attribuutteja. Mitä etuja saavutetaan siis saantimetodeilla attribuuttien julkaisemiseen verrattuna? Se että attribuutit ovat nyt tietyssä mielessä vain luettavissa (read-only), eli niitä voi lukea saantimetodien avulla, mutta niitä voi asettaa vain aseta-metodin avulla, joka taas pystyy suorittamaan oikeellisuustarkistukset, ja näin olion tila ei koskaan pääse muuttumaan olion itsensä siitä tietämättä.
8.3.4 Koostaminen
Seuraava mahdollisuus olisi uuden luokan koostaminen (aggregation) vanhasta aikaluokasta ja sekunneista. Tämä mahdollisuus meillä on aina käytössä, vaikkei alkuperäistä lähdekoodia olisikaan käytössä. Tätä vaihtoehtoa kannattaa aina vakavasti harkita.
Koostaminen tarkoittaa että luokka koostetaan attribuuteistaan. Toinen vaihtoehto on periminen, jolloin luokka perii isäluokkansa ja saa sitä kautta attribuuttinsa (joihin sillä ei yleensä private-määreen takia ole pääsyä ilman saantimetodeja). Siis jo ihan ensimmäinen Aika-esimerkkimme on koostettu luokka, koska se koostuu attribuuteista h ja m. Käytännässö usein luokka sekä perii isäluokkansa, että lisää siihen omia attribuuttejaan. Eli usein käytännön luokat ovat sekä koostettuja että perittyjä.
Nyt voimme kirjoittaa uuden luokan, joka koostetaan luokasta Aika (testaa tämä ensin)
ja sekunneista (ja sitten tämä)):
- oliot.aika.koostaminen.AikaSek.java - laajentaminen koostamalla
Luokassa on niin vähän ominaisuuksia, että uudessa luokassamme olemme joutuneet itse asiassa tekemään kaiken uudelleen ja on kyseenalaista, olemmeko hyötyneet vanhasta luokasta lainkaan. Tämä on onneksi lyhyen esimerkkimme vika, todellisilla luokilla säästö kokonaan uudestaan kirjoitettuun verrattuna olisi moninkertainen.
8.3.5 Perintä, inheritance
Viimeisenä vaihtoehtona tarkastelemme perintää (inheritance). Valinta koostamisen ja perinnän välillä on vaikea. Aina edes olioasiantuntijat eivät osaa sanoa yleispätevästi kumpi on parempi. Nyrkkisääntönä voisi pitää seuraavaa is-a -sääntöä:
Jos voi sanoa että LuokkaA on LuokkaB (is-a), niin peritään. Tällöin voi puhua isä- ja lapsiluokasta. Esimerkiksi Kissa on Elain.
Jos sanotaan että luokassa A on (has-a) toinen luokka B, niin koostetaan. Nyt puhutaan kooste- ja osaluokasta.
Esimerkiksi ei voi sanoa että "auto on moottori", vaan "autossa on moottori". Tällöin autoa ei siis peritä moottorista, vaan auto koostetaan osista, joista yksi osa on moottori.
Kokeillaanpa ajan kanssa: "luokka jossa on aika sekunteina" on "aika-luokka". Kuulostaa hyvältä. Siis perimään:
- oliot.aika.perinta.AikaSek.java - laajentaminen perimällä
Tässä tapauksessa kirjoittamisen vaiva oli melkein sama kuin koostamisessakin. Niitä aseta, lisaa ja toString -metodeja, jotka löytyivät jo kantaluokasta Aika, ei tarvinnut kirjoittaa. Itse asiassa myös Aika on perinyt toString metodinsa Object luokasta, joka on kaikkien Javan luokkien kantaluokka. Object-luokka sisältää jo valmiina muutamia olio-ohjelmoinnin kannalta tärkeitä yleiskäyttöisiä metodeja.
Muodostajasta pitää kirjoittaa kaikki eri versiot, sillä muodostaja ei valitettavasti periydy Javassa.
Joissakin tapauksissa perimällä pääsee todella vähällä. Otamme tästä myöhemmin esimerkkejä, kunhan pääsemme eroon syntaksin esittelystä.
Lapsiluokka, aliluokka (child class, subclass) on se joka perii (Javassa extends) ja isäluokka, yliluokka (parent class, super) se joka peritään. Käytetään myös nimitystä välitön ali/yliluokka, kun on kyseessä perintä suoraan luokalta toiselle, kuten meidän esimerkissämme.
Javassa välitön yliluokka ilmoitetaan aliluokan esittelyssä:
public class AikaSek extends Aika {8.3.6 super
Jos täytyy viitata yliluokan metodeihin, joille on kirjoitettu aliluokassa oma määrittely, käytetään yliluokan viitettä super
super.lisaa(lisaMin+s/60);Yliluokan viitettä ei tarvita, mikäli samannimistä metodia ei ole aliluokassa.
Mikäli muodostajassa tarvitsee kutsua yliluokan (isäluokan) muodostajaa, tehdään tämä kutsulla super(parametrit). Esimerkissä olisi siis voinut olla:
public AikaSek(int h, int m) {
super(h,m); // kutsuu yliluokan muodostajaa
this.s = 0; // sijoitusta ei edes tarvittaisi koska alustuu nollaksi
} Kutsun super(parametrit) tulee olla muodostajan ensimmäinen lause.
Perintää on helppo kuvata UML-luokkakaavioilla. Nuolen suuntaa käytetään tarkoittamaan että peritään jostakin.
8.3.7 Polymorfismi, eli monimuotoisuus
Edellisestä esimerkistä ei oikeastaan paljastunut vielä mitään, mikä olisi puoltanut perintää. Korkeintaan snobbailu uudella syntaksilla. Mutta tosiasiassa pääsemme tästä kiinni kätevään ominaisuuteen nimeltä polymorfismi (polymorphism) eli monimuotoisuus.
Lisätäänpä vielä ComTest luokan alkutestin loppuun:
* AikaSek a1 = new AikaSek(14,55,45);
* ...
* // ESIMERKKI POLYMORFISMISTA
* #import oliot.aika.metodi.Aika;
* Aika aika = new Aika(11,12); aika.toString() === "11:12";
* aika = a1; aika.toString() === "14:59:15";
* aika.lisaa(20); aika.toString() === "15:19:15";Mistä tässä oli kyse? Viite aika on monimuotoinen, eli sama osoitin voi osoittaa useaan erityyppiseen luokkaan. Tämä on mahdollista, jos luokat ovat samasta perimähierarkiasta kuten tässä tapauksessa, ja viite on tyypiltään näiden yhteisen kantaluokan olion viite.
8.3.8 Myöhäinen sidonta
Miksi edellä jälkimmäisessä aika.toString() kutsussa kutsuttiin luokan AikaSek tulosta metodia eikä Aika -luokan metodia toString?
Edellä mainittu on toteutettu siten, että alkuperäisessä luokassa kerrotaan, että vasta ohjelman suoritusaikana selvitetään mistä luokasta todella on kyse, kun metodia kutsutaan. Tällaista ominaisuutta sanotaan myöhäiseksi sidonnaksi (late binding). Vastakohtana tälle on esimerkiksi C++:n oletustapa kutsua metodeja, eli aikainen sidonta (early binding). Sidonnan sisäisen mekanismin opettelun jätämme jollekin toiselle kurssille (ks. vaikkapa Olio-ohjelmointi ja C++/VL ja sieltä luku Virtuaaliset metodit).
Javassa kutsutapana on onneksi aina myöhäinen sidonta, koska muuten perinnässä ei ole oikein mieltä.
Aliluokkaan voidaan kirjoittaa uusi versio yliluokan vastaavasta metodista. Tästä käytetään termiä uudelleenmäärittäminen (korvaaminen, syrjäyttäminen, overriding). Usein korvatussa metodissa kutsutaan myös yliluokan alkuperäistä metodia.
Tehtävä 8.10 Miksi vielä yksi lisaa-kutsu?
Osaatko selittää miksi aseta-metodissa pitää olla kutsut this.s = s; super.aseta(h,m); lisaa(0,0);? Jos osaat, olet jo melkein valmis Java-ohjelmoija!
Tehtävä 8.11 Ei turhaa lisaa-kutsua
Mitä tarvitsee muuttaa jotta viimeinen lisaa-kutsu saadaan pois?
8.4 Kapselointi
Termi kapselointi liittyy kiinteästi olio-ohjelmointiin. Sen voi ymmärtää toteutuksena joka kokoaa tietoa ja sitä käsitteleviä toimintoja yhdeksi kokonaisuudeksi olioon. Muodostunutta kokonaisuutta voidaan hallita helpommin. Kapseloidut ominaisuudet voidaan myös piilottaa, jolloin niihin ei pääse käsiksi ulkopuolelta. Yleensä attribuutit (tieto) ovat piilotettuja (private). Tätä kutsutaan tiedon piilottamiseksi. Nyt sisäistä tiedon rakennetta voidaan myös parantaa muuttamatta ohjelman ulospäin näkyvää toimintaa.
Tehtävä 8.12 Saantimetodi sekunneille
Täydennä AikaSek.java:hen em. saantimetodit ja lisäksi getS() aliluokkaan AikaSek.
Tehtävä 8.13 Saantimetodien käyttäminen
Muuta vielä edellisessä tehtävässä jokainen mahdollinen viittaus luokan sisälläkin saantimetodeja käyttäväksi suoran attribuuttiviittauksen sijasta.
8.4.1 Rajapinta ja sisäinen esitys
Kapseloinnin ansiosta luokan käyttämiseksi on tullut selvä rajapinta (interface): metodit, joilla olion tilaa muutetaan. Tämän rajapinnan ansiosta luokka muuttuu "mustaksi laatikoksi", jonka sisällöstä ulkomaailma ei tiedä mitään, mutta jonka kanssa voi kommunikoida metodien avulla.

Tämä luokan sisustan piilottaminen antaa meille mahdollisuuden toteuttaa luokka oleellisesti eri tavalla. Voimme esimerkiksi toteuttaa ajan minuutteina vuorokauden alusta laskien:
- oliot.aika.sisesitys.Aika.java - sisäinen toteutus minuutteina
Tehtävä 8.14 minuutteina()
Lisää luokkien oliot.metodit.Aika ja oliot.perinta.AikaSek sisäisiin toteutustapoihin saantimetodi getMinuutteina, joka palauttaa kellonajan vuorokauden alusta minuutteina laskettuna.
8.5 Rajapinta ja monimuotoisuus
Yksi perinnän tärkeimmistä ominaisuuksista on mahdollisuus monimuotoisuuteen, polymorfismiin. Esimerkiksi
// oliot.aika.perinta.AikaSek.java - esimerkki polymorfisesta taulukosta
Aika a1 = new Aika();
Aika a2 = new Aika(13);
Aika a3 = new Aika(14,175);
AikaSek a4 = new AikaSek(14,55,45);
Aika aika = a1; aika = a4;
aika = new AikaSek(1,95,70);
Aika ajat[] = new Aika[5];
ajat[0] = a1; ajat[1] = a2; ajat[2] = a3; ajat[3] = a4;
ajat[4] = new AikaSek(23,59,59);
for (int i=0; i < ajat.length; i++ ) {
System.out.print(ajat[i]); System.out.print(" +" + i + " => ");
ajat[i].lisaa(i); System.out.println(ajat[i]);
}Taulukko ajat koostuu viitteistä Aika-luokan olioihin. Myös AikaSek toteuttaa saman rajapinnan, koska se on peritty samasta luokasta. Siksi taulukkoon voi laittaa mitä tahansa Aika-luokan jälkeläisluokankin olioita.
Esimerkissä koostaminen.AikaSek luokka koostettiin sekunneista ja luokan Aika-oliosta. Nyt valitettavasti vain polymorfismi ei toimi, eli AikaSek ja Aika eivät ole perimissuhteessa toisiinsa. Niillä on kyllä Javassa yhteinen kantaluokka Object, koska Javassa kaikki luokat periytyvät Object-luokasta. Mutta yhteistä aikaan liittyvää rajapintaa niillä ei ole. Kömpelö polymorfismi saataisiin aikaan seuraavasti:
// oliot.aika.koostaminen.AikaSek.java - kömpelö esimerkki polymorfisesta taulukosta
Aika a1 = new Aika();
Aika a2 = new Aika(13);
Aika a3 = new Aika(14,175);
AikaSek a4 = new AikaSek(14,55,45);
Object ajat[] = new Object[5];
ajat[0] = a1; ajat[1] = a2; ajat[2] = a3; ajat[3] = a4;
ajat[4] = new AikaSek(23,59,59);
for (int i=0; i < ajat.length; i++ ) {
if ( ajat[i] instanceof Aika ) {
Aika aika = (Aika)ajat[i]; // pakotettu tyypin muunnos
System.out.print(aika + " +" + i + " => ");
aika.lisaa(i); System.out.println(aika);
}
if ( ajat[i] instanceof AikaSek ) {
AikaSek aika = (AikaSek)ajat[i]; // pakotettu tyypin muunnos
System.out.print(aika + " +" + i + " => ");
aika.lisaa(i); System.out.println(aika);
}
}Tavassa jossa joudutaan testaamaan olion tyyppiä, tulee uusien tyyppien lisääminen järjestelmään erittäin työlääksi.
Javassa avuksi tulee rajapintakäsite. Teemme ensin "mallin" siitä, minkälainen on vähintään kaikkien Aika-luokkien rajapinta:
- oliot.aika.rajapinta.AikaRajapinta.java - malli kaikkien Aika-luokkien rajapinnasta
Seuraavaksi kaikkien luokkien, joiden halutaan kuuluvan "samaan kategoriaan", ilmoitetaan toteuttavan tämän rajapinnan:
- oliot.aika.rajapinta.Aika.java - luokka joka toteuttaa rajapinnan
Valitettavasti rajapinnan toteuttavaa luokkaa ei voi pakottaa tekemään uutta toString -metodia, koska Object -luokan metodina sen toteuttaa valmiiksi jo jokainen luokka. Vaikka kääntäjä ei ilmoittaisikaan virheestä, niin tässä tapauksessa toString on hyödyllistä lisätä rajapinnan määrittelyihin, jotta ohjelmoija näkee halutun toiminnallisuuden.
Sitten esim. koosteluokka ilmoitetaan toteuttamaan myös sama rajapinta:
- oliot.aika.rajapinta.kooste.AikaSek.java - luokka joka toteuttaa rajapinnan => polymorfismi
Näin voimme jälleen tehdä taulukon, johon voimme laittaa kaikkia AikaRajapinta-määrittelyn toteuttavien luokkien olioita.
Lyhyesti: Rajapinnan avulla sovitaan, että tietyt metodit löytyvät kaikista niistä luokissa, jotka toteuttavat sen.
Rajapinta ei lyhennä ohjelmointia, koska metodit joutuu itse kirjoittamaan. Rajapintaan ei laiteta attribuutteja, vaan tarvittavat attribuutit pitää lisätä itse kaikkiin luokkiin itse.
Tämän takia usein luokkahierarkiaan tehdäänkin niin, että ensin on rajapinta ja sitten sen toteuttava perusluokka. Usein perusluokka on vielä abstrakti, eli siitä on joku tärkeä metodi vielä toteuttamatta. Sitten peritään tätä perusluokkaa ja näin säästetään ohjelmoinnissa kun ei tarvitse toteuttaa kuin muutamia tärkeitä metodeja.
Esimerkiksi:
public interface Drawable { // luvataan metodit kaikille piirrettäville
// metodien esittelyrivit ja puoliste rivin loppuun
...
}
public abstract class BasicShape implements Drawable { // toteutetaan metodit
// luokan attribuutit, mm väri, yms
// metodia draw ei toteuteta kun se ei voi yleisesti toimia
}
...
public class Line extends BasicShape { // viivaan tulee kaikki BasicShape ominaisuudet
// attribuutit janan päätepisteille
// Draw-metodin toteutus
}
...
public class Circle extends BasicShape { // ympyrään tulee kaikki BasicShape ominaisuudet
// attribuutit säteelle ja keskipisteelle
// Draw-metodin toteutus
}
...
// käytetään kaikkialla vain Drawable rajapintaa:
Drawable[] kuviot = { new Line(1,1, 3,3), new Circle(10,10, 30) };
8.6 Object-luokan metodien korvaaminen
Jos Javassa ei peritä luokkaa mistään, niin se periytyy aina Object-luokasta. Näin siksi, että kaikki oliot saadaan samaan hierarkiaan ja voidaan esimerkiksi tallentaa samaan tietorakenteeseen. Käytännössä tämä ei ole kovin kätevää, sillä silloin tietorakenteessa olevilla olioilla on käytössä vain Object-luokan metodit. Jotta olioilla voitaisiin tehdäkin jotain, pitää niiden tyyppi muuntaa vastaamaan niiden varsinaista luokkaa.
Object-luokassa on kuitenkin muutama tärkeä metodi, joiden olemassa olosta ohjelmoijan on hyvä olla tietoinen:
Object clone(); // tekee oliosta itsestään kopion
boolean equals(Object obj); // vertaa oliota toiseen olioon
int hashCode(); // palauttaa olioon liityvän "lajitteluavaimen"*
String toString(); // palauttaa olion merkkijonona// oliot.aika.object.Aika.java - luokka joka toteuttaa Object
import oliot.aika.rajapinta.AikaRajapinta;
/**
* Luokka toteuttamaan sovitun julkisen rajapinnan ja Object-
* luokan metodeja
* …
*/
public class Aika implements AikaRajapinta {
private int h, m;
/** … */
public Aika() { aseta(0, 0); }
/** … */
public Aika(int h, int m) { aseta(h, m); }
/** … */
public final int aseta(int h, int m) { …}
/** … */
public void lisaa(int lisaMin) { … }
public int getH() { return h; }
public int getM() { return m; }
/** … */
public String toString() {
return String.format("%02d:%02d", getH(), getM());
}
/**
* @example
* <pre name="test">
* Aika a1 = new Aika(13,37);
* Aika a2 = new Aika(13,37);
* a1 === a2
* </pre>
*/
public boolean equals(Object o) {
if (!(o instanceof AikaRajapinta))
return false;
AikaRajapinta a = (AikaRajapinta) o;
return getH() == a.getH() && getM() == a.getM();
}
/**
* @example
* <pre name="test">
* Aika aika = new Aika(13,37);
* Aika aika2 = (Aika)aika.clone();
* aika2.toString() === "13:37";
* </pre>
*/
public Aika clone() {
Aika a = null;
try {
a = (Aika)super.clone();
// a.aseta(h,m); // tätä ei tarvitse, koska super laittaa int yms. attr.
} catch (CloneNotSupportedException e) { //
}
return a;
}
/**
* Aika sekunteina vuorokauden alusta
* @example
* <pre name="test">
* new Aika(13,37).hashCode() === 49020;
* </pre>
*/
public int hashCode() { return 3600 * getH() + 60 * getM(); }
}Metodi toString onkin jo entuudestaan tuttu
public String toString() {
return String.format("%02d:%02d",getH(), getM());
}Kun halutaan verrata kahta Aika-oliota keskenään, kannattaa kirjoittaa equals-metodi.
public boolean equals(Object o) {
if ( !(o instanceof AikaRajapinta) ) return false;
AikaRajapinta a = (AikaRajapinta)o;
return getH() == a.getH() && getM() == a.getM();
}equals-metodia kirjoitettaessa on oltava huolellinen, sillä parametrina saattaa tulla oikean tyyppinen olio tai sitten väärän tyyppinen olio. equals-metodin pitää toteuttaa seuraavat ominaisuudet:
Olkoon seuraavassa a1,a2 ja a3 kolme luokan oliota.
| Ominaisuus | ehto |
|---|---|
| reflektiivisyys: | a1.equals(a1) pitää olla aina tosi |
| symmetrisyys: | a1.equals(a2) == a2.equals(a1) |
| transitiivisuus: | jos a1.equals(a2) && a2.equals(a3) niin a1.equals(a3) |
Luonnollisesesti toistuvien equals kutsujen pitää palauttaa samoille olioille sama arvo, mikäli olioiden samuuteen vaikuttava tila ei muutu.
Jos luokkaan toteutetaan equals-metodi, on siihen toteutettava myös hajautusarvo hashCode. Javan tietorakenteet tarvitsevat hajautusarvoa. Hajautusarvon täytyy palauttaa sama luku olioille, jotka ovat equals-vertailussa saman arvoisia. Mutta kaksi eriarvoistakin oliota saa palauttaa saman hajautusarvon. Meidän tapauksessamme hajautusarvoksi voidaan valita vaikkapa sekunnit vuorokauden alusta:
public int hashCode() {
return 3600*getH() + 60*getM();
}Lisäksi monessa tilanteessa tarvitaan oliosta samanlainen kopio. Tätä varten toteutetaan clone-metodi:
public Aika clone() {
Aika kopio = null;
try {
kopio = (Aika)super.clone();
} catch (CloneNotSupportedException e) {
// peritään Objectista ja se tukee kloonausta
}
return kopio;
}Tehtävä 8.15 equals toString avulla
Toteuta equals-metodi toString-metodin avulla. Arvioi ratkaisun tehokkuutta.
Tehtävä 8.16 equals AikaSek-luokkaan
equals-metodiin tulee ongelmia toteutettaessa AikaSek-luokkaa. Mieti mitä.
Tehtävä 8.17 AikaSek perimällä.
Esimerkissä AikaSek on toteutettu sekunnit sisältävä aikaluokka koostamalla. Kokeile miten nyt onnistuu perintä Aika-luokasta ja mitä metodeja pitää korvata.
8.6.0.4 Tehtävä 8.18 Vertailu
Tutki dokumenteista rajapintaa Comparable ja muuta luokat Aika ja AikaSek toteuttamaan tuo rajapinta.
8.7 Mistä hyviä luokkia
Alun perin kirjoittamamme luokka Aika kokikin varsin kovia tarkemmassa tarkastelussa. Näistä muutoksista osa oli vielä aivan perusasioita; läheskään kaikkea emme vieläkään ole ottaneet huomioon (lisäyksessä tapahtuvan ylivuodon luovuttaminen päivämäärälle, jne.). Miten sitten on monimutkaisempien luokkien kanssa? Niin kauan pärjää, kun luokat ovat omaan käyttöön. Heti kun yritetään tehdä yleiskäyttöisiä luokkia (joka on yksi olio-ohjelmoinnin tavoite), tuleekin ongelmia vastaan.
Paremmalla suunnittelulla luokasta olisi heti voinut tulla yleiskäyttöisempi. Usein jopa joudutaan tekemään kahden luokan yläpuolelle abstrakti, tai muuten vaan yhteinen yliluokka, josta hieman toisistaan poikkeavat luokat peritään. Kuljimme tämän pitkän tien sen vuoksi, että lukija oppisi ymmärtämään miksi valmiit luokat eivät ole parin rivin koodinpätkiä.
Tulevaisuudessa ohjelmoijat jakaantunevatkin selvästi kahteen ryhmään: toiset käyttävät valmiita luokkia (mikä on helppoa, jos luokat ovat kunnossa, vrt. Microsoftin .NET tai Delphi, ehkä myös osittain Java ja Jonnen pyynnöstä mainitaan tietysti Python). Ammattitaitoisempi ryhmä sitten suunnittelee ja tekee näitä yleiskäyttöisiä luokkia. Sitä mukaa kun luokkia saadaan valmiiksi eri "elämän aloille", siirtyvät ammattilaiset yhä spesifimmille aloille.
Monien kielten ohjelmointiin tarkoitetut luokkakirjastot ovat paisuneet niin suuriksi, että niiden käyttämistä tuskin kukaan enää hallitsee, ja ennen kuin entisen kirjaston on ehtinyt edes auttavasti oppia, tuleekin uusi versio. Tästä tulee oravanpyörä, jossa voi olla kova homma pysyä mukana, jollei ohjelmateollisuus keksi jotakin uutta ja mullistavaa avuksi.
Joka tapauksessa haave siitä, että näkee näyn ja keksii hyvän luokan, jota muut sitten yhtään muuttamatta voivat käyttää hyväkseen, kannattaa heittää Ylistönrinteen sillan alle. Mieluummin kannattaa alistua siihen, että opettelee käyttämään hyviä luokkia ja imee niitä käyttäessään ideoita siitä, miten parantaa omia luokkiaan seuraavalla kerralla.
8.8 Valmiita luokkia
Olio-ohjelmoinnin eräs tavoite on tuottaa ohjelmoijien käyttöön yleiskäyttöisiä komponentteja, jotta jokainen ei keksisi samaa pyörää uudelleen. Erityisesti graafisen ohjelmoinnin puolella ja myös tietokantaohjelmoinnin puolella näitä komponentteja onkin varsin mukavasti. Borlandin Delphillä syntyy melkein Kerho-ohjelmaamme vastaava Windows-ohjelma lähes koodaamatta, pelkästään pudottelemalla komponentteja lomakkeelle.
8.8.1 Merkkijonoluokat
Jos kerrankin pääsisin vastakkain nykykielten kehittäjien kanssa, niin tekisi kovasti mieli kysyä ovatko he koskaan tehneet oikeaa ohjelmaa. Nimittäin lähes kielestä riippumatta kunnolliset merkkijonot loistavat poissaolollaan (2000-luvun alku), ja ohjelmoijat ovat käyttäneet äärettömästi työtunteja tehdessään itselleen aluksi edes auttavaa merkkijonokirjastoa. Ainoastaan "lelukielissä" - Basicissä ja Turbo Pascalissa on ollut hyvät ja turvalliset merkkijonot.
C-kielen char jono[10] on todellinen aikapommi, jonka aukkoisuuteen perustuu vielä tänäkin päivänä useat hakkereiden kikat murtautua vieraisiin tietojärjestelmiin. Katsotaanpa ensin mitä C-merkkijonoille voi/ei voi tehdä:
char s1[10],s2[5],*p;
p = "Kana" // Toimii!
p[0] = 'S'; // Toimii! Mutta jatkossa käy huonosti...
s1 = "Kissa"; // ei toimi!
strcpy(s2,"Koira"); // Huonosti käy! Miksi? Älä käytä koskaan...
if ( s1 < s2 ) ... // Sallittu, mutta tekee eri asian kuin lukija arvaakaan...
gets(s1); // Itsemurha, tämä on eräs kaikkein hirveimmistä funktioista
// lukee päätteeltä rajattomasti merkkejä ...
fgets(s1,sizeof(s1),stdin); // Oikein! Tosin rivinvaihto jää jonoon jos syöte
// on lyhyempi kuin 9 merkkiä*
printf(s1); // Ohohoh! Tämä jopa toimii!!!
cout << s1; // Ja jopa tämäkin!!!
cin >> s1; // Taas itsemurha ....Jos käytetään C-kieltä, pitää käyttää varsin paljon aikaa siihen miten C:n merkkijonoja voidaan kohtuullisen turvallisesti käyttää.
Onneksi C++:ssa on kohtuullinen merkkijonoluokka. Nyt jo (v. 1999)! Yli 10 vuotta kielen kehittämisen jälkeen...
Katso esimerkiksi: Merkkijonot ja C++.
Javassa kuten C#:issakin on vastaavasti kaksi merkkijonoluokkaa: String ja StringBuilder. Ensin mainittu koskee merkkijonoja, joita ei koskaan (immutable) tarvitse muuttaa, vaan riittää aina luoda uusi merkkijono. Jälkimmäistä käytetään, mikäli jonoon tulee paljon muutoksia (mutable).
8.9 this-escape -virhe
Muodostajan kanssa on oltava tarkkana, ettei tule this-escape -virhettä. Tämä tulee silloin, jos this-viite tavalla tai toisella pääsee jollekin metodille, jolla ei ole varmaa että olio on kunnolla alustettu. Helppo tapa saada virhe aikaiseksi on kutsua muodostajasta metodia, joka ei ole final. Seuraavassa hieman keinotekoinen esimerkki asiasta. Siinä aikavyöhyke on esitetty hölmösti StringBuilder-oliolla, jotta ongelma saadaan esiin. Esimerkissä this karkaa sen takia, että perityn luokan aseta-metodi pääsee sitä käyttämään liian aikaisin. Esimerkissä peritty luokka on kirjoitettu samaan tiedostoon jolloin se ei voi olla public.
Edellä ongelmana on siis se, että aseta-metodia kutsutaan Aika-luokan muodostajasta. Kun AikaVyohykkeella-luokkaa muodostetaan, kutsutaan sieltä Aika-luokan muodostajaa joka kutsuu ylikirjoitettua aseta-metodia. Silloin vyohyke-viite on vielä null-viite ja ohjelma kaatuu riviin jossa vyohyke-attribuuttia yritetään muokata. Ongelman voisi yrittää korjata niin, että siirtäisi rivin
muodostajan alkuun. Tämä ei kuitenkaan onnistu, sillä vanhempi-luokan muodostajan kutsu super pitää olla muodostajan ensimmäinen lause. Tässä erikoistapauksessa ongelmaan voitaisiin kiertää niin, että ylikirjoitettu aseta pitäisi huolen, että vyohyke viittaa johonkin StringBuilder-olioon. Hieman vähemmän ongelmia tulisi jos vyohyke olisi String-tyyppinen.
Tarkoitus oli kuitenkin tuolla StringBuilder-esimerkillä esittää miten ongelma voi tulla, jos olio ei ole täysin alustettu jossakin metodissa. Aika-luokassa olisi voitu estää tällaisen vahingon tuleminen kahdella tavalla:
public final class Aika {- tällöin luokkaa ei voisi periäpublic final void aseta(int h, int m) {- nytaseta-metodista ei voisi tehdä rikkinäsitä versiota
Tässä esimerkissä vaihtoehto 2 olisi ehkä järkevä ja sitten tehtäisiin AikaVyohykkeella-luokkaan oma aseta, jossa on kolme parametria. Tosin alla vielä on vikana, että h ja m alustetaan 2 kertaa.
public final void aseta(int h, int m, String v) {
super.aseta(h, m);
this.vyohyke.setLength(0);
this.vyohyke.append(v);
}
public AikaVyohykkeella(int h, int m, String v) {
super(h,m);
this.vyohyke = new StringBuilder();
aseta(h, m, v);
}Kahden alustamisen välttämiseksi muodostaja voisi olla:
public AikaVyohykkeella(int h, int m, String v) {
super(h,m);
this.vyohyke = new StringBuilder(v);
}mutta silloin taas otetaan kahdessa paikassa kantaa siihen, miten vyohyke asetetaan.
8.10 Tehdasmetodit
Kokonaan toinen, ehkä nykyisin jopa suositeltava, lähestymistapa olisi tehdä tehdasmetodeja. Tehdasmetodi on metodi, joka luo oikealla tavalla alustetun halutun tyyppisen olion. Tehdasmetodissa voidaan olion luomisen ihan hyvin kutsua mitä tahansa olion metodia.
Esimerkki on toki vielä keinotekoinen, koska siinä ei hyödynnetä aikavyöhykettä kunnolla (ja se ei tietenkään oikeasti olisi StringBuilder).
Tehdasmetodeilla on paljon muitakin hyötyjä kuin this-escapen välttäminen:
- Selkeyttää koodia: Tehdasmetodit voivat tehdä koodista selkeämpää ja helpommin luettavaa, koska ne antavat selkeän nimen olion luomisprosessille. Tehdasmetodin nimi voi olla vaikka
getInstance(). - Yksinkertaistaa luomista: Tehdasmetodit voivat piilottaa monimutkaisen luomislogiikan ja tarjota yksinkertaisen tavan luoda olioita.
- Joustavuus: Tehdasmetodit mahdollistavat aliluokkien tai erilaisten olioiden luomisen ilman, että kutsujan tarvitsee tietää tarkalleen, mistä luokasta olio luodaan.
- Yhtenäinen käyttöliittymä: Tehdasmetodit tarjoavat yhtenäisen tavan luoda olioita, mikä voi helpottaa koodin ymmärtämistä ja käyttöä.
Yllä olevassa esimerkissä ei toki saada kaikki hyötyjä esille.
Tyypillinen esimerkki tehdasmetodin käytöstä voisi olla sellainen tapaus, jossa meillä on vaikkapa tiedostossa erilaisten graafisten olioiden tietoja tyyliin:
tyyppi; x ; y ;
ympyra; 10; 20; 5
ympyra; 20; 30; 8
piste; 10; 10
suorakulmio; 30; 30; 60; 80Sitten meillä ohjelma lukee tuota tiedostoa
Tuossa IKuvio olisi kantarajapinta kaikille erilaisille kuvioille ja sitten Kuvio.luo olisi tehdasmetodi, joka erottaa kuvion tyypin ja sen perustella luo oikein tyyppisen IKuvio-luokan rajapinnan toteuttavan olion, esimerkiksi Ympyra-luokan olion ja pyytää sitä ottamaan omat tietonsa lopusta merkkijonosta. Tällöin järjestelmään olisi helppoa lisätä uusia kuviotyyppejä koskematta esimerkin silmukkaan.
Yksi hyvä esimerkki tehdasmetodeista on vaikkapa Javan Calendar-luokka:
Tuon
ideana on, että oikeastaan meidän länsimaissa pitäisi tarkkaan ottaen luoda
Jossakin muussa kulttuurissa voisi olla joku toinen kalenterityyppi. Mutta nyt tuo tehdasmetodi
voi koneen asetusten perusteella päättää minkä kulttuuriin kalenteri luodaan. Tosin Javassa ei taida vieläkään tällä hetkellä olla muita Calendar-luokan perillisiä.
Huomaa, että kaikkien aikoihin ja päivämääriin liittyvien haasteiden (karkausvuodet, karkaussekunnit, aikavyöhykkeet yms.) takia kannattaa oikeasti käyttää kieleen tehtyjä valmiita luokkia.
9. Java-kielen ohjausrakenteista ja operaattoreista
Ihvilläpä ihmettele
silmukalla suorittele
lopetukset laskeskele
virityksii vierastele.
Alusta kun ehto jääpi
siit silmukka iänikuinen
aina suru ei surkeen suuri
joutaapa avuksi tääkin.
Katkoo saapi keskeltäkin
jatkaa vaikka muualtakin
paluu kelpo keino myöskin
kunhan kaikki katseltuna.
Mitä tässä luvussa käsitellään?
- if-else -lause
- loogiset operaattorit: &&, || ja !
- bittitason operaattorit: &,|,^ ja ~
- silmukat while, do-while, for ja for-each
- silmukan "katkaisu" break, continue, goto
- sijoituslauseet: = += -= jne.
- valintalause switch
Syntaksi:
lause joko ylause; // HUOM! Puolipiste
tai lohko // eli koottu lause
ylause yksinkertainen lause
esim a = b + 4
vaihda(a,b)
lohko { lause1 lause2 lause3 } // lauseita 0-n
esim { a = 5; b = 7; }
ehto lauseke joka tuottaa false tai true
esim a < 5
( 5 < a ) && ( a < 10 )
!(a == 0) // jos a=0 => 1, muuten 0
HUOM! Vertailu a == 5
if-else if ( ehto ) lause1
else lause2 // ei pakollinen
while while ( ehto ) lause;
do-while do lause while ( ehto );
for for ( ylause1a,ylause2a; ehto ; ylause1k,ylause2k ) lause
esim for ( i=0,s=0; i<10; i++ ) s += i; // ylause1a
switch switch ( lauseke ) {
case arvo1: lause1 break; // valintoja 0-n
casearvo2: // arvolla 2 ja 3 sama
case arvo3: lause2 break;
default: laused break; // ei pakollinen
}Luvun esimerkkikoodit:
Ohjelma jossa ei ole minkäänlaista valinnaisuutta tai silmukoita on varsin harvinainen. Kertaamme seuraavassa Java-kielen tarjoamat mahdollisuudet suoritusjärjestyksen ohjaamiseen. Samalla näemme kuinka suomenkielisen algoritmin kääntäminen ohjelmointikielelle on varsin mekaanista puuhaa.
9.1 if-lause
Mikäli meillä on kaksi lukua, jotka pitäisi olla suuruusjärjestyksessä, voisimme hoitaa järjestämisen seuraavalla algoritmilla:
1. Jos luvut väärässä järjestyksessä,
niin vaihda ne keskenäänTämän kirjoittamiseksi ohjelmaksi tarvitsemme ehto-lausetta:
if ( ehto ) ylause1;
lause2;Huomattakoon, että tässä sulut ehdon ympärillä ovat pakolliset. lause1 suoritetaan vain kun ehto on voimassa. lause2 suoritetaan aina. Lause voitaisiin kirjoittaa myös muodossa
if(ehto) ylause1; // HUOM! Sulku EI saa olla kiinni if-lauseessa
lause2;muttei näin tehdä, jotta erottaisimme paremmin funktion ja if-lauseen toisistaan. Sama tulee koskemaan myös for, while ja muita vastaavia rakenteita.
9.1.1 Ehdolla suoritettava yksi lause
Olkoon meillä aliohjelma nimeltään tulosta, joka tulostaa parametrina viedyn luvun:
if ( a > b ) tulosta(a);9.1.2 Ehdolla suoritettava useita lauseita
Jos esimerkiksi luvut pitäisi vaihtaa keskenään, täytyisi meidän voida suorittaa useita lauseita muuttujien vaihtamiseksi. Java-kielessä voidaan lausesuluilla kasata joukko lauseita yhdeksi lauseeksi (lohko, koottu lause, block):
Sisennä kauniisti
if ( a > b ) {
t = a;
a = b;
b = t;
}Huomautus! Lauseiden kirjoittaminen samalle riville ei auttaisi mitään, sillä
if ( a > b ) t = a; a = b; b = t;
/* vastaisi loogisesti rakennetta: */
if ( a > b ) t = a;
a = b;
b = t;Koodia voidaan kuitenkin usein lyhentää kirjoittamalla asioita samalle riville:
if ( a > b ) {
t = a; a = b; b = t;
}
/* tai joskus jopa */
if ( a > b ) { t = a; a = b; b = t; }Niin kauan kuin todella hallitsee asian, voi olla helpointa laittaa aina if-lauseen ainoakin suoritettava lause lausesulkuihin
if ( a > b ) {
tulosta(a);
}Mikäli sulkuja ei olisi, täytyisi toisen lauseen lisäyksen yhteydessä muistaa lisätä myös sulut (tosin eihän hyvin suunniteltua ohjelmaa tarvinnut enää jälkeenpäin paikata?).
Tehtävä 9.1 vaihda
Esitä pöytätestin avulla miksei vaihtaminen onnistu pelkästään lauseilla:
a = b; b = a;Tehtävä 9.2 abs
Kirjoita funktio
int itseisarvo(int i),joka palauttaa i:n itseisarvon (negat. muutet. posit.).
Tehtävä 9.3 jarjesta2
Kirjoita aliohjelma
void tulosta2(int a, int b),joka tulostaa luvut suuruusjärjestyksessä .
Tehtävä 9.4 maksimi ja minimi
Kirjoita funktio
int maksimi(int a, int b),joka palauttaa suuremman kahdesta luvusta.
Kirjoita vastaava funktio minimi.
9.2 Loogiset lausekkeet
Java-kielessä vain boolean-arvoiset lausekkeet käsitellään loogisina lausekkeina. Arvo false on epätosi ja true on tosi.
a = 4;
if ( a == 4 ) ...
boolean samat;
samat = ( a == 4 );
if ( samat ) ...9.2.1 Vertailuoperaattorit
Vertailuoperaattorin käyttö muodostaa loogisen lausekkeen, jonka arvo on false tai true. Vertailuoperaattoreita ovat:
| op | nimi |
|---|---|
| == | yhtäsuuruus |
| != | erisuuruus |
| < | pienempi kuin |
| <= | pienempi tai yhtä kuin |
| > | suurempi kuin |
| >= | suurempi tai yhtä kuin |
Esimerkkejä vertailuoperaattoreiden käytöstä:
if ( a < 5 ) System.out.println("a alle viisi!");
if ( a > 5 ) System.out.println("a yli viisi!");
if ( a == 5 ) System.out.println("a tasan viisi!");
if ( a != 5 ) System.out.println("a ei ole viisi!");9.2.2 Sijoitus palauttaa arvon!
Yhtäsuuruutta verrataan == operaattorilla, EI sijoituksella =. Tämä on eräs tavallisimpia aloittelevan (ja kokeneenkin) C-ohjelmoijan virheitä:
/* Seuraava tulostaa vain jos a == 5 */
if ( a == 5 ) tulosta("a on viisi!n"); /* Kääntyy Javassa ja C:ssä */
/* Seuraava sijoittaa aina a = 5 ja tulostaa AINA! /* // VÄÄRIN
if ( a = 5 ) printf("a:ksi tulee AINA 5!n"); */* Kääntyy vain C:ssä */*Sijoitus a=5 on myös lauseke, joka palauttaa arvon 5. Siis sijoitus kelpaa tästä syystä vallan hyvin loogiseksi lausekkeeksi C-kielessä. Onneksi Javassa tämä sijoituksen tuloksena syntynyt lausekkeen kokonaislukuarvo EI kelpaa boolean-arvoksi, joten kääntäjä ei hyväksy sijoitusta vahingossa yhtäsuuruuden vertailun tilalle.
Joskus ominaisuutta voidaan tarkoituksella käyttää hyväksikin. Esimerkiksi halutaan sijoittaa AINA a=b ja sitten suorittaa jokin lause, mikäli b!=0. Tämä voitaisiin kirjoittaa useilla eri tavoilla:
ohjausrak.Ifsij2.java - esimerkki tahallisesta sijoituksesta ehdossa
int a,b=5; /*1*/ // a = b; if ( b ) tulosta("b ei ole nolla!"); /*2*/ a = b; if ( b != 0 ) tulosta("b ei ole nolla!"); /*3*/ // if ( a = b ) tulosta("b ei ole nolla!");* /*4*/ if ( (a=b) != 0 ) tulosta("b ei ole nolla!");
Edellisistä tapa 3 on C-mäisin, mutta Java-kääntäjä ei onneksi hyväksy sitä. Jotta C-mäinen tapa voitaisiin säilyttää, voidaan käyttää tapaa 4 jonka kääntäjä hyväksyy. Oleellista on, että sijoitus on suluissa (muuten tulisi sijoitus a =(b!=0) ). Mikäli asian toimimisesta on pieninkin epäilys, kannattaa käyttää tapaa 2!
Tyypillinen esimerkki sijoituksesta ja testauksesta samalla on vaikkapa tiedoston lukeminen:
while ( ( rivi = f.readLine() ) != null ) { // jos sijoitus palauttaa null,
// on tiedosto loppu
... käsitellään tiedoston riviä
}Jos edellisen esimerkin tiedoston lukemisessa ei käytettäisi sijoitusta ja testiä samalla, pitäisi tämä kirjoittaa muotoon:
while ( true ) {
rivi = f.readLine();
if ( rivi == null ) break;
... käsitellään tiedoston riviä
}9.3 Loogisten lausekkeiden yhdistäminen
Loogisia lauseita voidaan yhdistää loogisten operaatioiden avulla. Lisäksi esimerkiksi C:ssä lauseita voidaan yhdistää myös normaaleilla operaatioilla (+,-,*,/), mutta tämä ei ole oikein hyvien tapojen mukaista.
9.3.1 Loogiset operaattorit &&, || ja !
| op | toiminta |
|---|---|
| && | ja |
| || | tai |
| ! | muuttaa ehdon arvon päinvastaiseksi (eli false->true, true->false) |
Mikäli yhdistettävät ehdot koostuvat esimerkiksi vertailuoperaattoreiden käytöstä, kannattaa ehtoja sulkea sulkuihin, jottei seuraa turhia epäselvyyksiä.
if ( ( rahaa > 50 ) && ( kello < 19 ) ) tulosta("Mennään elokuviin!");
if ( ( rahaa < 50 ) || ( kello >3 ) ) tulosta("Ei kannata mennä kapakkaan!");
if ( ( 8 <= kello ) && ( kello <= 16 ) ) tulosta("Pitäisi olla töissä!");
if ( ( rahaa == 0 ) || ( sademaara < 10 ) ) tulosta("Kävele!");Usein tulee vastaan tilanne, jossa pitäisi testata onko luku jollakin tietyllä välillä. Esimerkiksi onko
1900 <= vuosi <= 1999palauttaisi C-kielisenä lauseena aina 1. Miksikö? Koska lause jäsentyy
( 1900 <= vuosi ) <= 1999
0 tai 1 <= 1999 eli aina 1Javassa onneksi lauseke ei edes käänny, koska totuusarvoa ja kokonaislukua ei voi verrata keskenään. Oikea tapa kirjoittaa väli olisi:
if ( ( 1900 <= vuosi ) && ( vuosi <= 1999 ) ) ...Huomattakoon edellä miten väliä korostettiin kirjoittamalla välin päätepisteet lauseen laidoille.
Java-kielen sidontajärjestyksen ansiosta lause toimisi myös ilman sisimpiä sulkuja, mutta ne kannattaa pitää mukana varmuuden vuoksi. Vertailtavat kannattaa kirjoittaa nimenomaan tähän järjestykseen, koska tällöin vertailu muistuttaa eniten alkuperäistä väliämme!
Vastaavasti jos arvon halutaan olevan välin ulkopuolella, kannattaa kirjoittaa:
if ( ( vuosi < 1900 ) || ( 1999 < vuosi ) ) ...Tällöin epäyhtälöiden suuntaa ei joudu koskaan miettimään, vaan arvot ovat aina siinä järjestyksessä kuin lukusuorallakin:
1900 vuosi 1999 1900<=vuosi && vuosi <=1999
-----------o==============o--------------------
vuosi 1900 1999 vuosi vuosi<1900 || 1999 <vuosi
===========o--------------o====================9.3.2 Loogisen lausekkeen suoritusjärjestys
Loogiset lausekkeet suoritetaan AINA vasemmalta oikealle, kunnes ehdon arvo on selvinnyt.
Siis: Loogisen lausekkeen evaluoiminen lopetetaan heti kun ehdon arvo selviää (boolean expression shortcut).
Esimerkiksi:
if ( a != 0 || ( (b=c)==0 ) ) System.out.println("Kukkuu");Tai-operaattorin (||) oikealla puolella oleva sijoitus suoritetaan vain mikäli a==0:
| a | b | c | sij.suor | tulostetaan |
|---|---|---|---|---|
| 0 | ? | 0 | kyllä | kyllä |
| 0 | ? | 3 | kyllä | ei |
| 5 | ? | 0 | ei | kyllä |
| 5 | ? | 3 | ei | kyllä |
Tätä ominaisuutta voidaan käyttää hyväksi esimerkiksi jos on vaara että olion arvo on null:
if ( (jono != null) && jono.equals("kissa") ) tulosta("On kissa");Tällöin testissä ei turhaan tule null-viittausta koska ehtoa jono.equals ei suoriteta muuta kuin jonon ollessa viite todelliseen olioon.
Kekseliäämpi ohjelmoija kirjoittaisi testin kuitenkin luettavampaan muotoon
if ( "kissa".equals(jono) ) tulosta("On kissa");Nyt kysytään varmasti olemassa olevalta String -luokan instanssilta onko sen sisältö sama kuin jonon, jolloin null-viittausta ei tarvitse tarkastaa.
9.3.3 Loogiset operaattorit & ja |
Ja (&&) ja tai (||) -operaattoreista on myös versiot, joilla aina evaluoidaan (suoritetaan) kaikki lausekkeen osat, vaikka ehdon arvo selviäisi jo aikaisemminkin.
| op | toiminto |
|---|---|
| & | ja - suorittaa aina lausekkeen molemmat puolet |
| | | tai - suorittaa aina lausekkeen molemmat puolet |
Aikaisempaa esimerkkiä mukaillen:
if ( a != 0 | ( (b=c)==0 ) ) System.out.println("Kukkuu");Tai-operaattorin (|) oikealla puolella oleva sijoitus suoritetaan riippumatta a: n arvosta:
| a | b | c | sij.suor | tulostetaan |
|---|---|---|---|---|
| 0 | ? | 0 | kyllä | kyllä |
| 0 | ? | 3 | kyllä | ei |
| 5 | ? | 0 | kyllä | kyllä |
| 5 | ? | 3 | kyllä | kyllä |
Vastaavasti olisi paha virhe kirjoittaa:
if ( (jono != null) & jono.equals("kissa") ) // VÄÄRIN
System.out.println("On kissa");9.4 Bittitason operaattorit
Yksi C-kielen vahvoista piirteistä erityisesti alemman tason ohjelmoinnissa on mahdollisuus käyttää bittitason operaattoreita.
Loogisia operaattoreita &&, || ja ! ei pidä sotkea vastaaviin bittitason operaattoreihin:
| op | toiminta |
|---|---|
| & | bittitason AND |
| | | bittitason OR |
| ^ | bittitason XOR |
| ~ | bittitason NOT |
| << | rullaus vasemmalle, 0 sisään oikealta |
| >> | rullaus oikealle, 0 sisään vasemmalta (unsigned int ja int >=0), voi tulla 0 tai 1 sisään vasemmalta (int joka <0) (laiteriippuva, esim. Turbo C:ssä tulee 1). |
Bittitason operaattoreita voidaan käyttää vain kokonaisluvuiksi muuttuviin operandeihin.
Operaattoreiden toimintaa voidaan kuvata seuraavasti. Olkoon meillä sijoitukset a=5; b=14;. Kuvitellaan kokonaisluvut tilapäisesti 8 bitin mittaisiksi (oikeasti yleensä 16 tai 32 bittiä):
| lauseke | Binäärisenä | desim. | Huom! |
|---|---|---|---|
| a | 0000 0101 | 5 | |
| b | 0000 1110 | 14 | |
| a & b | 0000 0100 | 4 | |
| a | b | 0000 1111 | 15 | |
| a ^ b | 0000 1011 | 11 | |
| ~a | 1111 1010 | -6 | |
| a<<2 | 0001 0100 | 20 | |
| b>>3 | 0000 0001 | 1 | |
| a && b | 0000 0001 | 1 | Toimii vain C:ssä |
| a || b | 0000 0001 | 1 | Toimii vain C:ssä |
| !a | 0000 0000 | 0 | Toimii vain C:ssä |
Huomautus! Tyypillinen ohjelmointivirhe on sotkea keskenään loogiset ja bittitason operaattorit. Javassa onneksi kääntäjä tekee tämän vaikeammaksi.
Tehtävä 9.5 Loogiset/bittitason operaattorit
Mitä tulostaa seuraava ohjelman osa.
int a=5, b=2;
if ( a != 0 && b != 0 ) tulosta("On ne!");
if ( (a&b) != 0) tulosta("Ei ne ookkaan!");
if ( a != 0 ) tulosta("a on!");
if ( ~b != 0) tulosta("b ehkä on!");
if ( !(b == 0) ) tulosta("b ei ole!");Tehtävä 9.6 Luku parilliseksi
Kirjoita funktio parilliseksi, joka palauttaa parametrinaan olevan kokonaisluvun pienemmäksi parilliseksi luvuksi "katkaistuna". Eli esim.
3 -> 2. 5 -> 4. 4 -> 4.9.5 if -else-rakenne
if -lauseesta on myös versio, jossa jotakin voidaan tehdä ehdon ollessa epätosi:
if ( ehto ) ylause1;
else ylause2;Jälleen, mikäli jommassa kummassa osassa tarvitaan useampia lauseita, suljetaan lausejoukko lausesuluilla. Tosin kannattaa taas harkita lausesulkujen käyttöä aina myös yhdenkin lauseen tapauksessa.
if ( a < 5 ) tulosta("a alle viisi!");
else tulosta("a vähintään viisi!");
// Eri riville:
if ( a < 5 )
tulosta("a alle viisi!");
else
tulosta("a vähintään viisi!");
// Lausesulkujen käyttö:*
if ( a < 5 ) {
tulosta("a alle viisi!");
}
else {
tulosta("a vähintään viisi!");
}
// Seuraavaa tyyliä käytetään myös usein:
if ( a < 5 ) {
tulosta("a alle viisi!");
} else {
tulosta("a vähintään viisi!");
}9.5.1 Sisäkkäiset if-lauseet
Meillä oli aikaisemmin tehtävänä kirjoittaa funktio, joka palauttaa toisen asteen yhtälön ax2+bx+c=0 toisen juuren. Tällöin oletuksena oli, että a<>0 ja D>=0. Mikäli ratkaisukaavaa sovelletaan sellaisenaan ja a=0 tai D<0, niin tällöin ohjelman suoritus päättyy ajonaikaiseen virheeseen.
Voisimme muuttaa tehtävän määrittelyä siten, että kumpikin juuri pitää palauttaa ja funktion nimessä palautetaan tieto siitä, tuliko ratkaisussa virhe, eli jollei juuret olekaan reaalisia.
if ( a != 0 ) {
D = b*b - 4*a*c;
if ( D > 0 ) {
...
}
else {
...
}
}
else {
...
}Tosin yhtälö pystytään mahdollisesti ratkaisemaan myös kun a==0. Tällöin tehtävä jakautuu useisiin eri tilanteisiin kertoimien a,b ja c eri kombinaatioiden mukaan:
| a | b | c | D | yhtälön muoto | juuret reaalisia | x1 | x2 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | ? | 0 = 0 | juu | 0 | 0 |
| 0 | 0 | c | ? | c = 0 | ei | 0 | 0 |
| 0 | b | ? | ? | bx - c = 0 | juu | 0 | 0 |
| a | ? | ? | >=0 | a2 + b + c = 0 | juu | (-b-SD)/2a | (-b+SD)/2a |
| a | ? | ? | <0 | - " - | ei |
Algoritmiksi kirjoitettuna tästä seuraisi:
1. Jos a=0, niin
Jos b=0
Jos c=0 yhtälö on muotoa 0=0 joka on aina tosi
palautetaan vaikkapa x1=x2 =0
muuten (eli c<>0) yhtälö on muotoa c=0 joka on
aina epätosi, palautetaan virhe
muuten (eli b<>0) yhtälö on muotoa bx=c
joten voidaan palauttaa vaikkapa x1=x1=-c/b
2. Jos a<>0, niin
Jos D>=0 kyseessä aito 2. asteen yhtälö ja käytetään
ratkaisukaavaa
muuten (eli D<0) ovat juuret imaginaarisiaFunktio ja sen testiohjelma voisi olla esimerkiksi seuraavanlainen:
- ohjausrak.polynomi.v1.Polynomi2.java - esimerkki 2. asteen yhtälön ratkaisemisesta
Edellinen metodi ratkaise2AsteenYhtalo on äärimmäinen esimerkki sisäkkäisistä if-lauseista. Jälkeenpäin sen luettavuus on erittäin heikko ja myös kirjoittaminen hieman epävarmaa. Parempi kokonaisuus saataisiin lohkomalla tehtävää pienempiin osasiin aliohjelmien tai makrojen avulla.
Sisäkkäisten if-lauseiden kirjoittamista voidaan helpottaa kirjoittamalla niitä sisenevästi, eli aloittamalla ensin tekstistä:
if ( a == 0 ) { /* bx + c = 0 */
} /* a==0 */
else { /* axx + bx + c = 0 */
D = b*b - 4*a*c;
}Sitten täydennetään vastaavalla ajatuksella sekä if-osan että else-osan toiminta.
Jos funktiosta karsitaan kaikki ylimääräinen (kommentit ja ylimääräiset lausesulut) pois, saamme seuraavan näköisen kokonaisuuden:
// ohjausrak.polynomi.v2.Polynomi2.java - karsittu versio 2. asteen yhtälöstä
private int ratkaise2AsteenYhtalo() {
double D,SD;
x1 = x2 = 0;
if ( a == 0 )
if ( b == 0 ) {
if ( c == 0 ) return 1;
else return 0;
}
else {
x1 = x2 = -c/b;
return 1;
}
else {
D = b*b - 4*a*c;
if ( D >= 0 ) {
SD = Math.sqrt(D);
x1 = (-b-SD)/(2*a);
x2 = (-b+SD)/(2*a);
return 2;
}
else return 0;
}
}Joskus kannattaa harkita olisiko luettavuuden kannalta paras esitystapa sellainen, että käsitellään "normaaleimmat" tapaukset ensin:
// ohjausrak.polynomi.v3.Polynomi2.java - normaalit tapaukset ensin ratkaisussa
private int ratkaise2AsteenYhtalo() {
double D,SD;
x1 = x2 = 0;
if ( a != 0 ) {
D = b*b - 4*a*c;
if ( D >= 0 ) {
SD = Math.sqrt(D);
x1 = (-b-SD)/(2*a);
x2 = (-b+SD)/(2*a);
return 2;
}
else return -1;
}
else /* a==0 */
if ( b != 0 ) {
x1 = x2 = c/b;
return 1;
}
else { /* a==0, b==0 */
if ( c == 0 ) return 1;
else return 0;
}
}Usein aliohjelman return-lauseen ansiosta else -osat voidaan jättää poiskin:
// ohjausrak.polynomi.v4.Polynomi2.java - else -osat pois
private int ratkaise2AsteenYhtalo() {
double D,SD;
x1 = x2 = 0;
if ( a == 0 ) {
if ( b == 0 ) {
if ( c == 0 ) return 1;
return 0;
}
x1 = x2 = -c/b;
return 1;
}
D = b*b - 4*a*c;
if ( D < 0 ) return -1;
SD = Math.sqrt(D);
x1 = (-b-SD)/(2*a);
x2 = (-b+SD)/(2*a);
return 2;
}Edellä oli useita eri ratkaisuja saman ongelman käsittelemiseksi. Liika kommenttien määrä saattaa myös sekoittaa luettavuutta kuten 1. esimerkissä. Toisaalta liian vähillä kommenteilla ei ehkä kirjoittaja itsekään muista jälkeenpäin, mitä tehtiin ja miten. Jokainen valitkoon edellä olevista itselleen sopivimman kultaisen keskitien.
Huomattakoon vielä lopuksi, että rakenne
if ( c == 0 ) return true;
else return false;voitaisiin korvata rakenteella
return ( c == 0 );ja rakenne
if ( c == 0 ) return false;
else return true;rakenteella
return c != 0;9.5.2 Useat peräkkäiset ehdot
Vaikka rakenne
if (ehto1) lause1;
else
if (ehto2) lause2;
else
if (ehto3) lause3;
else lause4;jossain mallissa sisennetäänkin ylläkuvatulla tavalla, on ajatus useimmiten lähempänä seuraavaa sisennystä:
// ohjausrak.Postimaksu.java - esimerkki samanarvoisista ehtolauseista
public static double postimaksu(double paino)
{
if ( paino <= 50 ) return 1.00; // HUONO; ks alla
else if ( paino <= 100 ) return 1.40;
else if ( paino <= 250 ) return 2.00;
else if ( paino <= 500 ) return 4.00;
else if ( paino <= 1000 ) return 6.00;
else if ( paino <= 2000 ) return 10.00;
else return 0.00;
}Sovimme siis, että rakenne onkin muotoa:
if ( ehto1 ) lause1
else if ( ehto2 ) lause2
else if ( ehto3 ) lause3
else lause4On myös helppo huomata, että aliohjelma postimaksu toimisi täysin samalla tavalla, vaikka jokaisen if-lauseen else-osan jättäisi kokonaan pois. Usein liian vaikeilla ehtorakenteilla monimutkaistetaan turhaan koodia.
Tehtävä 9.7 elset pois
Aliohjelma postimaksu oli mahdollista kirjoittaa ilman else-lauseita. Miksi?
Tehtävä 9.8 Lääni
Kirjoita aliohjelma
void laani(string rekisteri)joka tulostaa missä läänissä auto on rekisteröity. (Ennen oli Suomessa monta lääniä ja rekisterinumeron 1. kirjain määräsi missä läänissä auto oli rekisteröity).
Kirjaimen yhtäsuuruutta testataan if ( c == 'a' ) ...
Merkkijonon 1. merkki saadaan c = rekisteri[0]; edellyttäen tietysti että rekisteri != "".
Tehtävä 9.9 if-else
Mitä ovat muuttujien arvot seuraavien ohjelmanpätkien jälkeen (pöytätesti!)?
/* 1 * / a=1; b=2; c=3;
if (a<5)
b=3;
a=6;
c=7;
/* 2 */ a=1; b=2; c=3;
if (a<5) b=3; a=6; c=7;
/* 3 */ a=1; b=2; c=3;
if (a<5) { b=3; a=6; }
c=7;
/* 4 * / a=1; b=2; c=3;
if (a<5) b=3; else
{ a=6; c=7; }
/* 5 */ a=1; b=2; c=3;
if (a<0) a=3; else;
if (a>2) b=3; a=6;
c=7;
/* 6 */ a=1; b=2; c=3;
if (a<-5) if (a\<0) a=6;
else a=2; c=7;
/* 7 */ a=1; b=2; c=3;
if (a<-5) b=3;
if (a<5) a=6;
else a=2; c=7;
/* 8 */ a=1; b=2; c=3;
if (a<0) a=3; else;
if (a>2) b=3; a=6;
c=7;Sisennä ohjelmanpätkät "asianmukaisesti".
9.6 do-while -silmukka
Aikaisemmin olemme tutustuneet erääseen algoritmiin, joka selvittää onko luku alkuluku vai ei. Koska algoritmi on valmis, voimme kirjoittaa vastaavan ohjelman (% -operaattori antaa jakojäännöksen, 10 % 3 == 1 ):
- alkeet.alkuluku.Alkuluku.java - testataan onko luku alkuluku
Käytimme tässä silmukkaa:
do
lause
while (ehto);Koska esimerkin silmukassa oli useita suoritettavia lauseita, oli lauseet suljettu lausesuluilla. Jälleen voi olla hyvä tapa käyttää AINA lausesulkuja.
Huomautus! Silmukoiden kanssa on syytä olla tarkkana sekä 1. kierroksen että viimeisen kierroksen kanssa. Myös silmukan lopetusehdon on syytä muuttua silmukan suorituksen aikana.
Eräs tyypillinen esimerkki do-while silmukan käytöstä olisi seuraava:
import fi.jyu.mit.ohj2.Syotto;
/**
* Ohjelmalla luetaan luku, kunnes se on halutulla välillä
* @author Vesa Lappalainen
* @version 1.0, 07.02.2003
*/
public class Dowhile {
public static void main(String[] args) {
int luku;
do {
luku = Syotto.kysy("Anna luku väliltä [0-20]",0);
} while ( luku < 0 || 20 < luku );
System.out.println("Annoit luvun " + luku);
}
}9.7 while -silmukka
do-while -silmukka suoritetaan aina vähintään 1. kerran. Joskus on tarpeen silmukka, jonka runkoa ei suoriteta yhtään kertaa. Muutamme edellisen esimerkkimme käyttämään while -silmukkaa:
while ( ehto ) lauseMuutamme samalla algoritmia siten, että 2:lla jaolliset käsitellään erikoistapauksena. Näin pääsemme eroon "inhottavasta" kasvatus-muuttujasta.
// ohjausrak.alkuluku2.Alkuluku2.java - alkulukutesti while-silmukalla
* <pre name="test">
* pienin_jakaja(25) === 5;
* pienin_jakaja(123) === 3;
* pienin_jakaja(7) === 1;
* </pre>
*/
public static int pienin_jakaja(int luku) {
int jakaja = 3;
if (luku == 2)
return 1;
if (luku % 2 == 0)
return 2;
while (jakaja < luku / 2) {
if (luku % jakaja == 0)
return jakaja;
jakaja += 2;
}
return 1;
}9.8 for -silmukka, tavallisin muoto
Eräs C-kielen hienoimmista rakenteista on for-silmukka. Usein C-hakkereiden tavoite on saada kirjoitettua koko ohjelma yhteen for-silmukkaan. Tätä ei tietenkään tarvitse tavoitella, mutta se osoittaa for-silmukan mahdollisuuksia. Javassa ja C#:issa on vastaava for -silmukka.
Tyypillisesti for-silmukkaa käytetään silloin, kun silmukan kierrosten lukumäärä on ennalta tunnettu:
Tehtävä 9.10 valinSumma
Muuta valinSumma -aliohjelmaa siten, että myös alaraja viedään parametrina. Kirjoita pääohjelma, jolla toiminta voidaan testata.
Käytännössä tällaisia silmukoita ei saa tehdä, koska ongelman ratkaisuun on valmis kaava. Millainen?
9.9 for-each -silmukka
for-silmukan monikäyttöisyydestä huolimatta se on hieman monimutkainen, kun tarkoituksena on vain käydä tietorakenne läpi alkio kerrallaan. Helpompaa onkin usein käyttää for-each-silmukkaa, jonka käyttö kuvataan tarkemmin luvussa Java-kielen taulukoista.
9.10 Java-kielen lauseista
9.10.1 Sijoitusoperaattori =
Olemme tutustuneet jo Java-kielen "normaaliin" sijoitusoperaattoriin =.
Sen ansiosta, että myös sijoitus palauttaa arvon, pystyimme tekemään mm. seuraavia temppuja:
if ( (b=a) != 0 ) ... */* Suoritetaan jos a!=0 */*
a = b = c = 0;Sijoitus monelle muuttujalle yhtä aikaa onnistuu, koska sijoitus jäsentyy seuraavasti:
1. a = ( b = (c = 0) ); - sijoitus c=0 palauttaa arvon 0
2. a = ( b = 0 ); - sijoitus b=0 palauttaa arvon 0
3. a = 0;9.10.2 Sijoitus- ja kasvatusoperaattori +=
valinSumma aliohjelmassa meillä esiintyi myös kaksi uutta sijoitusoperaattoria, jotka ovat lyhenteitä tavallisille sijoituksille:
| lyhenne | tavallinen sijoitus |
|---|---|
| summa += i; | summa = summa + i; |
| i++ | i = i + 1; |
+=sijoituksessa + voidaan korvata millä tahansa operaattoreista:
+ - * / % << >> ^ & |Esimerkiksi luvun kertominen ja jakaminen 10:llä voitaisiin suorittaa:
luku *= 10;
luku /= 10;Siis muuttuja O= operandi voidaan ajatella korvattavaksi seuraavasti:
0. laita sulut operandin ympärille
muuttuja O= (operandi)
1. kirjoita muuttujan nimi kahteen kertaan
muuttuja muuttuja O= (operandi)
2. siirrä = -merkki muuttujien nimien väliin
muuttuja = muuttuja O (operandi)Tehtävä 9.7 +=
Mitä ovat muuttujien arvot seuraavien sijoitusten jälkeen:
int a=10,b=3,c=5;
a %= b;
b *= a+c;
b >>= 2;9.10.3 Lisäysoperaattori ++
Erittäin tyypillisiä C-operaattoreita ovat ++ ja--.
Nämä operaattorit lisäävät tai vähentävät operandin arvoa yhdellä. Operandin tyypin tulee olla numeerinen tai osoitin.
Operandeista on kaksi eri versiota: esilisäys ja jälkilisäys.
| lyhenne | vastaa lauseita |
|---|---|
| a = i++; | a = i; i = i+1; |
| a = i--; | a = i; i = i-1; |
| a = ++i; | i = i+1; a = i; |
| a = --i; | i = i-1; a = i; |
Vaikka C-hakkerit rakentavatkin mitä ihmeellisimpiä kokonaisuuksia ++ -operaattorin avulla, kannattaa operaattorin liikaa käyttöä välttää. Esimerkiksi lauseet, joissa esiintyy samalla kertaa useampia lisäyksiä samalle muuttujalle, saattavat olla jopa määrittelemättömiä:
- ohjausrak.Plusplus.java - esimerkki ei-yksikäsitteisestä ++ operaattorin käytöstä
Ohjelma saattaa Java-kääntäjän toteutuksesta riippuen tulostaa mitä tahansa seuraavista a:n ja i:in kombinaatioista:
a: 0.5 1.0 2.0
i: 2.0 3.0Aluksi ++ -operaattoria kannattaa ehkä käyttää vain yksinäisenä lauseena lisäämään (tai vähentämään) muuttujan arvoa.
i++;Lisäysoperaattoria EI PIDÄ käyttää, jos muuttuja johon lisäysoperaattori kohdistuu, esiintyy samassa lausekkeessa useammin kuin kerran.
Kiellettyjä on siis esimerkiksi:
a = ++i + i*i;
ali(i++,i);9.11 for -silmukka, yleinen muoto
Yleensä ohjelmointikielissä for-silmukka on varattu juuri siihen tarkoitukseen, kuin ensimmäinen esimerkkimmekin; tasan tietyn kierrosmäärän tekemiseen.
Java-kielen for-silmukka on kuitenkin yleisempi:
/* 1. 2. 5. 4. 7. 3. 6. */
for (alustus_lauseet; suoritus_ehto; kasvatus_lauseet) lause;for-silmukka vastaa melkein while-silmukkaa (ero tulee continue-lauseen käyttäytymisessä):
alustus_lauseet; /* 1. */
while ( suoritus_ehto ) { /* 2. 5. */
lause; /* 3. 6. */
kasvatus_lauseet; /* 4. 7. */
}Mikäli esimerkiksi alustuslauseita on useita, erotetaan ne toisistaan pilkulla:
Erittäin C:mäinen tapa tehdä yhteenlasku olisi:
public static int valinSumma3(int i) {
int s;
for (s=0; i >= 0; s += i--);
return s;
}Tämä viimeinen esimerkki on juuri niitä C-hakkereiden suosikkeja, joita ehkä kannattaa osin vältellä.
Tehtävä 9.8 1+2+..+i
Miksi valinSumma3 laskee yhteen luvut 1..i?
9.12 break ja continue
9.12.1 break
Joskus kesken silmukan tulee vastaan tilanne, jossa silmukan suoritus haluttaisiin keskeyttää. Tällöin voidaan käyttää C-kielen break-lausetta, joka katkaisee sisimmän silmukan suorituksen.
// ohjausrak.Break.java - silmukan katkaisu keskeltä
private static void break_testi1() {
int summa=0,luku;
System.out.println("Anna lukuja. Summaan niitä kunnes annat 0 tai summa>20");
do {
luku = Syotto.kysy("Summa on " + summa + ". Anna luku",0);
if ( luku == 0 ) break;
summa += luku;
} while ( summa <= 20 );
System.out.println("Lukujen summa on " + summa);
}Koska 0:lla lisääminen ei muuta summaa, olisi tietenkin do-while -silmukan ehto voitu kirjoittaa muodossa
do {
luku = Syotto.kysy("Summa on " + summa + ". Anna luku",0);
summa += luku;
} while ( luku != 0 && summa <= 20 );mutta aina ei voida break -lausetta korvata näin yksinkertaisesti. Perus break -lauseen vika on lähinnä siinä, ettei siitä suoraan nähdä sisäkkäisten silmukoiden tapauksessa sitä, mihin saakka suoritus katkeaa. Epäselvissä tapauksissa silmukan katkaisu voidaan hoitaa nimeämällä silmukat ja ilmoittamalla break-lauseessa mikä silmukka katkaistaan:
// ohjausrak.Break.java - ulomman silmukan katkaisu keskeltä
private static void breakTesti3() {
int valisumma, loppusumma = 0,luku;
System.out.println("Anna lukuja.");
System.out.println("Summaan niitä kunnes annat 99.");
System.out.println("Antamalla 0, näet välisumman");
System.out.println("Välisumman näet myös jos välisumma > 20");
laskeloppusummaa: do {
valisumma = 0;
do {
luku = Syotto.kysy("Anna luku",0);
if ( luku == 0 ) break;
if ( luku == 99 ) break laskeloppusummaa;
valisumma += luku;
} while ( luku != 0 && valisumma <= 20 );
System.out.println("Lukujen välisumma on " + valisumma);
loppusumma += valisumma;
System.out.println("Kaikkien summa on " + loppusumma);
} while ( loppusumma < 100 );
System.out.println("Lukujen loppusumma on " + loppusumma);
}Silmukka voitaisiin katkaista tietenkin myös muuttamalla silmukan lopetusehtoon vaikuttavia muuttujia. Varsinkin for-lauseen tapauksessa silmukan indeksin arvon muuttaminen muualla kuin kasvatus-lauseessa on todella väkivaltaista ja rumaa, eikä tällaista pidä mennä tekemään.
Hyvin usein aliohjelmassa break voidaan korvata return-lauseella.
Lisäksi näkyviä sisäkkäisiä silmukoita voidaan välttää tekemällä sisäsilmukasta oma aliohjelma:
while ( ulkoehto ) {
while ( sisaehto ) {
hommia();
}
}Eli sisäkkäisten silmukoiden tilalle kirjoitetaan:
void sisahommat() {
while ( sisaehto ) {
hommia();
}
}
...
while ( ulkoehto ) {
sisahommat();
}Tehtävä 9.9 Tarvitaanko sisäkkäisiä silmukoita?
Tarvitaanko aliohjelmassa breakTesti3 todella sisäkkäisiä silmukoita? Esitä ratkaisu jossa on vain yksi silmukka.
9.12.2 continue
Vastaavasti saattaa tulla tilanteita, jolloin itse silmukan suoritusta ei haluta katkaista, mutta menossa oleva kierros halutaan lopettaa. Tällöin continue -lauseella voidaan suoritus siirtää suoraan silmukan loppuun ja näin lopettaa tämän kierroksen suoritus:
// ohjausrak.Continue.java - silmukan lopun ohittaminen
/**
* Esitellään continue-lauseen käyttöä
* @author Vesa Lappalainen
* @version 1.0, 07.02.2003
*/
public class Continue {
public static void main(String[] args) {
int alku= -5, loppu=5,i;
double inv_i;
System.out.println("Tulostan lukujen " + alku + " - " + loppu +
"käänteisluvut");
for (i = alku; i<=loppu; i++ ) {
if ( i == 0 ) continue;
inv_i = 1.0/i;
System.out.println(i + ":n käänteisluku on " + inv_i);
}
}
}Vastaavasti myös continue:n kanssa voi käyttää nimettyä silmukkaa, jos pitääkin siirtyä jatkamaan muuta kuin sisintä silmukkaa.
Tehtävä 9.10 continuen korvaaminen
Kirjoita käänteislukujen tulostusohjelma ilman continue-lausetta.
Tehtävä 9.11 Eri silmukoiden vertailu
Kirjoita lukujen alaraja-yläraja summausfunktio käyttäen
- while -lausetta
- do-while -lausetta
- goto -lausetta
Muista, että alaraja saattaa olla suurempi kuin yläraja, eli summa väliltä [3,0] on 0!
9.13 switch -valintalause
switch -valintalause on selkeä tapa esimerkiksi käyttöliittymäohjelmoinnissa toteuttaa käyttäjän tekemien monivalintojen logiikka, mutta toki se soveltuu moneen muuhunkin asiaan. Valintalausetta voi käyttää primitiivityyppien byte, short, char ja int kanssa, enumeroiduilla tyypeillä, sekä Java SE 7:n jälkeen myös merkkijonoilla.
Käyttöliittymästä käyttäjä pystyy valitsemaan vaihtoehdon, minkä perusteella pystymme tulostamaan ikkunan, jossa näkyy valittu vaihtoehto. Käyttöliittymää tehdessä Swing ympäristössä JRadioButton komponentit saa kytkettyä toisiinsa ButtonGroupin avulla.
// ohjausrak.SwingAanestys.java - esimerkki switch-lauseesta
/**
* Pieni esimerkki äänestys-ohjelmasta switch-lauseen demonstroimiseksi. *
* @author Vesa Lappalainen
* @version 6.2.2011
*/
public class SwingAanestys extends JFrame {
...
private final JLabel lblValitse = new JLabel("Valitse");
private final JRadioButton rb0 = new JRadioButton("Kyll\u00E4");
private final JRadioButton rb1 = new JRadioButton("Ei");
private final JRadioButton rb2 = new JRadioButton("En osaa sanoa");
private final JButton buttonAanesta = new JButton("\u00C4\u00E4nest\u00E4");
private final ButtonGroup groupAanestys = new ButtonGroup();
...
public SwingAanestys() {
...
groupAanestys.add(rb0);
rb0.setHorizontalAlignment(SwingConstants.TRAILING);
rb0.setSelected(true);
rb0.setMnemonic('K');
panelValinta.add(rb0);
groupAanestys.add(rb1);
rb1.setMnemonic('E');
panelValinta.add(rb1);
groupAanestys.add(rb2);
rb2.setMnemonic('O');
panelValinta.add(rb2);
panelAanestys.add(verticalStrut);
buttonAanesta.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent arg0) {
aanesta();
}
});
panelAanestys.add(buttonAanesta);
getRootPane().setDefaultButton(buttonAanesta);
}
/// Omat aliohjelmat
private void aanesta() {
ButtonModel b = groupAanestys.getSelection();
char nappain = (char)b.getMnemonic();
String kohde = "";
switch (nappain) {
case 'K': kohde = "Kyllä"; break;
case 'E': kohde = "Ei"; break;
case 'O': kohde = "En osaa sanoa"; break;
}
JOptionPane.showMessageDialog(null,"Äänestit siis: " + kohde);
}switch -lauseessa case osien lopuksi break on yleensä välttämätön. break estää suorittamasta seuraavia rivejä.
Joskus harvoin breakin puuttumista voidaan käyttää hyväksi, mutta tällöin vaaditaan taitavaa break-käskyn käyttöä.
// ohjausrak.Switch.java - switch, jossa break tahallaan jätetty pois
public static int switch_testi(int x,int operaatio) {
switch (operaatio) {
case 5: /* Operaatio 5 tekee saman kuin 4 */
case 4: x *= 2; break; /* 4 laskee x=2*x */
case 3: x += 2; /* 3 laskee x=x+4 */
case 2: x++; /* 2 laskee x=x+2 */
case 1: x++; break; /* 1 laskee x=x+1 */
default: x=0; break; /* Muut nollaavat x:än */
}
return x;
}Lause default suoritetaan jos mikään case-osista ei ole täsmännyt (tai tietysti jos jokin break puuttuu). default-lauseen ei tarvitse olla viimeisenä, mutta lauseen logiikka pitää silloin olla huolellisesti mietitty.
Yleistä switch-lausetta ei voi korvata joukolla if-lauseita käyttämättä goto-lausetta. Mikäli kuitenkin jokaisen case rakenteen perässä on break, voidaan switch- korvata sisäkkäisillä if-else-rakenteilla.
Tehtävä 9.12 switch -> if
Kirjoita Switch.java ohjelmanpätkä käyttäen if-rakenteita muuttamatta itse suoritettavia lauseita.
Tehtävä 9.13 Päävalinta
Kirjoita paavalinta käyttäen vain if- ja else-rakenteita.
Tehtävä 9.14 lääni, versio 2
Kirjoita laani-aliohjelma käyttäen switch-rakennetta.
9.13.1 | ei toimi switch-lauseessa!
On huomattava, että jos halutaan suorittaa jokin switch-lauseen osista kahdella eri arvolla, EI voida käyttää rakennetta:
switch (operaatio) { /* VÄÄRIN: */
case 4 | 5: x *= 2; break; /* 5 tai 4 laskee x=2*x */ VÄÄRIN
case 3: x += 2; /* 3 laskee x=x+4 */
case 2: x++; /* 2 laskee x=x+2 */
default: x=0; break; /* Muut nollaavat x:än */
}Kääntäjä ei tästä varoita, koska kaikki on aivan kieliopin mukaista. 4 |5 on kahden bittilausekkeen OR eli 5. Siis
case 4 | 8:
on sama kuin
case 12:9.14 Ikuinen silmukka
Usein silmukat lipsahtavat tahattomasti sellaisiksi, ettei niistä koskaan päästä ulos. Ikuisen silmukan huomaa heti esimerkiksi siitä, ettei silmukan rungossa ole yhtään lausetta joka muuttaa silmukan ehdon totuusarvoa.
Joskus kuitenkin Java-kielessä tehdään tarkoituksella "ikuisia" -silmukoita:
for (;;) {
...
if (lopetus_ehto) break;
...
}
while ( true ) {
...
if (lopetus_ehto) break;
...
}
do {
...
if (lopetus_ehto) break;
...
} while ( true );Näissä kahdessa ensimmäisessä korostuu silmukan ikuisuus. Viimeinen ei ole hyvä vaihtoehto.
Tällaiset ikuiset silmukat ovat hyväksyttävissä silloin, kun silmukan lopetusehto on luonnollisesti keskellä silmukkaa. Usein kuitenkin lauseiden uudelleen järjestelyllä lopetusehto voidaan sijoittaa silmukan alkuun tai loppuun, jolloin tavallinen while- , do-while - tai for -silmukka kelpaa.
9.14.1 Yhteenveto silmukoista
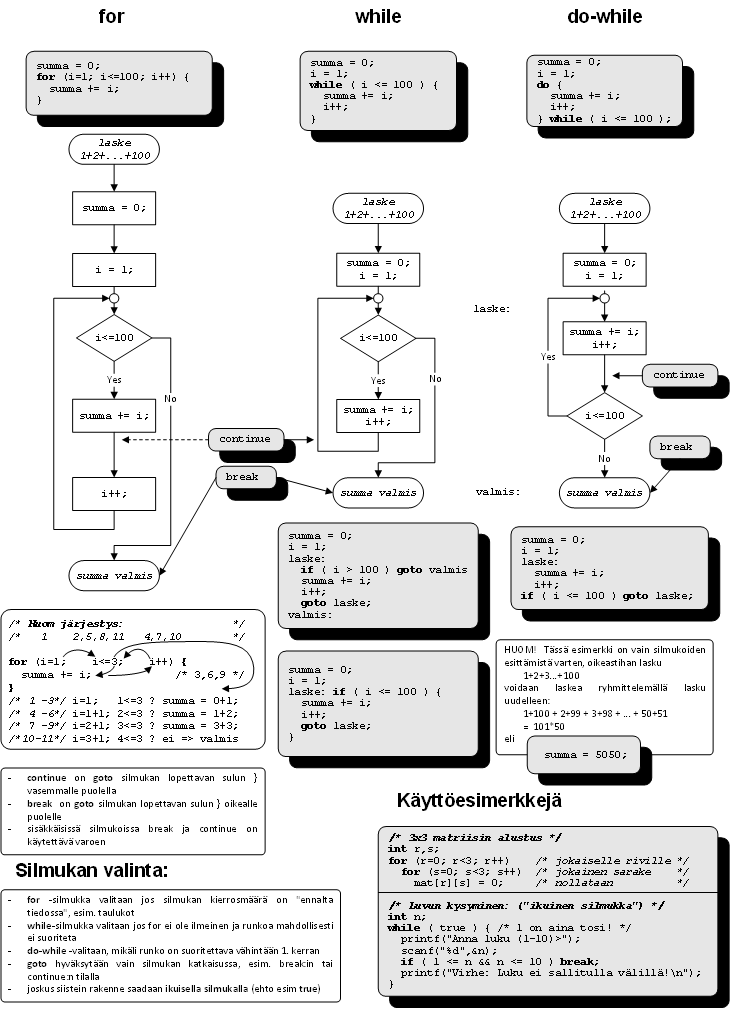
10. Oliosuunnittelu
Kaikki korttiin kirjoittele
palaan pahvin piirrustele
lappuselle laita luokka
taakse tarpeet tarkastele.
Vastuut varmasti valitse
hommat huolella hajoita.
Apulaiset aatteleppa
kelle viestit viskomaksi.
Mitä tässä luvussa käsitellään?
- vaatimukset ohjelman toteutukselle
- olioiden etsiminen
- CRC-kortit
- kuka huolehtii harrastuksista?
10.1 Olio on luokan esiintymä
Ennen kuin voimme aloittaa ohjelman toteutuksen, pitää meidän suunnitella mitä luokkia ohjelmassamme tarvitaan. Ohjelmassa olevat oliot ovat sitten näiden luokkien esiintymiä (ilmentymiä, instance).
10.2 Tavoitteet
Asetamme ensin ohjelman toteutukselle ulkoisen toiminnan lisäksi tiettyjä lisätavoitteita:
- käyttöliittymä (tekstipohjainen vai ikkunoitu) on voitava muuttaa kohtuullisella ohjelmoinnilla
- ohjelma on voitava pienillä muutoksilla muuttaa muuksikin kuin jäsenrekisteriksi (puhelinluettelo, levyrekisteri)
- jäseneen voitava helposti lisätä kenttiä
10.3 Luokat
Tavoitteiden aikaansaamiseksi näyttäisi, että tarvitsemme ohjelmassa ainakin seuraavat kolme luokkaa:
- käyttöliittymää ylläpitävä luokka (Naytto)
- rekisteriä ylläpitävä luokka (Kerho)
- yksittäinen jäsen (Jasen)
Kullekin luokalle täytyy antaa selvät vastuualueet ja tieto siitä, miten kommunikoidaan muiden luokkien kanssa ja minkä luokan kanssa yleensäkään tarvitsee kommunikoida.
10.4 CRC-kortit
Timothy A. Budd [B] ehdottaa luokkasuunnittelun avuksi CRC-kortteja (Class Responsibility Collaborator, luokan vastuu ja avustajat). Kortti on 4"x6" (10 x15 cm) kooltaan ja se jaetaan 3 osaan: luokan nimi, vastuu (eli tehtävät) ja avustajat. Kortin koko on perusteltu sillä, että se on riittävän iso, jotta luokan vastuualueet voidaan siihen kirjoittaa ja toisaalta jos vastuualueet eivät mahdu korttiin, on luokka liian iso ja se pitää jakaa useammaksi osaluokaksi. Huomattakoon, että luokkaa suunniteltaessa ei juurikaan oteta kantaa siihen, kuka luokkaa käyttää!
Korttien takapuolelle voidaan kirjoittaa luokan yksityiset tiedot, eli ne tiedot joita joudutaan käyttämään, jotta luokka voi hoitaa sovitun vastuunsa.
CRC-kortteja on sitten tarkoitus tutkia työryhmän jäsenten kesken. Kortti annetaan aina yhdelle ryhmän jäsenelle. Kortin saaja voi tarkistaa, saako hän korttia vastaavasta luokasta tarvitsemansa tiedot kääntämättä korttia. Jollei saa, luokkia on vielä helppo muuttaa kun ohjelmaa ei ole kirjoitettu.
10.4.1 Jäsen-luokka (Jasen)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Jasen | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | |
| | |
| (- ei tiedä kerhosta, eikä | |
| käyttöliittymästä) | |
| | |
| - tietää jäsenen kentät (nimi, hetu, | |
| puhnro, jne.) | |
| | |
| - osaa tarkistaa tietyn kentän | |
| oikeellisuuden (syntaksin) | |
| | |
| - osaa muuttaa |Ankka Aku|..| - | |
| merkkijonon jäsenen tiedoiksi | |
| | |
| - osaa antaa merkkijonona i:n kentän | |
| tiedot | |
| | |
| - osaa laittaa merkkijonon i:neksi | |
| kentäksi | |
| | |
| | |
+--------------------------------------+--------------------------------------+10.4.2 Kerho-luokka, yksinkertainen (Kerho)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Kerho | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | - Jasen |
| | |
| - pitää yllä varsinaista rekisteriä, | |
| eli osaa lisätä ja poistaa jäsenen | |
| | |
| - lukee ja kirjoittaa kerhon | |
| tiedostoon | |
| | |
| - osaa etsiä ja lajitella | |
| | |
| | |
| | |
| | |
+--------------------------------------+--------------------------------------+10.4.3 Käyttöliittymä-luokka (Naytto)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Naytto | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | - Jasen |
| | |
| - hoitaa kaiken näyttöön tulevan | - Kerho |
| tekstin | |
| | |
| - hoitaa kaiken tiedon pyytämisen | |
| käyttäjältä | |
| | |
| (- ei tiedä kerhon eikä jäsenen | |
| yksityiskohtia) | |
| | |
| | |
| | |
| | |
| | |
| | |
+--------------------------------------+--------------------------------------+10.4.4 Luokkajaon tarkastelua
Miksi näyttö ei saa tietää jäsenen yksityiskohtia? Jos näyttö tietäisi jäsenen yksityiskohdat, pitäisi myös Naytto-luokkaa muuttaa kun muutetaan jotakin jäsenen yksityiskohtaa, eli esimerkiksi lisätään fax-numero. Käytännössä näytön pitää kuitenkin saada tämä muutos tietoonsa. Miten?
Näyttö voi esimerkiksi aina kysyä jäseneltä, montako kenttää tällä on. Samoin näyttö voi pyytää jäsentä antamaan 1. kentän (nimi) merkkijonona, 2. kentän merkkijonona jne. Näin voidaan tulostaa jäsenen tiedot näyttöön tietämättä tarkkaan, mitä kenttiä jäsenessä on.
Entä tietojen lukeminen? Näyttö voi myös kysyä jäseneltä sen tekstin, joka täytyy käyttäjälle kirjoittaa, kun pyydetään käyttäjää antamaan 3. kentän tiedot ("Katuosoite"). Tämän jälkeen näyttö voi tulostaa tämän tekstin näyttöön ja jäädä odottamaan käyttäjältä merkkijonoa. Kun käyttäjä antaa merkkijonon, pyydetään jäsentä muuttamaan annettu merkkijono 3:nen kentän tiedoiksi.
Aikanaan saattaa tulla vastaan tilanne, jossa on edullista jakaa näyttöluokka useampaan alaluokkaan, eli esim. yleinen näyttö (Naytto), kerhon näyttö (KerhonNaytto) ja jäsenen näyttö (JasenenNaytto).
Lisäksi yksittäisten kenttien käsittelyä voi auttaa kenttä-luokan käyttö. Peruskenttäluokasta voidaan periä erikoistuneita kenttäluokkia. Tiedon säilyttämisen apuna kerholuokalla voi olla tietorakenne-luokka. Etsiminen voidaan ehkä jättää etsimis- ja selailu -luokan tehtäväksi. Alkuun päästään kuitenkin suunnitelman mukaisella kolmella luokalla.
10.5 Harrastukset mukaan kortteihin
Entä sitten kun haluamme lisätä kerholaisille harrastuksia. Ainakin tarvitaan Harrastus-luokka lisää. Kuka huolehtii harrastuksista?
Jos valinta tehdään valitun tiedostomuodon mukaan, niin mahdollisuuksia on:
10.5.1 "Oliomalli"
Oletetaan aluksi, että Jäsen huolehtii harrastuksistaan. Tällöin Kerho ei tarvitse mitään muutoksia ja Näyttökin vain sen verran, että tietää kysellä ja tulostaa Jäsenelle tulleita lisäominaisuuksia. Jäsenen ominaisuuksiin lisätään harrastuksien ylläpito vastaavasti kuin Kerho ylläpiti jäsenistöä.
10.5.2 Relaatiomalli kortteihin
Jos valitaan relaatiomallin mukainen tiedostorakenne, niin ehkä myös luokat kannattaa suunnitella vastaavasti. Tässä mallissa Jäsen ei tiedä mitään harrastuksistaan ja Jasen pysyykin muuttumattomana. Harrastus tekee täsmälleen samat asiat kuin Jasen, paitsi tietenkin omille ominaisuuksilleen.
Jos mahdollisimman paljon vastuuta harrastusten ylläpidosta annetaan Kerholle, huomataan että toistetaan samat ominaisuudet, joita kirjoitettiin jo jäsenistöä varten. Tämän vuoksi Kerhon roolia kannattaakin hieman selventää siten, että tietorakenteiden ylläpitoa varten tehdään omat luokat, ja Kerho komentaa näitä luokkia.
10.5.3 Harrastus-luokka (Harrastus)
Vertaa toimintaa Jasen-luokan toimintoihin.
10.5.4 Kerho-luokka (Kerho)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Kerho | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | - Jasenet |
| | |
| - huolehtii Jasenet ja | - Harrastukset |
| Harrastukset -luokkien välisestä | |
| yhteistyöstä ja välittää näitä | - Jasen |
| tietoja pyydettäessä | |
| | - Harrastus |
| - lukee ja kirjoittaa kerhon | |
| tiedostoon pyytämällä apua | |
| avustajiltaan | |
| | |
| | |
| | |
| | |
+--------------------------------------+--------------------------------------+10.5.5 Jäsenet-luokka (Jasenet)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Jasenet | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | - Jasen |
| | |
| - pitää yllä varsinaista | |
| jäsenrekisteriä, eli osaa lisätä ja | |
| poistaa jäsenen | |
| | |
| - lukee ja kirjoittaa jäsenistön | |
| tiedostoon | |
| | |
| - osaa etsiä ja lajitella | |
| | |
| | |
| | |
| | |
+--------------------------------------+--------------------------------------+10.5.6 Harrastukset-luokka (Harrastukset)
+--------------------------------------+--------------------------------------+
| Luokan nimi:Harrastukset | Avustajat: |
+--------------------------------------+--------------------------------------+
| Vastuualueet: | - Harrastus |
| | |
| - pitää yllä varsinaista | |
| harrasterekisteriä, eli osaa lisätä | |
| ja poistaa harrastuksen | |
| | |
| - lukee ja kirjoittaa harrastukset | |
| tiedostoon | |
| | |
| - osaa etsiä ja lajitella | |
| | |
| | |
| | |
| | |
+--------------------------------------+--------------------------------------+Koska Harrastukset ja Jäsenet ovat täsmälleen samanlaisia lukuun ottamatta sitä, mitä alkioita ne käsittelevät, voidaan käytännössä Javalla ensin tehdä kantaluokka, josta peritään kumpikin hieman eri versio.
Näin päästään siihen tilanteeseen, jossa myös rinnakkaisten rakenteiden lisääminen Harrastuksille vaatii vain hyvin vähän uutta ohjelmointia.
Huomattakoon, että sekä Jasenet että Harrastukset ovat pelkkiä abstrakteja tietorakenneluokkia, niiden sisäinen tallennustapa voi olla mikä vaan (taulukko, lista, puu) ulkoisen rajapinnan ollessa silti edellisen suunnitelman kaltainen.
11. Jäsenrekisterin runko
Taulukkoko pienen pieni
vaiko lista suuren suuri
joku muuko miettimäksi
rakenne kerhoon katsomaksi.
Kuva tuosta piirtämäksi
tästä temput tutkimaksi
siitä selväksi sävelet
kohtapa jo koodamaksi.
Mitä tässä luvussa käsitellään?
- tietorakenteen valinta
11.1 Runko ilman kommentteja
Emme vielä täysin osaa tehdä edes runkoa jäsenrekisteriohjelmaamme, mutta esitämme tästä huolimatta jonkinlaisen toimivan rungon ohjelmalistauksen. Koodissa tulee lukuisia vielä käsittelemättömiä osia, joita käsittelemme tarkemmin myöhemmin. Samoin etsimme myöhemmin sopivan tavan kommentoida aliohjelmia.
Rungon tarkoituksena on tarjota näkyväksi ne toiminnot, jotka ohjelman suunnitelmassa päätettiin tehdä. Samoin tavoitteena on testata valitun tietorakenteen toimivuus. Jatkossa toimintoja lisätään tähän runkoon.
Tämä runko ei tietenkään ole syntynyt kerralla, vaan ensin on testattu tietorakenteet yksittäin ja sitten lisätty näiden käyttö valmiiseen menu-runkoon.
11.2 Valittava tietorakenne
Minkälaisen tietotyypin voisimme valita? Vaihtoehtoja tulee ehkä lähes yhtä paljon kuin ohjelmoijiakin on. Voimme kuitenkin vertailla eräiden rakenteiden etuja ja haittoja. Jos mahdollista, tietorakenteiden tulisi olla yhtenäinen tehdyn oliosuunnitelman kanssa. Seuraavista ehdotuksista mikään ei ole ristiriidassa edellisessä luvussa tehdyn oliosuunnitelman kanssa. Vasta kun valitaan harrastusten tallennustapaa, joudumme valinnan eteen.
Lähdemme siitä ajatuksesta, että koko käsiteltävä aineisto on kerralla keskusmuistissa. Voisimme tietenkin operoida myös suoraan levylle, mutta oppimisen tässä vaiheessa voi seuraava ratkaisu olla helpompi:
lue tiedosto muistiin
käsittele aineistoa muistissa
tallenna aineisto takaisin levylle11.2.1 Taulukko
Taulukko on kiinteä tietorakenne, jota luotaessa täytyy jo tietää monelleko ihmiselle varaamme tilaa. Tässä tulee äkkiä varattua tilaa joko liikaa, jolloin tila ei riitä muille toiminnoille, tai liian vähän, jolloin kaikki henkilöt eivät mahdu rekisteriin. Esimerkissämme olemme varanneet n. 300 tavua/henkilö. Tilan varaaminen sadalle henkilölle veisi jo 30000 tavua. Usein sata ei edes riitä!

Javassa asia ei tietysti ole ihan näin suoraviivaista. Javassahan oliot ovat vaan viitteitä, jolloin oliotaulukko onkin vain taulukollinen viitteitä. Näin "liian tilan varaaminen" ei ole kovin kohtalokasta, jos jokainen viite vie esim. 4 tavua, niin 100 hengen viitteet vievät 400 tavua. Edes tuhannen hengen viitteet eivät vie mitenkään katastrofaalisesti tilaa:

Kuitenkin ohjelmoijan omalle vastuulle jää taulukon maksimikoon ja taulukon "käytettyjen" alkioiden lukumäärän ylläpitäminen. Maksimikokohan saadaan aina taulukon koosta, joten tämä ei ole Javassa kovin suuri vaiva. Käytettyjen alkioiden määrän ylläpitoon täytyy kuitenkin rakentaa jokin mekanismi.
Javassa on tarjota valmiitakin tietorakenteita, mutta niiden pienenä puutteena on se, että ne tallentavat vain olioita. Vanhassa Javassa tämä oli toteutettu niin, että aina tallennettiin Object-tyyppiä ja sitten konvertoitiin itse get-metodin jälkeen oikeaan tyyppiin. Nykyisin tämä hoidetaan geneerisillä tietorakenteilla.
Taulukon hyvä puoli on että sinne voidaan tallentaa myös aitoja perustietotyyppejä. Jos perustietotyyppejä tallennetaan muihin tietorakenteisiin, ne "boksataan" (autoboxing) perustietotyyppiä vastaavan olion sisälle ja tämä aiheuttaa teho-ongelmia joissakin tilanteissa.
11.2.2 Linkitetty lista
Linkitetty lista on rakenne, jossa meillä on tieto vain listan 1. alkiosta. Tämän jälkeen kukin alkio tietää itseään seuraavan alkion, kunnes listan viimeinen alkio ei enää osoita minnekään.
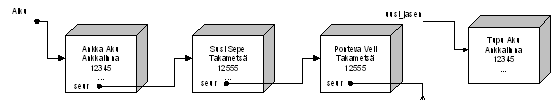
Listan hyvänä puolena on se, ettei etukäteen tarvita mitään tietoa alkioiden lukumäärästä. Alkioita voidaan lisätä listaan joko alkuun, keskelle tai loppuun niin kauan kuin muistia riittää.
Mikäli rakennamme ohjelman huolella, ei tietorakenteen vaihtaminen jälkeen päinkään ole mahdoton tehtävä. Tätä auttaa vielä aikaisemmin tekemämme valinta käyttää abstraktia rajapintaa (lisää, poista, etsi) tietorakenneluokan (Kerho tai Jasenet) ja käyttöliittymän (Naytto) välillä.
11.2.3 Sekarakenne
Valitsemme tähän esimerkkitoteutukseen tietorakenteeksi sekarakenteen:
Siis perusrakenteena meillä on Kerho-tyyppi, joka pitää sisällään kerhon perustiedot. Kerhosta on osoitin taulukkoon, jossa on osoittimet varsinaisiin henkilöiden tietoihin (Jasen).
Henkilöiden tiedoille varattua tilaa ei ole olemassa ennen kuin sitä tarvitaan. Siis varataan kullekin kerhoon lisättävälle henkilölle hänen tiedoilleen tarvittava uusi n. 300 tavun "möykky" lisäyksen yhteydessä.
Osoitintaulukkoon sijoitetaan sitten vastaavaan paikkaan sen muistiosoitteen arvo, josta henkilölle tarvittava tila saatiin varattua.
Tässäkin rakenteessa on se huono puoli, että osoitintaulukon koko pitää päättää ennen kuin sinne voidaan sijoittaa osoitteita. Yksi osoite vie kuitenkin enimmilläänkin tilaa 4 tavua, joten kiinteää tilan varausta esim. 1000 henkilön taulukossa tulee vain 4000 tavua.
Hyvinä puolina rakenteessa on sen suhteellisen helppo käsittely sekä lisäyksen, poiston että lajittelun tapauksessa.
 |
|
Tehtävä 11.1 Lisäys
Kirjoita algoritmi henkilön lisäämiseksi rakenteeseen.
Tehtävä 11.2 Etsiminen
Kirjoita algoritmi tietyn henkilön etsimiseksi (vaikkapa nimellä).
Tehtävä 11.3 Poisto
Kirjoita algoritmi löydetyn henkilön (miten löytö kannattaa säilyttää?) poistamiseksi rakenteesta.
Tehtävä 11.4 Lajittelu
Kirjoita algoritmi rakenteen lajittelemiseksi aakkosjärjestykseen. Mitä lajittelussa kannattaa vaihdella?
11.3 Harrastukset mukaan
Jos halutaan tallentaa myös kullekin jäsenelle vaihteleva määrä harrastuksia, on jälleen mahdollisuuksia useita. Tietorakennetta valittaessa voidaan käyttää samaa kriteeriä kuin tiedostoakin valittaessa. Välttämätöntä tämä ei kuitenkaan ole, vaan voidaan sisäisesti tietysti käyttää myös erilaista rakennetta kuin ulkoisesti.
11.3.1 Tiedot jäsenen yhteyteen
Jos tiedoston muoto on sellainen että harrastukset on lueteltu jäsenen tietojen yhteydessä, kannattaa tietorakennekin valita vastaavasti.
Ankka Aku |010245-123U|Paratiisitie 13 |12345 |ANKKALINNA |12-12324 | |
- kalastus | 1955 | 20
- laiskottelu | 1950 | 20
- työn pakoilu | 1952 | 40
Susi Sepe |020347-123T| |12555 |Takametsä | | |
- possujen jahtaaminen | 1954 | 20
- kelmien kerho | 1962 | 2
Ponteva Veli |030455-3333| |12555 |Takametsä | | |
- susiansojen rakentaminen | 1956 | 15Nyt tietorakenne voisi olla tilanteesta riippuen mikä tahansa edellä esitetyistä siten, että kerhosta alkava rakenne toistuu jäsenen kohdalla.
Esimerkiksi linkitetty lista:
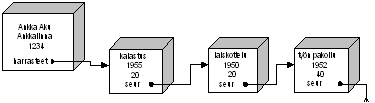
11.3.2 Relaatiomalli tietorakenteeseen
Jos tiedot on tallennettu relaatiomallin mukaan, voi olla kannattavaa tehdä myös sisäinen tietorakenne vastaavaksi. Vaikka jatkossa emme toteutakaan kerhoon vielä harrastuksia, teemme tietorakenteen ja oliot sellaisiksi, että harrastusten käsittely jälkeenpäin olisi mahdollisimman helppoa.
Toteutettavaa ohjelmaa ajatellen tästä valinnasta seuraa yksi byrokratiaporras (Kerho <-> Jasenet) lisää, joka aluksi saattaa tuntua turhalta. Valinta maksaa itseään takaisin vasta ongelman monimutkaistuessa. Tähän samaan monimutkaistumisongelmaan tulemme törmäämään jatkossakin. Yksinkertaisin mahdollisuus, jolla vaadittu toimenpide juuri ja juuri voidaan suorittaa, johtaa usein jatkoa ajatellen umpikujaan.
Tehtävä 11.5 Lisää harrastus
Kirjoita algoritmi uuden harrastuksen lisäämiseksi. (Ks. alla oleva kuva)
Tehtävä 11.6 Mitä harrastaa
Kirjoita algoritmi, joka vastaa kysymykseen "Mitä henkilö N harrastaa?"
Tehtävä 11.7 Kuka harrastaa
Kirjoita algoritmi, joka vastaa kysymykseen: "Ketkä harrastavat harrastusta H?".
Tehtävä 11.8 Poista harrastus
Kirjoita algoritmi harrastuksen poistamiseksi.
Tehtävä 11.9 Jäsenen poistaminen
Kirjoita algoritmi, joka poistaa jäsenen jonka nimi on N.
Tehtävä 11.10 "Roskaharrastukset"
Kirjoita algoritmi, joka poistaa "roskaharrastukset", eli ne harrastukset, joille ei löydy "omistajaa". Tällaiseen tilanteeseen hyvässä ohjelmassa ei tietenkään koskaan päädytä.
Tehtävä 11.11 Monta saman lajin harrastajaa
Jos harrastusten nimet ovat kovin pitkiä ja harrastuksista tallennetaan vielä kuhunkin harrastukseen liittyvää lisätietoa, niin edellä mainittu rakenne käy tehottomaksi heti kun löytyy useita saman lajin harrastajia. Esitä ratkaisu, jossa hukkatilaa (mm. saman harrastuksen nimen toistamista) ei esiinny, mutta jolla voidaan tehdä kaikki samat tehtävät, kuin esitetyllä ratkaisulla.
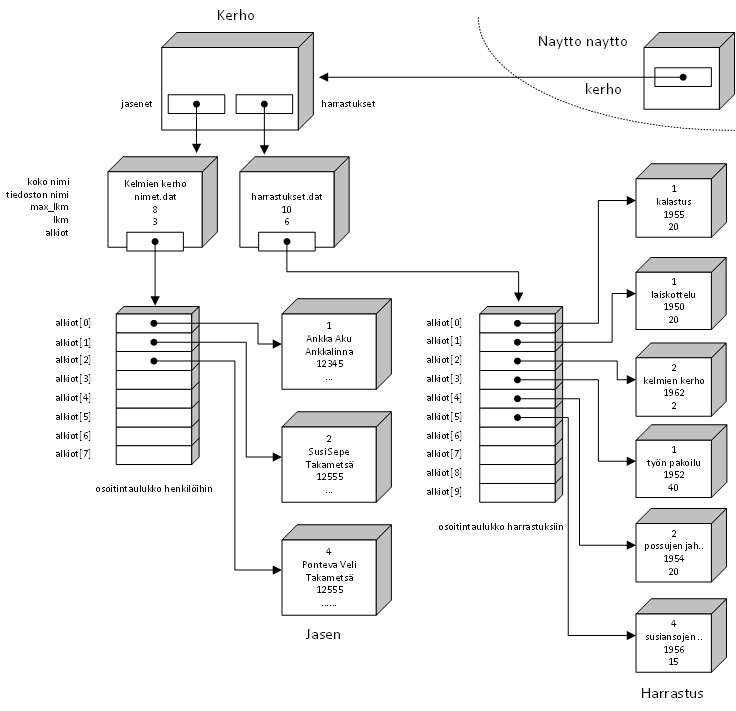
12. Java-kielen taulukoista
Taulukko se taasen tuttu
oiva säilö alkioille
maja muuttujalle monelle
silmäiltäväksi silmukalla.
Mitä tässä luvussa käsitellään?
- Java-kielen taulukot
- taulukoiden ja viitteiden yhteys
- moniulotteiset taulukot
Syntaksi:
Taulukon esittely: alkiontyyppi taulukonnimi[];
alkiontyyppi[] taulukonnimi;
Taulukon luominen: taulukonnimi = new alkiontyyppi[koko_alkioina]
Alkioon viittaaminen: taulukonnimi[alkion_indeksi]
Muista 1. indeksi = 0
viimeinen = koko_alkiona-1
Silmukoissa for (int i=0; i<taulukonnimi.length; i++) ...
for (alkiontyyppi alkio: taulukonnimi) ...
2-ul.taulukon es: alkiontyyppi taulukonnimi[][];
2-ul taul. luominen: taulukonnimi = new alkiontyyppi[riveja][sarakkeita]Luvun esimerkkikoodit:
12.1 Yksiulotteiset taulukot
C-kielessä taulukoita ei oikeastaan ole, tai ainakin ne ovat '2. luokan kansalaisia'. Lausuma tarkoittaa sitä, että taulukoista on käytettävissä vain 1. alkion osoite, ja esimerkiksi taulukon sisällön sijoittaminen toiseen taulukkoon ei onnistu sijoitusoperaattorilla. Lisäksi taulukon rajoissa pysymiselle ei ole minkäänlaista valvontaa.
Javassa onneksi taulukot on tehty hieman paremmin. Erityisesti kriittisistä rajojen ylityksistä tulee poikkeus.
12.1.1 Taulukon määrittely
Taulukko määritellään kertomalla taulukon alkioiden tyyppi ja luomalla sitten varsinainen taulukko:
Tällöin taulukon 1. alkion indeksi on 0 ja 12. alkion indeksi on 11.
Määrittelyllä muuttujasta kPituudet tulee osoitin kokonaislukuun; taulukon alkuun.
12.1.2 Taulukon alkioihin viittaaminen indeksillä
Taulukon alkioon voidaan viitata alkion indeksin avulla

Kuvassa viitataan paikkaan kPituudet[2] eli 2 paikkaa eteenpäin taulukon alusta lukien.
Taulukon rajojen ylityksestä seuraa IndexOutOfBoundsException-poikkeus
Joskus taulukon paikkoja vastaaville indekseille kannattaa antaa niitä selkeyttävät nimet:
12.1.3 Taulukon läpikäyminen for ja for-each -silmukoilla
Yksi tapa käydä läpi taulukon alkiot on indeksin käyttöön perustuva for-silmukka. Seuraavassa esimerkissä lasketaan taulukon kPituudet summa for-silmukalla.
On tärkeää huomata, että taulukoiden käsittelyssä indeksi liikkuu välillä [0,YLÄRAJA[.
Sama silmukka voitaisiin kirjoittaa niin, että taulukon alkio otetaan apumuuttujaan. Itse asiassa usein näin kannattaakin tehdä, mikäli silmukan kierroksella tarvitaan samaa alkiota useammin. Jokainen alkion taulukosta ottaminen suorittaa nimittäin indeksin järkevyystarkituksen ja apumuuttujan avulla tämä saadaan vain yhteen kohtaan.
Koska edellä oleva tapa käyttää taulukkoa (tai mitä tietorakennetta tahansa) on erittäinen yleinen, on kieliin lisätty foreach -silmukka, joka on lyhenne yllä olevalle koodille. Javassa foreach-silmukan muoto on:
eli edellä oleva koodi foreach-silmukalla olisi:
12.1.4 Taulukon alustaminen
Taulukko voidaan alustaa (vain) esittelyn yhteydessä:
Toki tarvittaessa voidaan luoda uusi taulukko, joka sijoitetaan viitteeseen:
Itse asiassa yllä olevaa muotoa käytetään hyvin usein esimerkiksi testeissä, jotta saadaan pienellä kirjoittamisella testattavia taulukoita. Esimerkkejä tästä on mm. alla olevissa tehtävissä.
12.1.5 Hakasulkujen paikka
Javassa hakasulut voivat esittelyssä olla kummalla puolella vaan taulukon nimeä. Erona on lähinnä se, että jos ne ovat nimen etupuolella, tulee saman esittelyn kaikista muistakin muuttujista taulukoita. Vastaavasti nimen jäljessä vain siitä muuttujasta tulee taulukko. Siksi jos hakasulkuja käyttää muuttujan nimen edessä, kannattaa ne laittaa selkeyden vuoksi kiinni taulukon tyyppiin.
12.1.6 Taulukoiden testaaminen
Mikäli testattava funktio tuottaa taulukoita tai muuttaa olemassa olevaa taulukkoa, niin tällaisia tapauksia on helpointa testata Arrays.toString -metodilla:
Yllä oleva esimerkki on hyvä esimerkki siitä, miksi muuten ehkä void aliohjelma kannattaakin kirjoittaa testaamisen helpottamiseksi (vrt. TDD) funktioksi, joka palauttaa viitteen samaan olioon, jota funktio muutti. Toisaalta samaa ideaa käytetään usein myös ketjuttamisen helpotamiseksi (vrt. StringBuider-luokan metodit).
Koska edellä tulee jo varsin paljon kirjoittamista, on ComTestissä myös mahdollisuus taulukkomaiseen testaamiseen ja makrojen käyttöön. ComTestin makrot toimivat siten, että ensin kirjoitetaan jokaiselle testitaulukkoon tulevalle riville "ohje", joka on normaali Java-lause (tai useita lauseita), jossa testirivillä muuttuvat asiat on merkitty $-alkuisella makrolla. Sitten kirjoitetaan taulukko, jossa annetaan kullakin rivillä makroille täydennettävät arvot. Eli esimerkiksi edellinen testi voitaisiin (viimeistä testiä lukuunottamatta) kirjoittaa seuraavasti:
Mikäli viimeinenkin testi haluttaisiin mukaan, voisi testin muoto olla:
12.1.7 Oliotaulukot
Taulukot voivat yhtä hyvin sisältää myös oliota, esimerkiksi:
Aika[] ajat = new Aika[5];Edellä luodussa taulukossa on paikka viidelle Aika-tyypin oliolle, mutta jokainen viidesta olioviitteestä on null-viite.
Vastaavasti taulukkoon voidaan sijoittaa uusia olioita olemassa olevista tai luoda uusia olioita:
Aika luento = new Aika(12,15);
ajat[0] = luento;
ajat[1] = new Aika(14,35);Edellisten sijoitusten jälkeen on edelleen kolme null -viitettä taulukossa.
Jos oliotaulukon haluaa alustaa jo esittelyn yhteydessä, tehdään tämä vastaavasti kuin tavallisissakin taulukoissa:
Aika[] ajat = {new Aika(12,15), new Aika(14,35), new Aika(17,30) };12.2 Merkkijonot
Merkkijonot ovat eräs ohjelmoinnin tärkeimmistä tietorakanteista. Valitettavasti tämä on lähes poikkeuksetta unohtunut ohjelmointikielten tekijöiltä. Heille riittää että kielellä VOI tehdä merkkijonotyypin. Tavallista käyttäjää kiinnostaa tietysti onko se tehty ja onko se hyvä. Usein vastaus on EI. Näin myös C-kielen kohdalla! C++:han on jo välttävä merkkijonoluokka. Javassa on kaksi merkkijonoluokkaa String ja StringBuilder (tai StringBuffer).
12.2.1 Merkkityyppi
Yksittäinen merkki on Java-kielessä tyyppiä char. Kirjainvakio laitetaan yksinkertaisiin heittomerkkeihin:
Merkkimuuttujiin voidaan vallan hyvin sijoittaa myös merkin koodiarvo
Lukuarvo tarkoittaa merkin (Unicode-) koodia.
Merkkejä käsitellään esimerkiksi Character-luokan staattisilla funktiolla:
12.2.2 String
Javan String-luokka tarjoaa muuttumattoman merkkijonon (immutable). Merkkijonon "sisältö" voidaan vaihtaa vain luomalla uusi merkkijono. Eli käytännössä silloin merkkijonoviite käännetään uuteen paikkaan. Tässä tekniikassa on se hyvä puoli, että vaikka olisi useita viitteitä samaan merkkijonoon, jokainen voi olla varma, ettei itse jono pääse muuttumaan.
Merkkijono "vakioarvot" sijoitetaan kaksinkertaisiin lainausmerkkeihin. Merkkijonovakioarvon (jatkossa käytetään termiä merkkijonovakio) käyttäminen luo muistiin uuden merkkijonon. Tosin kääntäjä optimoi koodia usein niin, että jos samaa merkkijonovakiota käyttää useasti, luodaan vain yksi merkkijono. Huomaa, että String-luokan metodit palauttavat aina uuden merkkijonon.
Lue lisää merkkijonometodeista Javan dokumentaatiosta.
12.2.3 StringBuilder ja StringBuffer
Jos halutaan merkkijono, jonka sisältöä voidaan muuttaa (mutable), pitää käyttää StringBuilder- tai StringBuffer-luokkaa. Nämä luokat ovat ulospäin identtiset, mutta vanhempi StringBuffer on hitaampi, toimien toisaalta paremmin rinnakkaisessa käsittelyssä. Nykyisin StringBuilder on suositeltavampi.
Jos merkkkijonoon pitää tehdä paljon lisäyksiä, ei kannata käyttää String-luokan + -operaattoria vaan StringBuilder -luokkaa ja sen append-metodia. Katso mallia dynaamiset taulukot -esimerkin toString-metodista.
12.2.3.1 Varo kun vertaat String ja StringBuilder keskenään!
Kun verrataan String- ja StringBuilder -luokan olioita keskenään, pitää ne muuttaa ensin samaan luokkaan. Yleensä StringBuilder-luokan alkio muutetaan String-tyyppiseksi. Tai jos toinen verrattava on jo String, voidaan käyttää sen contentEquals -metodia.
Harmillista on että edes kahta StringBuilder-oliota ei voi verrata keskenään vaan verrattavat pitää muuttaa ensin String-luokkaan. Nämä asiat pitää muistaa ottaa huomioon myös, kun testaa StringBuilder-luokan olioita.
Lue lisää StringBuilder-metodeista Javan dokumentaatiosta.
12.3 Moniulotteiset taulukot Javassa
Moniulotteiset taulukot ovat Javassa vain yksiulotteisia taulukoita taulukoista.
12.3.1 Kiinteä esittely
Kaikkein helpoin tapa esitellä moniulotteinen taulukko on aivan normaali esittely:

Esittely voisi olla (ja nykyään jopa mieluummin):
ja toimisi jopa
Taulukon nimi on vain viite taulukkoon. Kaksiulotteinen taulukko on vain yksiulotteinen taulukko riveistä. Eli oikeasti kuva on:
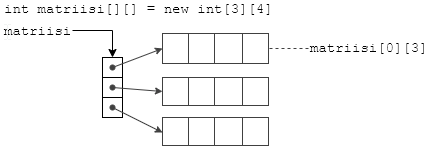
Edellä
matriisi.length == 3
matriisi[1].length == 4Taulukon alkioina voi tietysti olla mikä tahansa olemassa oleva tyyppi. Myös moniulotteinen taulukko voidaan alustaa esittelyn yhteydessä:
double[][] yks = {
{ 1.0, 0.0, 0.0 },
{ 0.0, 1.0, 0.0 },
{ 0.0, 0.0, 1.0 }
}
Tehtävä 12.2 Matriisit
Kirjoita seuraavat aliohjelmat, jotka saavat parametrinaan 2 nxn matriisia ja palauttavat nxn matriisin:
- Laskee yhteen 2 matriisia.
- Kertoo kaksi matriisia keskenään. (Kirjoita avuksi funktio, joka kertoo matriisin rivin i toisen matriisin sarakkeella j).
12.3.2 Yksiulotteisen taulukon käyttäminen moniulotteisena
Toisaalta moniulotteinenkin taulukko voidaan toteuttaa 1-ulotteisena. Tästä muunnoksestahan puhuttiin jo monisteen alkuosassa. On makuasia, kumpi järjestys esimerkiksi matriisissa valitaan: sarakelista vaiko rivilista. Rivilista on C-kielen mukainen, mutta toisaalta maailma on pullollaan Fortran aliohjelmia, joissa matriisit on tallennettu sarakelistana. Siis kumpikin tapa on syytä hallita.
12.3.2.1 Tehtävä 12.3 Matriisi 1-ulotteisena
Kirjoita aliohjelma teeYksikko, jolle tuodaan parametrina neliömatriisin rivien lukumäärä ja 1-ulotteisen taulukon viite, ja joka alustaa tämän neliömatriisin yksikkömatriisiksi.
12.3.3 Taulukko taulukoista
Javassahan moniulotteinen taulukko on siis taulukko taulukoista. C#:issa on myös aito kaksiulotteinen taulukko, toki myös taulukko taulukoista.
- taulukot.Mat2.c - matriisi parametrina riviosoittimen avulla
12.3.4 Taulukkoviitteistä
Se että matriisi onkin vain taulukko viitteistä riveihin, mahdollistaa edellä olleen mielivaltaisen kokoisen matriisin käyttämisen aliohjelman parametrina. Matriisin rivit voidaan luoda myös erikseen:

- taulukot.Mat3.java - matriisi osoitintaulukon avulla
Javan menettelyssä on vielä se etu, ettei kaikkien rivien välttämättä tarvitsisi edes olla yhtä pitkiä. Harvassa matriisissa osa osoittimista voisi olla jopa null-osoittimia, mikäli rivillä ei ole alkioita (aliohjelman pitäisi tietysti tarkistaa tämä). Oikeasti rivit usein vielä luotaisiin dynaamisesti ajon aikana tarvittavan pituisina.
Tehtävä 12.4 Transpoosi
Kirjoita funktio, joka saa parametrinaan matriisin. Funktio palauttaa uuden matriisin joka on parametrina tuodun matriisin transpoosi (eli vaihtaa rivit ja sarakkeet keskenään).
12.4 Komentorivin parametrit (args)
Jos ohjelmalle halutaan toimittaa parametreja käynnistyksen yhteydessä, niin Java-ohjelma saa ne pääohjelman args-taulukossa:
- taulukot.Argv.java - komentorivin parametrit
Kun ohjelma ajetaan komentoriviltä on tulostus seuraavan näköinen.
C:\kurssit\moniste\esim\java-taul>java Argv kissa istuu puussa[RET]
Argumentteja on 3 kappaletta:
0: kissa
1: istuu
2: puussa
C:\kurssit\moniste\esim\java-taul>_
Mikäli halutaan että yhdessä argumentissä on useampi sana, eli argumentti sisältää välilyönnin, pitää argumentti sulkea lainausmerkkeihin.
Tehtävä 12.5 Palindromi
Kirjoita Java-ohjelma Pali, jota kutsutaan komentoriviltä seuraavasti:
C:\OMAT\OHJELMOI\VESA>***java*** Pali kissa[RET]
kissa EI ole palindromi!
C:\OMAT\OHJELMOI\VESA>java Pali saippuakauppias[RET]
saippuakauppias ON palindromi!
C:\OMAT\OHJELMOI\VESA>_13. Dynaaminen muistinkäyttö
Aina ei aavista kokoa
suuruuttapa suuren suurta
dynaamisuus siis avuksi
mielehen muuttuva kokokin.
Varaa muistia tarvittaissa
uutta uikuta muuttujille
viitteen päähän pantavaksi
sieltä sitten saatavaksi.
Listoja ja taulukoita
vinkeitä vipeltimiä
algoritmejä arvokkaita
valmiinakin tarjonnassa.
Mitä tässä luvussa käsitellään?
- Dynaaminen muistinhallinta
- Dynaamiset taulukot
- Muistinsiivous
- Algoritmit
Syntaksi:
Dyn.olion.luonti muuttuja = new Luokka(parametrit)
"Hävittäminen" muuttuja = null;Luvun esimerkkikoodit:
Olemme oppineet varaamaan muuttujia esittelyn yhteydessä. Usein olioita voidaan luoda (= varata muistitilaa) myös ohjelman ajon aikana. Tämä on tarpeellista erityisesti silloin, kun ohjelman kirjoittamisen aikana ei tiedetä muuttujien määrää tai ehkei jopa edes kokoa (taulukot).
13.1 Muistin käyttö
Karkeasti ottaen tavallisen ohjelman muistinkäyttö näyttäisi ajan funktiona seuraavalta:

Edellinen kuva on hieman yksinkertaistettu, koska "oikeasti" aliohjelmien lokaalit muuttujat (automaattiset muuttujat) syntyvät aliohjelmaan tultaessa ja häviävät aliohjelmasta poistuttaessa. Näin ollen käytetyn muistin yläraja vaihtelee sen mukaan, mitä aliohjelmia on kesken suorituksen.
Dynaamisia muuttujia voidaan tarvittaessa luoda ja kun muistitilaa ei enää tarvita, voidaan vastaavat muuttujat vapauttaa:

Näin muistin maksimimäärä saattaa pysyä huomattavasti pienempänä kuin ilman dynaamisia muuttujia. Idea on siis siinä, että muistia varataan aina vain sen verran, kuin sillä hetkellä tarvitaan. Kun muistia ei enää tarvita, vapautetaan muisti.
Ajonaikana luotaviin muuttujiin tarvitaan osoitteet. Nämä osoitteet pitää sitten tallentaa johonkin. Tallennus voitaisiin tehdä esimerkiksi taulukkoon tai sitten alkioista pitää muodostaa linkitetty lista.
13.2 Dynaamisen muistin käyttö Javassa
13.2.1 new
Javassa kaikki oliot luodaan dynaamisesta muistista (keosta).
13.2.2 Olion tuhoaminen
Kun oliota ei enää tarvita, se häviää aikanaan, kun kaikki siihen osoittavat viitteet asetetaan null-arvoon tai poistetaan viitteet kokonaan (poistutaan metodista jolloin lokaalit viitteet katoavat). Tällöin olio muuttuu roskaksi ja muistinsiivous aikanaan tuhoaa kaikki oliot, joihin ei ole viitteitä.
13.2.3 Taulukon luominen new []
Jos new-operaattorilla on luotu taulukollinen olioita niin varsinaiset oliot pitää luoda erikseen.
monta = new Luokka[20];...vielä ei ole varsinaisia alkioita, vain 20 null-viitettä.
13.3 Dynaamiset taulukot
Kerhon jäsenrekisterissä käytettiin osoitintaulukkoa dynaamisesti. Vastaavan rakenteen tarve tulee usein ohjelmoinnissa. Tällöin tulee aina vastaan ongelma: montako alkiota taulukossa on nyt? Jäsenrekisterissä tämä oli ratkaistu Jasenet-luokassa tekemällä sinne kentät, joista nämä rajat selviävät.
Javassa edellä mainittu dynaaminen taulukko voidaan toteuttaa käyttäjän kannalta todella joustavaksi:
- dynaaminen.Taulukko.java -esimerkki dynaamisesta taulukosta
13.3.1 Poikkeukset
Ohjelmoidessa joutuu usein varautumaan jo ennalta mahdollisiin virhetilanteisiin. Ohjelmistoa kirjoitetaan kuitenkin monella tasolla, eikä poikkeustilanteiden käsittely usein edes kuulu matalan tason komponenteille. Javassa hyvä apu ongelmaan on poikkeustenhallinta (exception handling).
Ideana on, että virheen sattuessa mistä kohtaa tahansa ohjelmakoodia voi heittää poikkeuksen. Poikkeuksen heittäminen kerrotaan metodin esittelyn yhteydessä throws-apusanalla, jotta sen toiminnallisuutta käyttävä ohjelman osa tietää varautua siihen.
public void lisaa(int i) throws TaulukkoTaysiException {
if ( lkm >= alkiot.length )
throw new TaulukkoTaysiException("Tila loppu");
alkiot[lkm++] = i;
}Javassa on kahdenlaisia poikkeuksia. Tarkistettuja poikkeuksia, jotka periytyvät Exception-luokasta ja ajonaikaisia, jotka periytyvät Error tai RuntimeException-luokista. Erona näillä kahdella tyypillä on, ettei ajonaikaisia poikkeuksia (kuten NullPointer) ole välttämätöntä ottaa kiinni. Käytännössä ohjelmoidessa käytetään lähinnä tarkistettuja poikkeuksia.
Luokka TaulukkoTaysiException on tarkistettu poikkeus. Exception -luokan konstruktori ottaa parametrina virheviestin, jonka ohjelmoija itse määrittää. Vaikka tässä tapauksessa luokan nimi on jo varsin kuvaava, niin viestin on silti hyvä antaa lisätietoa ongelman luonteesta. Saattaa jopa olla, että valmiiseenkin ohjelmaan pääsee bugi, jolloin viesti kulkeutuu aina loppukäyttäjälle asti.
public class TaulukkoTaysiException extends Exception {
TaulukkoTaysiException(String viesti) { super(viesti); }
}Mikäli käytettävä metodi on ilmoittanut voivansa heittää poikkeuksen, sen tulemiseen pitää valmistautua (try), tai jos poikkeuksien hoitaminen ei kuulu vielä alkuperäistä metodiakaan käyttävälle ohjelman osalle, niin poikkeus voidaan heittää myös uudestaan eteenpäin. Kun poikkeuksen tulemiseen on valmistauduttu, niin se tulee ottaa myös kiinni (catch), jolloin päätetään mitä toimenpiteitä kuuluu suorittaa poikkeuksen sattuessa. Esimerkin tapauksessa tulostetaan konsoliin virheviesti "tila loppui". Olisi mahdollista tehdä tarkistuksen yhteyteen myös finally-lohko, jonka sisältö suoritetaan joka tapauksessa, eli sekä ilman poikkeusta että sen kanssa.
try {
luvut.lisaa(0); luvut.lisaa(2);
luvut.lisaa(99);
} catch ( TaulukkoTaysiException e ) {
System.out.println("Virhe: " + e.getMessage());
}
// finally { }*13.3.2 Poikkeukset ja ComTest
Oliot ja poikkeukset tuovat testaamiseen aluksi pienet erikoisuutensa, mutta oikein generoitu JUnit-testi syntyy kuitenkin suhteellisen vaivattomasti. Testissä jokaista potentiaalista poikkeusta ei kannata ottaa kiinni, vaan #THROWS-makrolla määritellään myös generoitu testimetodi heittämään poikkeuksen eteenpäin. Generoitu testi ei myöskään sijaitse samassa luokassa kuin TaulukkoTaysiException, joka puolestaan sijaitsee Taulukko-luokan sisällä, joten testit eivät käänny, mikäli polku ei ole oikeassa muodossa.
/**
…
* @example
* <pre name="test">
* #THROWS Taulukko.TaulukkoTaysiException
* Taulukko luvut = new Taulukko();
* luvut.lisaa(0); luvut.lisaa(2); luvut.lisaa(99);
* luvut.toString() === "0,2,99,";
* luvut.set(1,4); luvut.toString() === "0,4,99,";
* int luku = luvut.get(2);
* luvut.get(2) === 99;
…Mikäli testi ei jostain syystä toimi ja joku riveistä heittääkin odottamatta poikkeuksen, niin tällöin testiympäristö ottaa sen automaattisesti vastaan, eikä testi mene läpi, mikä onkin tietysti haluttu lopputulos.
Toisaalta on tiedettävä, että myös ohjelmoidut poikkeukset toimivat. Käytetään jälleen samaa #THROWS-makroa halutun lauseen jälkeen
…
* luvut.set(21, 4); #THROWS IndexOutOfBoundsException
* luvut.lisaa(0); luvut.lisaa(0); //taulukko täyteen
* luvut.lisaa(0); #THROWS Taulukko.TaulukkoTaysiException
* </pre>
*/jolloin JUnit tiedostoon generoituu jotain tämänkaltaista.
try {
luvut.set(21, 4);
fail("Taulukko: 14 Did not throw IndexOutOfBoundsException");
} catch(IndexOutOfBoundsException _e_){ _e_.getMessage(); }
luvut.lisaa(0); luvut.lisaa(0);
try {
luvut.lisaa(0);
fail("Taulukko: 16 Did not throw Taulukko.TaulukkoTaysiException");
} catch(Taulukko.TaulukkoTaysiException _e_){ _e_.getMessage();Edellä siis set-metodin kutsun perään generoituu fail-kutsu, joka aiheuttaa sen, ettei testi mene läpi, mikäli siihen asti päästään. Koska kuitenkin set-metodin "väärä" käyttö heittää (tai pitäisi heittää) poikkeuksen, niin fail ohitetaan. Itse poikkeuksen kiinniottamisessa ei tehdä mitään. Kutsu getMessage on vain sitä varten, ettei kääntäjä valita käyttämättömästä poikkeusoliosta. Näin poikkeuksen tullessa testi jatkuu.
13.4 Olion clone
Olion kloonaamisen kanssa on oltava huolellinen. Pitäisi aluksi kutsua yläluokan clonea. Mutta tämän jälkeen olio voi jäädä tilaan, jossa jaetaan yhteisiä alkioita toisen olion kanssa. Oletuksena clone tekee niin, että klooni saa samat attribuutit kuin kloonaavalla olioilla on. Tämä on riittävää jos olioviitteet viittaavat immutable olioihin. Mutta jos viitattavat oliot voivat muuttua, tapahtuu se, että toisen muuttuessa toinenkin näyttää muuttuvan ja kloonille ei saisi käydä näin. Tätä sanotaan matalaksi kopioinniksi (shallow clone). Syväkopioilla tarkoitetaan sellaista, missä jokaisesta olioista otetaan syväkopio (deep clone).
Seuraava kuva ja animaatio sen alla havainnollistaa tilannetta.
13.5 Geneerinen taulukko
Edellisen Taulukko.java esimerkin ongelmana on, ettei sillä pysty tallentamaan kuin int muotoisia arvoja. Oman taulukkoluokan luominen jokaiselle erilaiselle tyypille on tietysti työlästä, joten tarvitaan parempi ratkaisu. Javaan lisättiin 1.5 versiossa tuki geneerisyydelle, jonka avulla oliolle voi sitä luodessaan viestittää millaista dataa halutaan tallentaa.
Edelliseen Taulukko.java ohjelmaan ei tarvitse lisätä kuin vapaasti nimettävä tyyppiparametri, tässä tapauksessa TYPE, jolla korvataan vanhat taulukon tallennusmuotoihin liittyvät int-arvot.
- dynaaminen.TaulukkoGen.java -esimerkki dynaamisesta taulukosta
Hieman geneerisyyden kaltainen toiminnallisuus saavutettiin ennen 1.5 päivitystä hieman työläästi Object-luokan taulukolla ja eksplisiittisillä tyyppimuunnoksilla (casting). Tämä on kuitenkin huomattavan vaivalloinen tapa ohjelmoida.
Object mjono = new String("df");
System.out.println(((String)mjono).length());Konepellin alla Javan geneerisyys perustuu pitkälti edelleen samaan ideaan, mutta nyt tyyppimuunnokset tehdäänkin tietorakenteen sisällä, kuten edellisessä esimerkissä
public TaulukkoGen(int koko) {
alkiot = (TYPE [])new Object[koko];
// alkiot = new TYPE[koko];*
}Geneerisyyden kääntöpuolena sen sisäinen toteutus antaa tallentaa ainoastaan oliomuotoista dataa. Ohjelmoijalle päin kyllä näyttää, että Integer-taulukolle on mahdollista antaa int-arvo, mutta todellisuudessa sille viedäänkin aina uusi Integer-olio. Vastaavasti kun tietorakenteesta haetaan int-muuttujaan tallennettava arvo, niin sijoituksen tulos saadaan intValue()-metodista. Raa'assa numeronmurskauksessa joudutaan nyt suorittamaan työläitä autoboxing (int ->Integer, Integer ->int) operaatioita. Paljon laskentatehoa vaativaa toiminnallisuutta varten on siis hyvä tietää millaista tietorakennetta kannattaa käyttää.
13.6 Javan Collections Framework
Koska erilaisten dynaamisten tietorakenteiden (vrt. Taulukko.java) käyttö on erittäin yleistä, on Javan standardiin lisätty joukko tietorakenteita. Jotta nämä tietorakenteet pystyisivät tallentamaan erilaisia tyyppejä, on niistä tehty sellaisia, että ne tallentavat Javan kaikkien luokkien kantaluokan Object-luokan viitteitä.
Meidänkin esimerkissämme Jasenet ja Harrastukset eroavat toisistaan vain hyvin vähän. Ero on itse asiassa muutaman Jasen -sanan muuttuminen Harrastus -sanaksi. Jos olisimme olleet tarpeeksi "ovelia", olisimme voineet tehdä vain yhden geneerisen tietorakenteen, josta olisi sitten luotu kaksi erilaista esiintymää.
Tietorakenteiden arkkitehtuuri on varsin monimutkainen kokoelma erilaisia rajapintoja, toteutuksia ja algoritmeja. TaulukkoGen.javan kaltaista toiminnallisuutta ei yleensä kannata luoda itse, vaan käyttää valmista ratkaisua, jolle on jo olemassa joukko valmiiksi optimoituja algoritmeja. Tärkeintä onkin tietää, minkälaista tietorakennetta ongelmaan kannattaa soveltaa.
Taulukkopohjaiset rakenteet, kuten ArrayList ja Vector soveltuvat hyvin tapauksiin, joissa luetaan alkioita indeksien avulla ja lisäys/poisto-operaatiot tehdään taulukon loppuun. Toisaalta, jos haluttuun toiminnallisuuteen kuuluu useita alkioiden poistoja ja lisäyksiä satunnaiseen kohtaan tietorakennetta, olisi LinkedList parempi vaihtoehto.
Alla on kuva Javan tärkeimmistä tietorakennerajapinnoista.
13.6.1 ArrayList ja geneerisyys
Seuraavassa on Taulukko.javaa vastaava geneerinen esimerkki toteutettu ArrayList-rakenteella:
- dynaaminen.ArrayListMalliGen.java -ArrayList-luokka
13.6.2 Iteraattori
Katso iteraattorin JavaDoc.
Esimerkissä taulukon tulostus on tehty malliksi myös iteraattorin avulla.
for (Iterator<Integer> it = luvut.iterator(); it.hasNext(); ) {
int luku = it.next();
out.print(luku + " ");
}Iteraattorin ideana on tarjota tietty, erittäin suppea joukko operaatioita, joita siihen voidaan kohdistaa. Näin samalla rajapinnalla varustettu iteraattori voidaan toteuttaa hyvin erilaisille tietorakenteille esimerkiksi taulukoille ja linkitetyille listoille. Iteraattorille esitettyjä suomennoksia ovat esimerkiksi selain ja vipellin.
Huomaa, että edellä for-silmukasta puuttuu tarkoituksellisesti kasvatusosa. Lause
Integer luku = it.next(); // tässä erikositapauksessa myös int luku toimiiantaa iteraattorin kohdalla olevan alkion ja siirtyy samalla seuraavaan alkioon. Eli periaatteessa iteraattoria voisi käyttää myös:
out.print(it.next() + " ");
out.print(it.next() + " ");
out.print(it.next() + " ");mikäli olisi varma, että tietorakenteessa on vähintään kolme alkiota.
Kun iteraattori luodaan
Iterator<Integer> it = luvut.iterator();siirtyy se "ensimmäisen alkion kohdalle". Se miten tietorakenne ja iteraattori tämän yhdessä toteuttavat, on se niiden keskinäinen asia. Esimerkiksi linkitetyssä listassa iteraattori on tavallaan viite listan ensimmäiseen alkioon ja next antaa kohdalla olevan alkion ja siirtyy seuraavaan alkioon (tai null).
Periaatteessa voidaan luoda useampiakin iteraattoreita, jotka menevät tietorakennetta yhtäaikaa läpi. Ongelmia kuitenkin tulee, mikäli tietorakennetta muuttaa samalla, kun toinen iteraattori kulkee sitä läpi.
Oikeasti pinnan alla for-each on vain syntaktista karkkia (syntactic sugar) iteraattoritoteutukselle.
for (Integer luku: luvut) {
out.print(luku + " ");
}ArrayListin ja Vectorin tapauksissa tietorakenne voitaisiin käydä läpi myös taulukkomaisesti,
for (i=0; i<luvut.size();i++)
out.print(luvut.get(i));mutta tällöin tietorakenteen vaihtaminen esimerkiksi linkitetyksi listaksi vaatisi muutoksia tulosta-aliohjelmaan. Eli aina kun mahdollista, kannattaa välttää käyttämästä sitä tietoa, mikä tietorakenne on käytössä.
13.6.3 Geneerisyys
Alkuperäisissä Javan tietorakenteissa ei voitu taata mitenkään mitä tietorakenteeseen säilöttiin, vaan sille olisi voinut antaa sekaisin mitä tahansa olioita. Tällainen toiminnallisuus on useimmiten paitsi hyödytöntä, myös tietorakenteen käyttämistä rajoittavaa. Tähän tuli onneksi avuksi geneerisyys.
Parametrilla Collection taataan, että metodille tuodaan Collection-rajapinnan toteuttava tietorakenne, johon on säilötty Integer-olioita. Nyt vältymme explisiittisten tyyppimuunnosten tekemiseltä, mikä puolestaan antaa meille mahdollisuuden hyödyntää for-each rakennetta.
13.6.4 Algoritmit
Kun tietorakenteelta oletetaan tietty rajapinta, voidaan sille suorittaa sopiva algoritmi, esimerkiksi lajittelu, tietämättä tietorakenteen yksityiskohtia:
dynaaminen.AlgoritmiMalliGen.java - Collections-luokka
Lisää Javan Collections Frameworkista ja sen käyttämisestä:
Katso myös tämän monisteen kohta Lambda-lausekkeet ja suodattaminen.
13.7 Tietovirta parametrina
Metodi tulosta on esitelty
public static void tulosta(OutputStream os, Collection luvut) {Näin voidaan tulostusvaiheessa valita mille laitteelle tulostetaan.
14. Funktio-olio
Mitä tässä luvussa käsitellään?
- Olioiden ja rajapintojen kertaus
- funktion vieminen parametrina
- Integraalin laskeminen numeerisesti
Luvun esimerkkikoodit:
Tämän luvun tarkoitus on johdatella lukija ymmärtämään tarve välittää myös toimintoja (funktioita) parametrina. Itse asiassa nykyaikaiset graafiset ohjelmointikehykset perustuvat nimenomaan tähän ideaan. On tehty esimerkiksi valmis painike (button), mutta painikkeen tekijä ei tietenkään voi tietää mitä painikkeella pitäisi missäkin ohjelmassa tehdä. Siksi painikkeelle viedään tiedoksi tietyn rajapinnan toteuttava toiminto ja kun painiketta painetaan, kutsutaan tätä toimintoa ja näin painikkeesta on saatu yleiskäyttöinen. Tätä sanotaan tapahtumalähtöiseksi ohjelmoinniksi (event driven)
Yritämme siis oppia ymmärtämään, että miksi vaikka JavaFX-lomakkeen käsittelijä tehdään koodilla:
button.setOnAction(new EventHandler<ActionEvent>() {
@Override
public void handle(ActionEvent event) {
label.setText("Well Done!");
}
});tai miksi se nykyisin voidaan korvata myös Lambda-lausekkeella:
button.setOnAction( e -> label.setText("Well Done!"));
C#:issa voidaan tehdä samalla tavalla kuin nyt esitetään, mutta vastaava onnistuu myös helpommin delegaattien avulla.
Toinen tässä monisteessa käytettävä sovelluskohde on oikeellisuustarkistus. Jäsenen kentät ovat muuten keskenään hyvin samankaltaisia, mutta kullekin voi olla erilainen tapa tarkistaa milloin käyttäjän syöte on oikein.
14.1 Numeerinen integrointi
Suoraan valmiin graafisen kehyksen toimintojen selittäminen on kohtuullisen iso operaatio. Otetaan siksi pienempi esimerkki, missä itse valittu toiminto (funktio) nousee selkeästi suureen roolin itse ongelman kannalta. Aloitetaan integroimalla yksi tietty funktio ja huomataan sitten, että suuri osa koodista olisi funktiosta riippumatonta. Sitten esimerkissä toteutetaan numeerinen integrointi myös muutamille muille funktiotyypeille.
Luvun matematiikkaa ei kannata pelästyä, sillä kyseessä on varsin yksinkertainen toimenpide. Kyseessä on vain suorakulmioiden pinta-alojen yhteenlasku. Numeerinen integrointi onnistuu, kun jaetaan funktion alapuoli pylväisiin, niin että yksittäisen pylvään korkeus on yhtä suuri kuin funktion arvo pisteessä x. Lopulta kaikkien pylväiden yhteenlaskettu pinta-ala \(A\) lasketaan. Mitä enemmän pylväitä välille laitetaan, niin sitä tarkempi tulos saadaan, mutta vastaavasti joudutaan tekemään enemmän laskutoimituksia.
14.1.1 Sinifunktion integrointi
Tutustutaan ensin ongelmaan tavallisen sinifunktion avulla, mutta yleistetään myöhemmin ohjelma toimimaan myös muilla funktioilla.
\[ A = \int_0^\pi sin(x) dx = -cos(\pi) - -cos(0) = --1 - -1 = 2 \]
Muuttuja summa sisältää kaikkien laatikoiden yhteenlasketut pinta-alat. Laatikoiden alojen lasku onnistuu, kunhan tiedetään yksittäisen laatikon leveys, jota koodissa merkitään dx ja korkeus, joka puolestaan on funktion arvo pisteessä x.
- funktio.integroi.Integroi.java - Sinifunktion numeerinen integrointi
14.2 Numeerinen integrointi ja rajapinta
Käyttömahdollisuudet pelkkiä sinifunktioiden pinta-aloja laskevalle metodille ovat tietysti hyvin rajalliset. Laajennetaan metodia yleiskäyttöiseksi rajapintojen ja perinnän avulla.
Rajapinnan avulla määritellään metodi, jolle tuodaan parametrina reaaliluku ja joka palauttaa reaaliluvun.
funktio.integroi.Integroi2.java - funktio-oliot, rajapinta
/** * Rajapinta kaikille funktiolle R->R */ public interface FunktioRR { /** * @param x piste jossa lasketaan * @return funktion arvo pisteessä */ public double f(double x); }
Irrotetaan nyt sinifunktion toteutus FunktioRR-rajapinnan (funktio joka kuvaa reaaliluvun toiseksi reaaliluvuksi) toteuttavaan luokkaan. Kysyttäessä SinFun-luokan instanssilta funktion arvoa pisteessä x, välitetään pyyntö ja palautetaan arvo Math-kirjaston sin-metodilta.
funktio.integroi.Integroi2.java - funktio-oliot, funktio
static class SinFun implements FunktioRR { @Override public double f(double x) { return Math.sin(x); } }
Nyt integroi-metodiin tuodaan uutena parametrina FunktioRR-rajapinnan toteuttava olio(viite) f. Itse integraalin laskeminen tapahtuu yhä samalla tapaa, eli ainoa muutos on vaihtaa sin-funktion viitteet oliolta f arvon kysyviksi lauseiksi.
- funktio.integroi.Integroi2.java - funktio-oliot, integrointi
14.3 Rajapinnan käyttäminen
Tehtyä rajapintaa voidaan nyt hyödyntää myös muilla funktiotyypeillä. Tehdään luokka toisen asteen polynomiyhtälöiden

integroimista varten.
funktio.integroi.Integroi2.java - Toisen asteen polynomi
public static class P2 implements FunktioRR { private double a,b,c; public P2() { a = 1; } public P2(double a, double b, double c) { this.a = a; this.b = b; this.c = c; } public double f(double x) { return a*x*x + b*x + c; } }
Toisin kuin SinFun-luokasta, tulee P2-luokasta hieman monimutkaisempi. Tarvitaan mm. konstruktori, jotta parametreina voidaan viedä polynomille kertoimet.
Toisen asteen polynomi on muuten tehokkaampi laskea alla olevalla muodolla. Miksi?
return (a * x + b) * x + c;Luokkaa voidaan käyttää esimerkiksi seuraavasti.
P2 p2 = new P2(-0.9,2,1); // -0.9x^2 + 2x +1
double ala = integroi(p2,0,2,100);
System.out.printf("%17.15f%n",ala);
14.3.1 Nimettömät sisäluokat
Luokasta voidaan luoda nimetön versio ja siitä uusi olio ilman näkyvän luokan luomista:
14.4 Lambda -lausekkeet
Java 8 mukana tulleiden Lambda-lausekkeiden avulla funktioiden kirjoittaminen yksinkertaistuu. Mikäli rajapinta toteuttaa funktionaalisen rajapinnan, eli siinä on vain yksi abstrakti metodi, voidaan sitä vastaava luokka luoda helposti lambda-lausekkeen avulla.
14.4.1 Lambda-lausekkeiden peruskäyttö
Lambda-lausekkeen yleinen muoto on:
(parametrit) -> { lauseke, joka palauttaa jonkin tuloksen }Parametrin sulut voidaan jättää pois, mikäli parametreja on vain yksi.
Samoin lausesulkuja ei tarvita, mikäli lause on sinänsä arvon palauttava.
Esimerkkejä Lambda-lausekkeista voisi olla:
x -> sin(x)
(a,b) -> a + b;
(a,b) -> { if ( a > b ) return a; else return b; }
(a,b) -> a > b ? a : b;
(s1,s2) -> s1.compareTo(s2) > 0;
() -> 5*6;Esimerkiksi tarvittava sin -funktio-olio voitaisiin tehdä:
FunktioRR sin = x -> Math.sin(x);tai toisen asteen polynomi
FunktioRR p2 = x -> -0.9*x*x + 2*x +1;Integrointi-esimerkki Lambda-lausekkeilla voitaisiin toki kirjoittaa ilmankin apumuuttujia, koska tarvittavat luokat syntyvät integroi-aliohjelman kutsussa:
14.4.2 Lambda-lausekkeet ja tapahtumankäsittely
Lambda-lausekkeiden ansiosta esimerkiksi Swing-kirjaston tapahtumankäsittelyjä voidaan kirjoittaa lyhyemmin. Siinä missä ennen piti kirjoittaa
textSyntymavuosi.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
textSyntymavuosi.selectAll();
}
});riittää Lambdojen avulla kirjoittaa
textSyntymavuosi.addActionListener( e -> textSyntymavuosi.selectAll() );Pitää kuitenkin huomata, että Lambdat eivät toimi esimerkiksi KeyListener ja MouseListener -rajapintojen tapauksessa, koska rajapinnoissa on useita metodeja, joita pitäisi implementoida.
14.4.3 Lambda-lausekkeet ja suodattaminen
Javan tietorakenteissa yksi hyvin tärkeä funktio-tyyppi on predikaatti. Predikaatti saa parametrinaan tutkittavan olion ja se palauttaa totuusarvon sen mukaan, halutaanko oliota käsitellä vaiko ei. Esimerkiksi tietorakenteesta poistaminen voitaisiin tehdä seuraavasti:
Java 8 mukana tuli myös Stream-luokka, jossa on useita eri tapoja käsitellä virtoja. Seuraavassa muutamia esimerkkejä (map, collect, reduce, filter, foreach):
Yksi streamien etu on siinä, että edellä voitaisiin stream() kutsut korvata kutsulla parallelStream(), jolloin operaatiot voitaisiin suorittaa rinnakkain ja näin hyödyntää laitteisto parhaalla mahdollisella tavalla.
15. Tiedostot
Tällää tiedostoon rivitkin
virtaan viskaile tavuset
sinne sullo saatavaksi
muitten metsästettäväksi.
Rivit riivi tiedostosta
ime virrasta tavuset
sieltä sieppaa saataville
levyltä lue lukuset.
Pistele rivit paloiksi
kunnolla katko kummajaiset
sanat sieltä sommittele
numerotkin napsi niistä.
Mitä tässä luvussa käsitellään?
- Tiedostojen käsittely Javan tietovirroilla
- Tiedostot joissa rivillä monta kenttää
Syntaksi:
Tied. avaaminen luku: f = new BufferedReader(new FileReader(nimi));
kirj. f = new PrintWriter(new FileWriter(nimi))
jatk. f = new PrintWriter(new FileWriter(nimi,true))
Stream kirj: f = new PrintStream(new FileOutputStream(nimi));
jatk: f = new PrintStream(new FileOutputStream(nimi),true);
Lukeminen s = f.readLine();
Kirjoittaminen f.println(s);
Sulkeminen f.close(); // aina finally lohkossa!Luvun esimerkkikoodit:
Pyrimme seuraavaksi lisäämään kerho-ohjelmaamme tiedostosta lukemisen ja tiedostoon tallentamisen. Tätä varten tutustumme ensin lukemiseen mahdollisesti liittyviin ongelmiin.
15.1 Tiedostojen käsittely
Tiedostojen käsittely ei eroa päätesyötöstä ja tulostuksesta, siis tiedostojen käyttöä ei ole mitenkään syytä vierastaa! Itse asiassa päätesyöttö ja tulostus ovat vain stdin ja stdout -nimisten tiedostojen käsittelyä.
Tiedostoja on kahta päätyyppiä: tekstitiedostot ja binääritiedostot. Tekstitiedostojen etu on siinä, että ne käyttäytyvät täsmälleen samoin kuin päätesyöttökin. Binääritiedoston etu on taas siinä, että tallennus saattaa viedä vähemmän tilaa (erityisesti numeerista muotoa olevat tyypit) ja suorasaannin käyttö on järkevämpää.
Keskitymme aluksi tekstitiedostoihin, koska niitä voidaan tarvittaessa editoida tavallisella editorilla. Näin ohjelman testaaminen helpottuu, kun tiedosto voidaan rakentaa valmiiksi ennen kuin ohjelmassa edes on päätesyöttöä lukevaa osaa.
15.1.1 Lukeminen
Aikanaan C-ohjelman takia muutettiin hieman alkuperäistä suunnitelmaa jäsenrekisteritiedoston sisällöstä:
Kelmien kerho ry
100
; Kenttien järjestys tiedostossa on seuraava:
id| nimi |hetu |katuosoite |postinumero|postiosoite|kotipuhelin...
1|Ankka Aku |010245-123U|Paratiisitie 13 |12345 |ANKKALINNA |12-12324 ...
2|Susi Sepe |020347-123T| |12555 |Perämetsä | ...
4|Ponteva Veli |030455-3333| |12555 |Perämetsä | ...Silloin lisättiin rivi, jossa kerrotaan tiedoston maksimikoko. Tätä tarvittiin jäsenlistan luomisessa, jotta listasta saataisiin heti mahdollisimman oikean kokoinen. Vaikka tällä tiedolla ei ole enää mitään merkitystä, on se esimerkeissä mukana, jotta tiedostot olisivat myös vanhoilla C-ohjelmilla luettavissa. Omiin uusiin ohjelmiin tätä muutosta ei kannattane tehdä.
Tiedoston sisällössä on kuitenkin pieni ongelma: siinä on sekaisin sekä puhtaita merkkijonoja, numeroita että tietuetyyppisiä rivejä. Vaikka kielessä onkin työkalut sekä numeeristen tietojen lukemiseksi tiedostosta, että merkkijonojen lukemiseen, nämä työkalut eivät välttämättä toimi yksiin. Siksi usein kannattaa käyttää lukemiseen vain yhtä työkalua, joka useimmiten on kokonaisen tiedoston rivin lukeminen.
15.2 Tiedostojen käsittely Javan tietovirroilla
Javan IO-systeemi on varsin monimutkainen. Erilaisia tietovirtoja on yli 60 kappaletta. Alimman tason virta-luokat ovat abstrakteja luokkia määräten vain virtojen rajapinnan. Ylemmällä tasolla hoidetaan fyysistä lukemista ja kirjoittamista. Fyysinen lukeminen ja kirjoittaminen voi tarkoittaa levyn käyttöä, verkon käyttöä tai muiden IO-porttien käyttöä. Seuraavaksi ylemmällä tasolla tarjotaan yksinkertaisempaa rajapintaa esimerkiksi rivien käsittelyyn. Siksi virtoja käytettäessä niitä pitää kerrostaa.
Kun perustoimet on saatu tehtyä, on tiedostojen käsittely Javassa esimerkiksi System.in ja System.out -tietovirtoja vastaavien tietovirtojen käsittelyä.
Olkoon meillä tiedosto nimeltä luvut.dat (Eclipsellä tehtäessä tiedosto on hyvä pitää oletuksena samassa kansiossa missä on .project, se on oletuskansio/hakemisto. Ei siis missään sen alikansiossa/hakemistossa/packagessa.):
Kirjoitetaan esimerkkitiedoston luvut lukeva ohjelma Javan tietovirroilla. Tarkoitus on hylätä ne rivit, joilla ei ole pelkästään reaalilukua:
Tehtävä 15.1 Tiedoston lukujen summa
Muuta tiedoston
Tied_ka.java-ohjelmaa siten, että väärän rivin kohdalla tulostetaan väärä rivi ja lopetetaan koko ohjelma.Muuta edelleen ohjelmaa siten, että väärät rivit tulostetaan näyttöön:
Tiedostossa oli seuraavat laittomat rivit: kissa Lukuja oli...
Ilmoitusta ei tietenkään tule, mikäli tiedostossa ei ole laittomia merkkejä. Tyhjää riviä ei tulkita vääräksi riviksi.
15.2.1 Tiedoston avaaminen muodostajassa
Tiedosto voidaan siis avata heti, kun tiedostoa vastaava tietovirta luodaan:
fi = new Scanner(new FileInputStream(new File("luvut.dat")));Parametri "luvut.dat" on tiedoston nimi levyllä. Nimi voi sisältää myös hakemistopolun, mutta tätä kannattaa välttää, koska hakemistot eivät välttämättä ole samanlaisia kaikkien käyttäjien koneissa. Jos hakemistopolkuja käyttää, niin erottimena kannattaa käyttää /-merkkiä. Samoin kannattaa olla tarkkana isojen ja pienien kirjainten kanssa, sillä useissa käyttöjärjestelmissä kirjainten koolla on väliä.
Lukemista varten avattaessa tiedoston täytyy olla olemassa tai avaus epäonnistuu. Avauksen epäonnistumisesta heitetään FileNotFoundException-poikkeus.
15.2.2 Tiedostosta lukeminen
Tiedostosta lukeminen on jälleen analogista päätesyötön kanssa:
s = fi.next();Mikäli tiedosto on loppu, saa s null-arvon.
15.2.3 Tiedoston lopun testaaminen
Helpoin ratkaisu on perustaa lukusilmukka siihen, että kysytään hasNext-metodilla sisältääkö tiedosto vielä uutta riviä.
while ( fi.hasNext() ) {
... käsittele jonoa s
}15.2.4 Tiedostoon kirjoittaminen
Vastaavasti kirjoittamista varten avattuun tiedostoon kirjoitettaisiin
PrintStream fo;
...
fo = new PrintStream(new FileOutputStream("taulu.txt"));
// avataan tiedosto kirjoittamista varten
// avauksessa vanha tiedosto tuhoutuuMikäli avattaessa tiedostoa kirjoittamista varten, ei haluta tuhota vanhaa sisältöä, vaan kirjoittaa vanhan perään, käytetään avauksessa toista parametria, jolla kerrotaan halutaanko kirjoittaa edellisen tiedoston perään (append):
fo = new PrintStream(new FileOutputStream("taulu.txt",true));
// avataan perään kirjoittamista vartenTiedoston jatkaminen on erittäin kätevää esimerkiksi virhelogitiedostoja kirjoitettaessa.
Edellä voisi käyttää PrintStream virran sijasta PrintWriter-luokkaa, joka olisi yhteensopivampi Reader-luokan kanssa:
PrintWriter fo;
...
fo = new PrintWriter(new FileWriter(nimi,true))Kuitenkin PrintStream on taas yhteensopiva System.out:in kanssa, joten joissakin tapauksissa tämä puolustaa PrintStream-luokan käyttämistä.
Useimmiten kannattaa kaikki näyttöön tulostavat aliohjelmat/metodit kirjoittaa sellaiseksi, että niille viedään parametrina se tietovirta, johon tulostetaan. Näin samalla aliohjelmalla voidaan helposti tulostaa sitten näyttöön tai tiedostoon tai jopa kirjoittimelle (joka on vain yksi tietovirta muiden joukossa, esim. Windowsissa PRN-niminen tiedosto).
15.2.5 Tiedoston sulkeminen close
Avattu tiedosto on aina lukemisen tai kirjoittamisen lopuksi syytä sulkea. Tiedoston käsittely on usein puskuroitua, eli esimerkiksi kirjoittaminen tapahtuu ensin apupuskuriin, josta se kirjoittuu fyysisesti levylle vain puskurin täyttyessä tai tiedoston sulkemisen yhteydessä. Käyttöjärjestelmä päivittää tiedoston koon levylle usein vasta sulkemisen jälkeen. Sulkemattoman tiedoston koko saattaa näyttää 0 tavua.
Javassa tiedoston sulkeminen pitää aina varmistaa try-finally-lohkolla:
... avaa tiedosto
try {
... käsittele tiedostoa
} finally { // Aina ehdottomasti finally:ssa resurssien vapautus
try {
fi.close(); // tiedoston sulkeminen heti kun sitä ei enää tarvita
}
}Tehtävä 15.2 Kommentit näytölle
Kirjoita ohjelma, joka kysyy tiedoston nimen ja tämän jälkeen tulostaa tiedostosta rivien /** ja */ välisen osan näytölle.
15.2.6 Try-with -lause
Edellä käytetty tapa tiedoston avaamiseen on suoraan sanoen sekavan näköistä. Java 7:ssä asiaan tuli pieni parannus: try-with -lause, jossa määritellään mitä resursseja avataan, ja lauseen lopuksi kaikki avatut resurssit suljetaan. Edellä olleet luku- ja kirjoitusesimerkit olisivat try-with-lauseella tehtynä seuraavan näköisiä. Samalla on näytetty esimerkki, miten tiedostoja käsittelevää ohjelmaa voitaisiin testata.
Eli try-with -lauseen ideana on, että
try (luo resurssit) { /jos monta luontia, erota puolipisteilä
käytä resursseja
} // Tässä resurssit vapautetaan
// mahdolliset poikkeuskäsittelylauseetLuotavien resurssien pitää olla sellaisia, jotka toteuttavat closable-rajapinnan.
15.2.7 Tiedostoja käsittelevien ohjelmien testaaminen
Edellisissä esimerkeissä oli näytetty, miten tiedostoja käsitteleviä ohjelmia testataan. Tärkeimpänä ideana on, että jos testataan lukemista, ei voida luottaa siihen, että luettava tiedosto olisi olemassa. Siksi olisi hyvä, että testattavalle ohjelmalle voitaisiin viedä tiedoksi luettavan tiedoston nimi. Sitten testin aluksi luodaan testattava tiedosto ja lopuksi se poistetaan levyltä.
* VertaaTiedosto.kirjoitaTiedosto(tiednimi,"33\n11\nkissa\n5");
...
* VertaaTiedosto.tuhoaTiedosto(tiednimi);Riippuen mitä testattava funktio tekee tiedostolle, joudutaan asioita soveltamaan. Edellä tiedoston lukemista ei oltu erikseen suunniteltu testattavaksi ja se tulosti tietoja näyttöön. Tässä tilanteessa jouduttiin aluksi kaappaamaan näyttöön tuleva teksti:
* Suuntaaja.StringOutput so = new Suuntaaja.StringOutput();Sitten ajettiin pääohjelma, joka osasi lukea pyydetyn nimisen tiedoston:
* main(new String[]{tiednimi});Tämän jälkeen tulostuksen kaappaaminen poistettiin:
* so.palauta();ja lopuksi verrattiin, mitä suuntaaja so (suuntaaja output) oli saanut kaapattua tulostuksesta:
* so.ero(tulos) === null;Testien avuksi kirjoitetun Ali.jar -paketissa olevan Suuntaaja-luokan (ja VertaaTiedosto-luokan) ero -metodi on tehty siten, että jos sisältö ja verrattava ovat samat, palautetaan null-viite. Muuten palautetaan merkkijono, joka sisältää ensimmäisen erokohdan rivinumeron ja kummankin verrattavan vastaavan merkkijonon. ero-metodit osaavat ottaa huomioon eri järjestelmien väliset erilaiset rivinvaihtomerkit, eivätkä pidä niitä eroina.
Testin lopuksi vielä kaapataan virhetietovirta (stderr) ja katsotaan, toimiiko ohjelman sekin osa, milloin tiedostoa ei saada avattua. Tässä pieni ongelma on se, että eri järjestelmissä virheviesti on erilainen. Siksi vertailu on tehty käyttäen regular expressionia (=R=), eli viestin loppuosa saa olla mitä vaan.
Vastaavasti tiedostoon kirjoittavaa ohjelmaa testattaessa on ensin poistettu olemassa oleva tiedosto. Sitten on kirjoitettu sinne kerran ja katsottu, vastaako syntynyt tiedosto kuviteltua tulostusta. Sitten on kirjoitettu uudelleen, ja koska tiedosto on avattu append-moodissa, pitäisi sisällön olla siellä tämän jälkeen kaksi kertaa. Lopuksi tilapäinen tiedosto on poistettu.
15.3 Tiedoston yhdellä rivillä monta kenttää
Jäsenrekisterissä on tiedoston yhdellä rivillä useita kenttiä. Kentät saattavat olla myös eri tyyppisiä. Miten lukeminen hoidetaan varmimmin?
15.3.1 Ongelma
Olkoon meillä vaikkapa seuraavanlainen tiedosto:
- tuotteet.dat - esimerkkitiedosto
Tiedostoa voitaisiin lukea periaatteessa niin että luetaan ensin yksi merkkijono, sitten tolppa, sitten reaaliluku, tolppa ja lopuksi kokonaisluku.
Ratkaisussa on kuitenkin seuraavia huonoja puolia:
- mikäli tiedoston loppu ei olekaan viimeisen rivin lopussa, tulee "ylimääräisen" rivin käsittelystä ongelmia
- mikäli jokin rivi on väärää muotoa, menee ohjelma varsin sekaisin
Tehtävä 15.3 Ohjelman "sekoaminen"
Jos esimerkin hahmotellussa ratkaisussa olisi silmukka, joka tulostaa tiedot kunkin lukemisen jälkeen, niin mitä tulostuisi seuraavasta tiedostosta:
Volvo | 12300 | 1
Audi 55700 | 2
Saab | 1500 | 4
Volvo | 123400 | 1
<EOF>15.4 Merkkijonon paloittelu
Tutkitaanpa ongelmaa tarkemmin. Tiedostosta on siis luettu rivi, joka on muotoa
┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬
│ │V│o│l│v│o│ │ │ │ │1│2│3│0│0│ │ │ │1│
└─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴
Jos saisimme erotettua tästä 3 merkkijonoa:
pala1 pala2 pala3
┌─┬─┬─┬─┬─┬─┬─┬ ┬─┬─┬─┬─┬─┬─┬─┬─┬ ┬─┬─┬
│ │V│o│l│v│o│ │ │ │ │1│2│3│0│0│ │ │ │1│
└─┴─┴─┴─┴─┴─┴─┴ ┴─┴─┴─┴─┴─┴─┴─┴─┴ ┴─┴─┴voisimme kustakin palasesta erikseen ottaa haluamme tiedot. Esimerkiksi 1. palasesta saadaan tuotteen nimi, kun siitä poistetaan turhat välilyönnit trim -metodilla. Lukujen käsittely ei kuitenkaan ole aivan näin yksinkertaista.
15.4.1 parse
Merkkijono pitää varsin usein muuttaa reaaliluvuksi tai kokonaisluvuksi. Java tarjoaa luokissa Integer ja Double mahdollisuuden muuttaa merkkijono vastaavaksi lukutyypiksi:
double d = Double.parseDouble(jono);
int i = Integer.parseInt(jono);Edellä mainitut metodit heittävät poikkeuksen, jos jono sisältää mitä tahansa muuta kuin pelkkiä lukuun kuuluvia merkkejä.
Siksi kirjoitammekin luokkaan Mjonot kaksi funktiota erotaDouble ja erotaInt:
public static double erotaDouble(String jono, double oletus) ...
public static int erotaInt(String jono, int oletus)Jos funktio ei löydä merkkijonosta lukua, se palauttaa oletuksen. Nämä funktiot toimivat oikein myös seuraavien jonojen kanssa:
12.34 e => 12.34
14 kpl => 1415.4.2 erota
Tehdään myös yleiskäyttöinen funktio erota, jonka tehtävä on ottaa merkkijonon alkuosa valittuun merkkiin saakka, poistaa valittu merkki ja palauttaa sitten funktion tuloksena tämä alkuosa. Itse merkkijonoon jää jäljelle ensimmäisen merkin jälkeinen osa. Funktio on kirjoitettu tiedostoon Mjonot.java:
public static String erota(StringBuilder jono, char merkki,
boolean etsitakaperin) {
if ( jono == null ) return "";
int p;
if ( !etsitakaperin ) p = jono.indexOf(""+merkki);
else p = jono.lastIndexOf(""+merkki);
String alku;
if ( p < 0 ) {
alku = jono.toString();
jono.delete(0,jono.length());
return alku;
}
alku = jono.substring(0,p);
jono.delete(0,p+1);
return alku;
}
}15.4.3 Esimerkki erota-funktion käytöstä
Kirjoitetaan lyhyt esimerkki, jolla demonstroidaan funktion käyttöä:
- tiedosto.ErotaEsim.java - esimerkki erota-funktion käytöstä
Ohjelma tulostaa:
0: pala = '' jono = ' Volvo | 12300 | 1'
1: pala = ' Volvo ' jono = ' 12300 | 1'
2: pala = ' 12300 ' jono = ' 1'
3: pala = ' 1' jono = ''
4: pala = '' jono = ''15.4.4 Erota funktion toiminta vaihe vaiheelta
Ennen ensimmäistä kutsua tilanne on seuraava:
pala jono
┌─┐ ┌─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┐
│ │ │ │V│o│l│v│o│ │|│ │ │1│2│3│0│0│ │|│ │1│
└─┘ └─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┘
0 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8Ensimmäisessä kutsussa erota-funktio löytää etsittävän | -merkin paikasta 7. Merkit 0-6 kopioidaan funktion paluuarvoksi ja sitten jonosta tuhotaan merkit 0-7. Funktion paluuarvo sijoitetaan muuttujaan pala:
pala jono
┌─┬─┬─┬─┬─┬─┬─┬ ┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬─┬
│ │V│o│l│v│o│ │ │ │ │1│2│3│0│0│ │|│ │1│
└─┴─┴─┴─┴─┴─┴─┴ ┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴─┴
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8Seuraavalla kutsulla (kerta 2) |-merkki löytyy jonosta paikasta 8. Nyt jonon merkit 0-7 kopioidaan funktion paluuarvoon ja merkki 8 tuhotaan. Kutsun jälkeen tilanne on:
pala jono
┌─┬─┬─┬─┬─┬─┬─┬─┐ ┌─┬─┐
│ │ │1│2│3│0│0│ │ │ │1│
└─┴─┴─┴─┴─┴─┴─┴─┘ └─┴─┘
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8Kolmannessa kutsussa merkkiä | ei enää löydy jonosta. Tämä ilmenee siitä, että find-metodi palauttaa arvon string::npos (no position), eli ei paikkaa. Näin koko jono kopioidaan funktion paluuarvoksi ja kutsun jälkeen tilanne on:
pala jono
┌─┬─┐ ┌┐
│ │1│ ││
└─┴─┘ └┘
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8Vastaava toistuu neljännessä kutsussa, eli koko jono sitten kopioidaan paluuarvoksi ja tilanne on neljännen kutsun jälkeen:
pala jono
┌┐ ┌┐
││ ││
└┘ └┘
0 1 2 3 4 5 6 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8Tämän jälkeen tilanne pysyy samana, vaikka erota-funktiota kutsuttaisiin kuinka monta kertaa tahansa. Tästä saadaan se etu, että erota-funktiota voidaan turvallisesti kutsua kuinka monta kertaa tahansa, vaikkei jonosta enää palasia saataisikaan. Jos kutsua tehdään silmukassa, voidaan silmukan lopetusehdoksi kirjoittaa
while ( jono.length() != 0 ) {
pala = erota(jono,'|');
System.out.println(pala);
}15.4.5 Luvun erottaminen
Usein samassa jonossa on sekaisin lukuja ja merkkijonoja. Jotta käsittely saataisiin symmetrisemmäksi eri tyyppien välillä, niin luokkaan Mjonot on kirjoitettu myös polymorfiset funktiot:
Idea on siinä, että jos myöhemmin huomataan vaikka että muuttujan kpl pitäisi olla tyypiltään double eikä int, riittää vain muuttujan kpl tyypin vaihtaminen.
Jos halutaan käsitellä tilanteet, joissa joku kenttä onkin virheellistä muotoa, on edellisestä myös poikkeuksen heittävät muodot:
try {
s = erotaEx(jono,'|',s); // "Volvo 145"*
d = erotaEx(jono,'|',d); // 2000
kpl = erotaEx(jono,'|',kpl); // 3
} catch ( NumberFormatException ex ) {
System.out.println(ex.getMessage());
}15.5 Lukeminen ja paloittelu
Nyt voimme toteuttaa "tuotetiedoston" lukevan ohjelman Javan tietovirroilla ja funktioiden erotaEx avulla:
Ohjelma tulostaa:
-------------------------------------------
Volvo 12300 1
Audi 55700 2
Saab 1500 4
Volvo 123400 1
-------------------------------------------15.5.1 Olio joka lukee itsensä
Muutetaan vielä tuotteiden lukua oliomaisemmaksi, eli annetaan tuotteelle kuuluvat tehtävät kokonaan Tuote-luokan vastuulle, samalla lisätään Tuotteet-luokka.
15.6 Esimerkki tiedoston lukemisesta
Seuraavaksi kirjoitamme ohjelman, jossa tulee esiin varsin yleinen ongelma: tietueen etsiminen joukosta. Kirjoitamme edellisiä esimerkkejä vastaavan ohjelman, jossa tavallisen tulostuksen sijasta tulostetaan kunkin tuoteluokan yhteistilanne.
Tehtävä 15.4 Tietorakenne
Piirrä kuva Tuotteet -luokan tietorakenteesta.
Tehtävä 15.5 Perintä
Miten voisit perinnän avulla saada tiedoston LueRek.java luokasta Tuote tiedoston LueTRek.java vastaavan luokan (tietysti eri nimelle, esim. RekTuote). Mitä muutoksia olisi hyvä tehdä alkuperäisessä Tuote-luokassa?
Tehtävä 15.6 Tunnistenumero
Lisää LueTRek.java-ohjelmaan tunnistenumeron käsittely mahdollista tulevaa relaatiokäyttöä varten.
Tehtävä 15.7 Graafinen mittakaava
Kirjoita mittakaavaohjelma, jossa on vakiotaulukko
--------------------
|yks | mm |
|mm | 1 |
|cm | 10.0 |
|dm | 100.0 |
|m | 1000 |
|inch | 25.4 |
--------------------Alasvetovalikosta voi valita millä yksiköllä matka on mitattu kartalta. Muunnos tehdään aina kilometreiksi kahden desimaalin tarkkuudella. Mieti miten saat toimimaan ilman erillistä Laske -nappia, eli suorittamaan muunnokset automaattisesti aina kun jotain arvoa muutetaan.
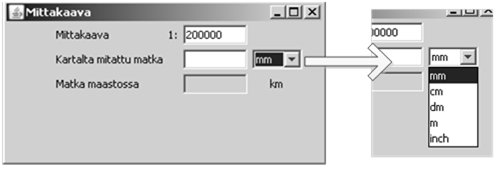
Tehtävä 15.8 Graafinen mittakaava ja luku tiedostosta
Muuta ohjelmaa siten, että yksiköiden muunnostaulukko luetaan ohjelman aluksi tiedostosta muunnos.dat.
15.7 Kerhon tallennukset
Kerho-ohjelmassa tallennusvastuut kannattaa jakaa niin, että Kerho-luokka määrää Jasenet ja Harrastukset-luokat tekemään omat lukemiset ja tallennukset.
public void lueTiedostosta(String nimi) throws SailoException {
jasenet = new Jasenet(); // jos luetaan olemassa olevaan niin helpoin tyhjentää näin
harrastukset = new Harrastukset();
setTiedosto(nimi);
jasenet.lueTiedostosta();
harrastukset.lueTiedostosta();
}
...
public void tallenna() throws SailoException {
String virhe = "";
try {
jasenet.tallenna();
} catch ( SailoException ex ) {
virhe = ex.getMessage();
}
try {
harrastukset.tallenna();
} catch ( SailoException ex ) {
virhe += ex.getMessage();
}
if ( !"".equals(virhe) ) throw new SailoException(virhe);
}Sitten esim. Jasenet-luokka avaa tiedoston kirjoittamista varten ja sitten pyytää jokaiselta jäseneltä erikseen merkkijonona tiedostoon tallennettavan muodon (toString()) ja kirjoittaa sen tiedostoon:
try ( PrintWriter fo = new PrintWriter(new FileWriter(ftied.getCanonicalPath())) ) {
...
for (Jasen jasen : this) {
fo.println(jasen.toString());
}
} ...Vastaavasti tiedon lukemisessa Jasenet-luokka avaa tiedoston lukemista varten ja sitten lukee tiedostosta rivi kerrallaan. Sitten kutakin kelvollista riviä varten luo uuden jäsenen ja antaa rivin jäsenelle käsiteltäväksi ja jäsenen kenttiin laitettavaksi (parse). Lopuksi uusi jäsen lisätään tietorakenteeseen:
while ( (rivi = fi.readLine()) != null ) {
rivi = rivi.trim();
if ( "".equals(rivi) || rivi.charAt(0) == ';' ) continue;
Jasen jasen = new Jasen();
jasen.parse(rivi); // voisi olla virhekäsittely
lisaa(jasen);
}16. Kerho-ohjelman rakenne
Mitä tässä luvussa käsitellään?
- Jäsenen ja käyttöliittymän välinen keskustelu
- Kenttien lisääminen käyttöliittymään
- Tietorakenteeseen lukeminen
- Oikeellisuustarkastukset
- Kentistä hakeminen
- Säännölliset lausekkeet
16.1 Jäsen ja kentät
Jäsenen käyttöliittymää voitaisiin lähteä tekemään niin, että erikseen rakennetaan tiedot siitä, että jäsenessä on nimi, henkilötunnus jne. Hyvin nopeasti huomataan, että tämä tie johtaa toistuvaan koodiin ja vaikeaan ylläpitoon. Seuraavaksi mietitäänkin, miten voitaisiin yleistää jäsenen tiedot niin, että käyttöliittymän ei tarvitsekaan tietää jäsenen tietojen yksityiskohtia.
16.1.1 Algoritmi näytön ja jäsenen keskustelulle
Lisäämällä byrokratiaa näytön ja jäsenen välille voidaan näyttö pitää tietämättömänä siitä, mitä kenttiä jäsenessä todella on. Minkälaista byrokratiaa? Esimerkiksi "keskustelu" näytön ja jäsenen välillä voisi olla seuraavanlainen komentoriviliittymää varten:
1. Näyttö: montako kenttää sinulla on jäsen?
2. Jäsen: 13 kenttää
3. Näyttö: no annappa minulle 1. kenttä merkkijonona!
4. Jäsen: Ankka Aku
5. Näyttö: Milläs kysymyksellä tämä kenttä kysytään?
6. Jäsen: Jäsenen nimi
7. Näyttö kysyy käyttäjältä Jäsenen nimi (Ankka Aku) > => jono
8. Näyttö tutkii vastattiinko q tms. erikoismerkki, jos niin pois
9. Näyttö: Sijoitapa jäsen tämä jono 1. kentäksi.
10. Näyttö jatkaa kohdasta 3 mutta kentälle 2 kunnes kaikki 13 kenttää
käsiteltyVastaavasti graafisessa liittymässä idea voisi olla seuraava
1. Näyttö: montako kenttää sinulla on jäsen?
2. Jäsen: 13 kenttää
3. Näyttö: Mikä on ensimmäinen järkevä kentän indeksi kysyttäväksi
4. Jäsen: indeksi 1
5. Näyttö silmukassa 1..(13-1):
5.1 Näyttö: Anna kenttään i tarvittava otsikkoteksti
5.2 Jäsen: palauttaa merkkijonon (esim. nimi tai hetu)
5.3 Näyttö: luo lomakkeelle syöttökentän jonka vieressä ko merkkijono
6. Kun lomake käynnistetään tietylle jäsenelle
6.1 Tyhjennetään edit-kentät
6.2 Silmukassa i = 1..(13-1)
6.3 Näyttö: anna kentän i sisältö merkkijonona
6.4 Jäsen: palauttaa merkkijonon (esim. Ankka Aku tai 030451-111A)
6.5 Näyttö: laittaa merkkijonon syöttökentän oletusarvoksi
7. Näyttö: jää odottamaan kun käyttäjä täyttää lomaketta
7.1 Käyttäjä: muuttaa jotakin syöttöruutua indeksissä i
7.2 Näyttö: otetaan paikassa i oleva jono s
jasen, laita jono s kenttään i
7.3 Jasen: tarkistaa jonon s sopivuuden kenttään i.
Jos OK, sijoittaa sisällön kenttää i ja palauttaa OK.
Jos virhe, palauttaa virhetekstin
7.4 Näyttö: ottaa jäsenen palautuksen
Jos OK pyyhkii mahdolliset vanhat virheilmoitukset pois
Jos tulee virheilmoitus, näyttää sen käyttäjälle16.2 Näytön ja jäsenen välinen rajapinta
Edellisestä algoritmista huomaamme, että jäseneen kannattaa tehdä rajapinta, jossa on esimerkiksi metodit:
int getKenttia() - monta kenttää on jäsenellä
int ekaKentta() - 1. mielekäs kenttä kysyttäväksi (mm. id:tä ei kysytä)
String getKysymys(int k) - antaa k:n kentän kysymiseksi tarvittavan tekstin
String anna(int k) - palauttaa k:n kentän sisällön merkkijonona
String aseta(int k, String jono) - asettaa k:n kentän arvoksi jonon ja palauttaa
null jos jono on hyvä, muuten virheilmoituksen
tekstinä joka voidaan tulostaa käyttäjälleKäytännön toteutus noille metodeille voi perustua yksinkertaisimmillaan ihan switch-lauseisiin. Yksinkertaisessa esimerkkikoodissa Harrastus-luokka on toteutettu näin. Ylläpidettävämmin tehtynä toteutus voi perustua taulukoihin polymorfisista kenttätyypeistä. Tästä on esimerkki Jasen-luokan toteutuksessa. Esimerkistä on yhteinen kantaluokka jonka Jasen ja Harrastus perivät. Nyt ihannetilanteessa päästään siihen, että jos jäsenen kenttien lukumäärää pitää muuttaa, tapahtuu tämä muutos vain Jasen-luokassa eikä mihinkään muualle (edes käyttöliittymään) tarvitse koskea koodissa.
Huom! Tästä eteenpäin selostus perustuu vanhaan Swing-versioon, mutta idea on sama.
16.3 Kerhon rakenne
Kerho-ohjelman rakenne voidaan jakaa karkeasti kolmeen osaan. Alimmalla tasolla toimivat käyttäjälle näkymättömät asiat, kuten tietorakenteet ja tiedon tallennus. Käyttäjä itse pääsee vaikuttamaan ainoastaan ylimpään kerrokseen, jossa on ohjelmoituna näkyvä käyttöliittymä ja otetaan esimerkiksi kiinni käyttäjän aiheuttamia tapahtumia. Näiden kahden kerroksen välissä toimii kontrolleri, joka sisältää käyttöliittymän tarvitsemaa toiminnallisuutta ja toimii välittäjänä kahden kerroksen välillä.
Ohjelmoinnin yhteydessä törmää usein ohjelmistoarkkitehtuurin käsitteeseen. Kerhollakin on paljon yhteistä MVC (Model-View-Controller)-arkkitehtuurista kehittyneen MVP (Model-View-Presenter)-mallin kanssa. Arkkitehtuurien tarkoituksena on jakaa ohjelma helposti hallittaviin osa-alueisiin, mutta usein niitä ei ole edes mielekästä noudattaa mitenkään kirjaimellisesti.
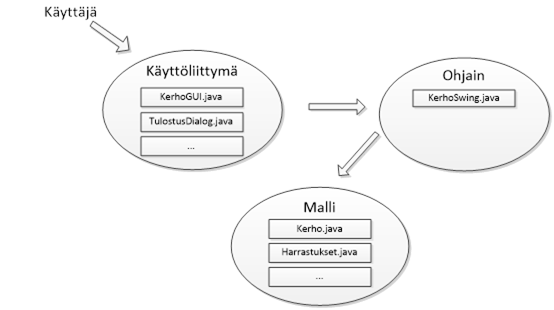
16.3.1 KerhoGUIController ja käyttöliittymän yhteistoiminta
Kerhossa on pyritty erottamaan suurin osa käyttöliittymän toiminnallisuuteen liittyvästä koodista erilliseen KerhoGUIController apuluokkaan.
Vastaan tulee tietysti tilanne, että KerhoSwing sisältää metodin, jolla halutaan päivittää jotain tiettyä käyttöliittymän komponenttia. Esimerkiksi kuvassa jäsenet sisältävä JList. Ensin Kerho-luokassa luodaan tarvittava komponentti ja esitellään se public final. KerhoSwing-luokassa komponenttia käytetään tyyliin:
// KerhoSwing.java - Harjoitustyö vaihe 7 - get ja set-metodit
public class KerhoSwing {
...
private KerhoGUI kerhoGUI;
...
private AbstractChooser<Jasen> getListJasenet() {
return kerhoGUI.listJasenet;
}
...
getListJasenet().addSelectionChangeListener( (e) -> naytaJasen() );
...
getListJasenet().clear();
...
getListJasenet().add(jasen.getNimi(),jasen);KerhoSwing on saanut viitteen KerhoGUI-luokkaan kun KerhoGUIon luonut KerhoSwing-luokan:
...
protected final KerhoSwing kerhoswing;
...
public KerhoGUI() {
kerhoswing = new KerhoSwing(this);
...16.4 Jäsenien selaaminen
Jäsenien käsittelyä helpottamaan tehdään ohjelman vasempaan laitaan jäsenlistaus. Käyttäjiä voidaan myös suodattaa halutun hakuehdon perusteella.
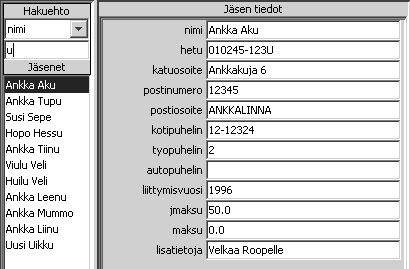
16.5 Jäsenkenttien lisääminen
Tehtyyn .fxml-tiedostoon lisättiin suunnitteluvaiheessa kenttien otsikot käsin. Nyt kuitenkin otsikot ovat jo Jasen-olion tiedossa ja samaa ohjelmakoodia joudutaan kirjoittamaan useaan paikkaan. Kannattavampaa on tehdä toteutus, jossa kentät haetaan suoraan oliolta. Tällöin helpottuu paitsi muutosten tekeminen ohjelmaan, myös ohjelman siirto toisiin järjestelmiin. Samasta syystä kannattaa olion tehtäväksi antaa myös oikeellisuustarkistukset.
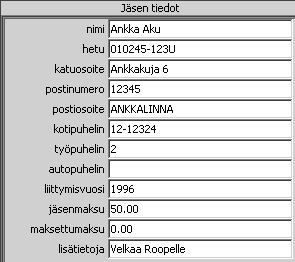
Täydelliset esimerkit osoitteissa
Jasen-luokasta löytyy kentät taulukko, johon voidaan tallentaa Kentta-rajapinnan toteuttavia olioita.
// jasen.java - Harjoitustyö vaihe 7
…
private Kentta kentat[] = { // valitettavasti ei voi olla final vaikka pitäisi, clone estää tämän :-(
new IntKentta("id"),
new JonoKentta("nimi"),
new HetuKentta("hetu",new HetuTarkistus()),
new JonoKentta("katuosoite"),
new JonoKentta("postinumero",
new SisaltaaTarkistaja(SisaltaaTarkistaja.NUMEROT)),
new JonoKentta("postiosoite"),
new PuhelinKentta("kotipuhelin"),
new PuhelinKentta("työpuhelin"),
new PuhelinKentta("autopuhelin"),
new IntKentta("liittymisvuosi"),
new RahaKentta("jäsenmaksu"),
new RahaKentta("maksettumaksu"),
new JonoKentta("lisätietoja")
};
…Rajapinnalla taataan, että käyttöliittymästä saa selville ja pystyy asettamaan oliolle kenttään liittyviä tietoja.
// Kentta.java - Harjoitustyö vaihe 7
public interface Kentta extends Cloneable {
/**
* kentän arvo merkkijonona.
* @return kenttä merkkkijonona
*/
String toString();
/**
* Palauttaa kenttään liittyvän kysymyksen.
* @return kenttään liittyvä kysymys.
*/
String getKysymys();
/**
* Asettaa kentän sisällön ottamalla tiedot
* merkkijonosta.
* @param jono jono josta tiedot otetaan.
* @return null jos sisältö on hyvä, muuten merkkijonona virhetieto
*/
String aseta(String jono);
/**
* Palauttaa kentän tiedot veratiltavana merkkijonona
* @return vertailtava merkkijono kentästä
*/
String getAvain();
Kentta clone() throws CloneNotSupportedException ;
}Mitä oikeastaan halutaan tallentaa? Osa kentistä on selkeitä merkkijonoja ilman täsmällisesti määriteltyjä muotoja (nimi, osoite, postiosoite…). Toisaalta löytyy myös kokonaislukuja, desimaalilukuja, puhelinnumeroita ja henkilötunnus. Jokaista luokkaa ei tietenkään kannata kirjoittaa alusta asti toteuttamaan rajapintaa, vaan ensin luodaan kaikille yhteinen kantaluokka. Nyt kentillä ei kuitenkaan ole mitään selkeää vanhempaa, joka toteuttaisi kaikki rajapinnan metodit, vaikka osa niistä onkin jo toteutettavissa.
Java tarjoaa rajapinnan ja luokan välimaastoon rakenteen nimeltä abstrakti luokka (abstract class). Se on luokka josta ei voi suoraan luoda instanssia, mutta johon on mahdollista ohjelmoida periville luokille valmiiksi osa toiminnallisuutta ja metodeita. Perivä luokka myös laajentaa (extends) abstraktin luokan, eikä toteuta (implements). Suurimpana erona on, että luokka voi toteuttaa useita rajapintoja, mutta ei periä. Tästä syystä abstraktia luokkaa ei tule pitää vaihtoehtona rajapinnalle.
// PerusKentta.java - Harjoitustyö vaihe 7
/**
* Peruskenttä joka implementoi kysymyksen käsittelyn
* ja tarkistajan käsittelyn.
*
* @author Vesa Lappalainen
* @version 1.0, 22.02.2003
* @version 1.3, 02.04.2003
*/
public abstract class PerusKentta implements Kentta {
private final String kysymys;
/**
* Yleisen tarkistajan viite
*/
protected Tarkistaja tarkistaja = null;
/**
* Alustetaan kenttä kysymyksen tiedoilla.
* @param kysymys joka esitetään kenttää kysyttäessä.
*/
public PerusKentta(String kysymys) { this.kysymys = kysymys; }
/**
* Alustetaan kysymyksellä ja tarkistajalla.
* @param kysymys joka esitetään kenttää kysyttäessä.
* @param tarkistaja tarkistajaluokka joka tarkistaa syötän oikeellisuuden
*/
public PerusKentta(String kysymys,Tarkistaja tarkistaja) {
this.kysymys = kysymys;
this.tarkistaja = tarkistaja;
}
/**
* @return kentän arvo merkkijonona
* @see kanta.Kentta#toString()
*/
@Override
public abstract String toString();
/**
* @return Kenttää vastaava kysymys
* @see kanta.Kentta#getKysymys()
*/
@Override
public String getKysymys() {
return kysymys;
}
/**
* @param jono josta otetaan kentän arvo
* @see kanta.Kentta#aseta(java.lang.String)
*/
@Override
public abstract String aseta(String jono);
/**
* Palauttaa kentän tiedot vertailtavana merkkijonona
* @return vertailtava merkkijono kentästä
*/
@Override
public String getAvain() {
return toString().toUpperCase();
}
/**
* @return syväkopio oliosta
*/
@Override
public Kentta clone() throws CloneNotSupportedException {
return (Kentta)super.clone();
}
}Luokkaan jätettiin vielä abstraktit metodit toString ja aseta, joten periviin luokkiin tulee kirjoittaa vähintään ne.
Tässä esiteltiin myös viite yleiselle Tarkistaja-rajapinnan toteuttavalle oliolle. Kerho käyttää tarkistajia kenttiin syötetyn tiedon validointiin, mutta tavallinen PerusKentta ei tietenkään voi vielä edes hyödyntää tällaista toiminnallisuutta, vaan mielekäs tapa siihen on jonkun perivän kentän aseta-metodissa.
Nyt voidaan lähteä toteuttamaan kenttien olioita. Helpoin tapaus on vapaamuotoinen merkkijono, johon käyttäjä saa tallentaa mitä merkkejä vain, mutta johon on kuitenkin mahdollista liittää erillinen Tarkistaja syötteen muodon validointia varten.
// JonoKentta.java - Harjoitustyö vaihe 7
/**
* Kenttä tavallisia merkkijonoja varten.
* @author Vesa Lappalainen
* @version 31.3.2008
*
*/
public class JonoKentta extends PerusKentta {
private String jono = "";
/**
* Alustetaan kenttä kysymyksen tiedoilla.
* @param kysymys joka esitetään kenttää kysyttäessä.
* @example
* <pre name="test">
* JonoKentta jono = new JonoKentta("nimi");
* jono.getKysymys() === "nimi";
* jono.toString() === "";
* jono.aseta("Aku");
* jono.toString() === "Aku";
* </pre>
*/
public JonoKentta(String kysymys) { super(kysymys); }
/**
* Alustetaan kysymyksellä ja tarkistajalla.
* @param kysymys joka esitetään kenttää kysyttäessä.
* @param tarkistaja tarkistajaluokka joka tarkistaa syötön oikeellisuuden
*/
public JonoKentta(String kysymys,Tarkistaja tarkistaja) {
super(kysymys,tarkistaja);
}
/**
* @return Palautetaan kentän sisältö
* @see kanta.PerusKentta#toString()
*/
@Override
public String toString() { return jono; }
/**
* @param s merkkijono joka asetetaan kentän arvoksi
* @see kanta.PerusKentta#aseta(java.lang.String)
*/
@Override
public String aseta(String s) {
if ( tarkistaja == null ) {
this.jono = s;
return null;
}
String virhe = tarkistaja.tarkista(s);
if ( virhe == null ) {
this.jono = s;
return null;
}
return virhe;
}
}Ohjelman rakenne menee jo jokseenkin monimutkaiseksi. Kuitenkin tilanne, jossa toiminnallisuus on sotkettu käyttöliittymään ja luokilla ei ole selkeitä vastuualueita, johtaa ennen pitkää ylläpitokelvottomaan koodiin. Tässä luokilla on selkeät vastuualueet, joten myös bugien paikallistaminen on helpompaa.
16.6 Oikeellisuustarkistukset
Oikeellisuustarkistukset voi hoitaa monellakin tapaa. Usein helpointa on käyttää säännöllisiä lausekkeita, mutta esimerkiksi Kerhossakin tarvittavan henkilötunnukset tarkistaminen ei niillä suoraan onnistu. Kerhossa on käytetty myös Tarkistaja-rajapinnan toteuttavia luokkia, joihin voi helpommin ohjelmoida monimutkaisempaakin toiminnallisuutta. Syötteiden validointi on varsin suoraviivaista työtä, jossa käytännössä tarvitaan vain käyttäjän antama merkkijono ja tulos. Määritellään yksinkertainen, mutta täsmällinen toiminnallisuus sen toteuttaville luokille.
// Tarkistaja.java - Harjoitustyö vaihe 7
/**
* Rajapinta yleiselle tarkistajalle.
* Tarkistajan tehtävä on tutkia onko annettu
* merkkijono kelvollinen kentän sisällöksi ja jos on,
* palautetaan null.
* Virhetapauksessa palautetaan virhettä mahdollisimman
* hyvin kuvaava merkkijono.
* @author Vesa Lappalainen @version 31.3.2008
*/
public interface Tarkistaja {
/**
* Tutkitaan käykö annettu merkkijono kentän sisällöksi.
* @param jono tutkittava merkkijono
* @return null jos jono oikein, muuten virheilmoitusta vastaava merkkijono
*/
String tarkista(String jono);
}Tehtävä 15.1 Henkilötunnuksen tarkistaminen
Henkilötunnuksen muoto ja laskeminen noudattavat tarkkoja määrittelyjä. Tutustu aiheeseen esimerkiksi Wikipediasta ja katso Kerho-ohjelmassa Tarkista-rajapinnan toteuttava ratkaisu HetuKentta.java.
16.6.1 Säännölliset lausekkeet
Tehokas työkalu syötteiden tarkastamiseen on säännölliset lausekkeet (regular expressions, regex). Tietojenkäsittelytieteessä niitä on hyödynnetty jo yli 50 vuotta, eli tässäpä opeteltavaksi tekniikka, joka tuskin on heti vanhentumassa. Säännöllisen lausekkeen idea on määritellä lauseke, jota merkkijono joka vastaa tai ei vastaa.
Useimmissa suurissa ohjelmointikielissä on jo valmiina kirjastot säännöllisten lausekkeiden hyödyntämiseen. Eri toteutusten välillä on kuitenkin pieniä eroja, joten tarvittaessa kannattaa konsultoida manuaalia.
Javassa yksinkertaisimmillaan säännöllinen lauseke ab vastaa merkkijonoa ab, mutta ei kuitenkaan merkkijonoa abc. Taulukossa lauseketta vastaavat merkkijonot ovat korostettuna.
| regexp | merkkijono | Huomautus |
|---|---|---|
| ab | ab abc |
Perustapaus |
Koska säännölliset lausekkeet ovat oma merkkijonokielensä, niin ne sisältävät myös operaattoreita, joista tässä yleisimmät. Tavallisesti operaattoria verrataan edelliseen merkkiin.
| regexp | merkkijono | Huomautus |
|---|---|---|
| ab* | a ab abbb aab |
b esiintyy nollasta äärettömän monen kertaan |
| ab* | abc | Tähti ei kuitenkaan toimi jokerimerkkinä |
| ab+ | a ab abb |
toimii kuten tähti, mutta vaatii vähintään yhden esiintymän, eli täysin vastaava toiminnallisuuden saavuttaa myös lauseella abb* |
| ab? | a ab abb |
b kerran tai ei kertaakaan |
| a|b | a b ab |
a tai b |
| a|b* | ab bbb |
a tai b* |
| [ab] | a b ab |
a tai b |
| [ab]* | b abaaab |
Operaattoria sovelletaan kaikkiin kirjaimiin sulkujen sisälllä |
| ba. | bab babc |
Piste korvaa minkä tahansa kirjaimen |
Sulkujen avulla voi luoda lauseen sisälle pienempiä lausekkeita, joita käsitellään omina kokonaisuuksinaan ja joihin sovelletaan operaattoreita sellaisenaan.
| regexp | merkkijono | Huomautus |
|---|---|---|
| (ab)+c | a ab ac abc abbc abababc |
ab vähintään kerran ja c |
Jos tarkastetaan varattua merkkiä (operaattorit), tai "-merkkiä, niin käytetään niiden edessä kenoviivaa , sekä kenoviivaa tarkastaessa toista kenoviivaa.
16.6.2 Säännöllisten lausekkeiden käyttäminen
Javan merkkijonoluokka sisältää useita metodeita, jotka hyödyntävät suoraan säännöllisiä lausekkeita. Näin tehdään myös Kerhon puhelinnumeroita käsittelevässä luokassa.
//PuhelinKentta.java - Harjoitustyö vaihe 7
…
@Override
public String aseta(String jono) {
if ( !jono.matches("[0-9\\-\\+ ]*")) return "Sallitaan vain merkit 0-9 - + ";
return super.aseta(jono);
}
}Metodi tarkastaa, ettei käyttäjän syöttämästä jonosta löydy muita merkkejä, tai muuten palautetaan virheilmoitus. Mikäli merkkijonosta "[0-9-+ ]" riisutaan kaikki Java, niin saadaan pelkistetympi muoto [0-9-+ ], eli merkkijonossa saa olla mitä tahansa * sulkeiden []sisällä olevia merkkejä 0-9, -, +, tai välilyönti. Viivalla ilmaistaan väliä käytetyssä merkistössä, koska merkit 0, 1…9 sijaitsevat peräkkäin, niin voidaan hyväksyä väli, missä sijaitsevat kaikki numerot. Erilaisille merkkiryhmille on myös useita vaihtoehtoisia ilmauksia, kuten kokonaisluille löytyvä d.
Tehtävä 15.2 Merkistövälit
[0-9] katsoi että kirjoitettu merkki asettui tietylle välille käytetyssä merkistössä. Voiko samaa tekniikkaa soveltaa aakkosille?
Tehtävä 15.3 Säännöllisten lausekkeiden käyttäminen
Avaa näitä tehtäviä varten myös Javan säännöllisten lausekkeiden API
http://download.oracle.com/javase/8/docs/api/java/util/regex/Pattern.html
- Kirjoita säännöllinen lauseke, joka täsmää lukuun, joka on kirjoitettu maksimissaan kahden desimaalin tarkkuudella. Erottimeksi kelpaa sekä pilkku, että piste.
- Mitä ongelmia päivämäärän tarkastamiseen liittyy? Miten päivämäärän kysyminen käyttäjältä kannattaa toteuttaa?
16.7 Kentät graafiseen käyttöliittymään
Kuten jo aiemmin todettiin, niin jäsenkentät kannattaa hakea ohjelman suoritusvaiheessa suoraan jäseneltä.
/**
* Luodaan GridPaneen jäsenen tiedot
* @param gridJasen mihin tiedot luodaan
* @return luodut tekstikentät
*/
public static TextField[] luoKentat(GridPane gridJasen) {
gridJasen.getChildren().clear();
TextField[] edits = new TextField[apujasen.getKenttia()];
for (int i=0, k = apujasen.ekaKentta(); k < apujasen.getKenttia(); k++, i++) {
Label label = new Label(apujasen.getKysymys(k));
gridJasen.add(label, 0, i);
TextField edit = new TextField();
edits[k] = edit;
edit.setId("e"+k);
gridJasen.add(edit, 1, i);
}
return edits;
}
Ensin ohjelman pitää tietää montako TextField-komponenttia tullaan tarvitsemaan. Tässä tapauksessa lukumäärä saataisiin apujasen-oliolta.
int n = apujasen.getKenttia() - apujasen.ekaKentta();Indeksoinnin helpottamiseksi kenttiä on kuitenkin luotu "liikaa", jolloin jokainen on omassa indeksissään ja alkupään kentät jäävät null-arvoon.
Tiedot sisältävässä paneelissa saattaa olla suunnitteluvaiheessa tehtyjä mallidataa sisältäviä komponentteja. Ne on hyvä jättää havainnollistuksen vuoksi paikalleen suunnitelmaan, mutta ohjelman ajon ajaksi ne pitää poistaa. Tämä onnistuu pyytämällä panelia poistamaan kaikki sen päällä olevat komponentit. Tällöin on tärkeää että tämän panelin päällä ei ole muita komponentteja kuin jäsenen tietoja.
gridJasen.getChildren().clear();Silmukassa laitetaan kenttien kysymykset ja nimet EditPanel-komponentteihin, sekä asetetaan ne näkyviksi. Lisäksi jokaiselle kentälle on luotava vielä oma tapahtumakuuntelija.
for (TextField edit : edits)
if ( edit != null )
edit.setOnKeyReleased( e -> kasitteleMuutosJaseneen((TextField)(e.getSource())));Osa suunniteltua toiminnallisuutta oli tarkastaa, että onko syötetty tieto oikeassa muodossa ja antaa tarvittaessa käyttäjälle virheilmoitus.
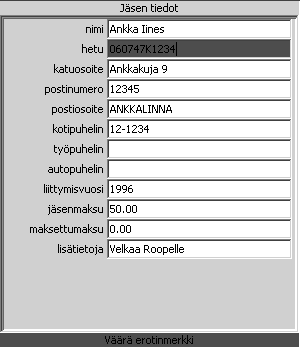
Kun käyttöliittymästä tehdään muutos kenttään, niin tullaan kasitteleMuutosJaseneen-metodiin. Aluksi tarkastetaan onko jäsentä jo editoitu, jos ei, niin siitä luodaan muokattava kopio editJasen-olioon.
Seuraavaksi haetaan parametrina tuotuun TextField-kenttään kirjoitettu teksti ja selvitetään mikä kentistä on kyseessä. Nyt Jasen-olioon voidaan yrittää asettaa muuttunut data. Mikäli asetus onnistuu, niin palautuu tyhjä viite. Toisaalta jos palautui virheilmoituksen sisältävä merkkijono, niin se voidaan suoraan asettaa näkymään punaiselle taustalle käyttöliittymään.
protected void kasitteleMuutosJaseneen(TextField edit) {
if (jasenKohdalla == null) return;
int k = getFieldId(edit,apujasen.ekaKentta());
String s = edit.getText();
String virhe = null;
virhe = jasenKohdalla.aseta(k,s);
if (virhe == null) {
Dialogs.setToolTipText(edit,"");
edit.getStyleClass().removeAll("virhe");
naytaVirhe(virhe);
} else {
Dialogs.setToolTipText(edit,virhe);
edit.getStyleClass().add("virhe");
naytaVirhe(virhe);
}
}16.8 Etsiminen
Kun käyttöliittymä tarvitsee tiettyä osajoukkoa jäsenistä, kannattaa Jasenet-luokan palauttaa tietorakenteen, johon on kerätty viitteet hakuehdon täyttävistä jäsenistä:
public Collection<Jasen> etsi(String hakuehto, int k) {
List<Jasen> loytyneet = new ArrayList<Jasen>();
for (Jasen jasen : this) {
if (WildChars.onkoSamat(jasen.anna(k), hakuehto)) loytyneet.add(jasen);
}
Collections.sort(loytyneet, new Jasen.Vertailija(k));
return loytyneet;
}16.9 Lajittelu avaimen kentän mukaan
Lajittelussa ongelmaksi tulee se, että eri kenttiä vertaillaan eri tavoilla. Esimerkiksi suomen henkilötunnus merkkijonona
010245-123U
121237-121Vei anna oikeata ikäjärjestystä jos tuo laitetaan aakkosjärjestyksen mukaiseen järjestykseen. Siksi tehdään Jasen-luokkaan Vertailija-luokka, jossa on toteutus metodille compare, jonka tehtävä on verrata kahta alkiota keskenään ja palauttaa negatiivinen, nolla tai positiivinen luku sen mukaan, miten verrattavat alkiot suhtautuvat toisiinsa (kuvitteellisesti vähennyslaskun j1-j2 tulos):
public static class Vertailija implements Comparator<Jasen> {
private final int kenttanro;
public Vertailija(int k) {
this.kenttanro = k;
}
@Override
public int compare(Jasen j1, Jasen j2) {
String s1 = j1.getAvain(kenttanro);
String s2 = j2.getAvain(kenttanro);
return s1.compareTo(s2);
}
}Vastaavasti jäsenen metodi getAvain palauttaa vastaavan kentän avain-arvon:
return kentat[k].getAvain();Kukin kenttä voi nyt toteuttaa tuon metodin getAvain haluamallaan tavalla. Esimerkiksi hetun tapauksessa metodi voisi järjestää hetun osat uuteen järjestykseen (kuten ruotsalaisilla on valmiiksi), joka toimii myös aakkosjärjestyksessä:
371212-121V
450102-123UTosin tarkemmin tehtynä myös välimerkin vuosisata pitää ottaa oikein huomioon. Numeerisen kentän tapauksessa merkkijonona on sama ongelma.
123
22
5ei toimi aakkosjärjestyksessä, mutta kun numerot muutetaan sopivaan merkkijonomuotoon, esimerkiksi
0000005
0000022
0000123niin merkkijonoksi muutettu aakkostaminen toimii.
Hieman ehkä parempikin toiminnallisuus saataisiin, jos vertailuvastuu olisi siirretty suoraan kunkin kentän vastuulle.
16.10 Tulostaminen
Paperille tulostaminen kannattaa nykyisin hoitaa joko niin, että tuotetaan esim. HTML-koodia, jota taas vaikka mikä ohjelma (yleensä selaimet) osaa tulostaa. Tästä oli esimerkki luvussa Jäsenten tulostaminen.
Muita mahdollisuuksia on tuottaa jonkun tekstinkäsittelyohjelman tai taitto-ohjelman muotoa, esim. LaTeX-koodia, josta tuotetaan siisti PDF.
Microsoft-pohjaisissa järjestelmissä tulostamisvastuu voidaan antaa myös Word-ohjelmalle ja muissa järjestelmissä vastaavalle tekstinkäsittelyohjelmalle. Esimerkiksi Word on erittäin hyvin ohjelmoitavissa kommunikoimaan toisten ohjelmien kanssa. Ajojonoilla ja makroilla myös LibreOffice (entinen OpenOffice) saadaan taipumaan yhteistyöhön ilman että käyttäjän tarvitsee tietää käyttävänsä ko. ohjelmaa.